


April 26, 2012
Six Super-Scale Hadoop Deployments
Last week we reported on the estimate that by 2015 over half of the world’s data will touch Hadoop—a striking figure that has echoed loudly in the expanding ecosystem around the open source platform.
 However, some say that while Hadoop is the top buzzword in the noisy big data realm, it’s certainly not a magic bullet that can cure all datacenter and data management woes. With this in mind, we wanted to cast aside our own speculation about the future of this and open source technologies reshaping data-intensive problem-solving of all kinds and zero in on the use cases that are helping the hype.
However, some say that while Hadoop is the top buzzword in the noisy big data realm, it’s certainly not a magic bullet that can cure all datacenter and data management woes. With this in mind, we wanted to cast aside our own speculation about the future of this and open source technologies reshaping data-intensive problem-solving of all kinds and zero in on the use cases that are helping the hype.
There is no doubt that there are some outstanding examples of how Hadoop and related open source technologies (Hive, HBase, etc.) are reshaping how webscale businesses think about their infrastructure.
While we’ll continue focusing on the cases when Hadoop isn’t the answer in a series of articles timed with this year’s approaching Hadoop World even, let’s shine the light on some dramatic, large-scale Hadoop deployments that are reshaping big data-dependent companies in social media, travel, and general goods and services.
Let’s dive in, starting with a company that you first started hearing about during the advent of ecommerce.
START — Case #1: Hadoop & the Highest Bidder >>>
The Hadoop Environment at eBay
Anil Madan from eBay’s Analytics Platform Development team discussed how the auction giant is taking advantage of the Hadoop platform to leverage the 8 to 10 terabytes of data that flood in each day.
 While eBay’s journey into a production Hadoop environment only began a couple of years ago, they were among the first large-scale web companies to begin experimenting with Hadoop back in 2007, where they used a small cluster to work with machine learning and search relevance problems.
While eBay’s journey into a production Hadoop environment only began a couple of years ago, they were among the first large-scale web companies to begin experimenting with Hadoop back in 2007, where they used a small cluster to work with machine learning and search relevance problems.
These were with small subsets of data, which Madan says was useful for experimental purposes, but as data and user activity continued to grow, they wanted to make use of data across several departments and at the entire user base level.
Their first large Hadoop cluster, 500-node Athena, was purpose built as a production platform to suit the needs of several departments within eBay. Built in just under three months , he says it began crunching predictive models to solve real-time problems and has since extended to meet other needs.

Madan says that the cluster is used by many teams within eBay, for production as well as one-time jobs. The team uses Hadoop’s Fair Scheduler to manage allocations, define job pools for teams, assign weights, limit concurrent jobs per user and team, set preemption timeouts and delayed scheduling.
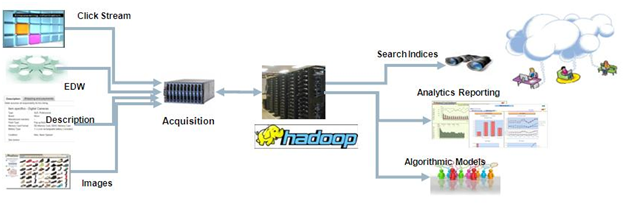
While he often speaks at events about the production value of Hadoop, Madan was quick to identify some of the key challenges the team addresses and continues to working on as they build out eBay infrastructure. As a revealed in a list of Hadoop-related challenges:
- Scalability
In its current incarnation, the master server NameNode has scalability issues. As the file system of the cluster grows, so does the memory footprint as it keeps the entire metadata in memory. For 1 PB of storage approximately 1 GB of memory is needed. Possible solutions are hierarchical namespace partitioning or leveraging Zookeeper in conjunction with HBase for metadata management.
- Availability
NameNode’s availability is critical for production workloads. The open source community is working on several cold, warm, and hot standby options like Checkpoint and Backup nodes; Avatar nodes switching avatar from the Secondary NameNode; journal metadata replication techniques. We are evaluating these to build our production clusters.
- Data Discovery
Support data stewardship, discovery, and schema management on top of a system which inherently does not support structure. A new project is proposing to combine Hive’s metadata store and Owl into a new system, called Howl. Our effort is to tie this into our analytics platform so that our users can easily discover data across the different data systems.
- Data Movement
We are working on publish/subscription data movement tools to support data copy and reconciliation across our different subsystems like the Data Warehouse and HDFS.
- Policies
Enable good Retention, Archival, and Backup policies with storage capacity management through quotas (the current Hadoop quotas need some work). We are working on defining these across our different clusters based on the workload and the characteristics of the clusters.
- Metrics, Metrics, Metrics
We are building robust tools which generate metrics for data sourcing, consumption, budgeting, and utilization. The existing metrics exposed by some of the Hadoop enterprise servers are either not enough, or transient which make patterns of cluster usage hard to see.
NEXT – Case #2: Sentiment Analysis at Scale…>>>
GE Taps Sentiment at Scale with Hadoop…
 According to Linden Hillenbrand, Product Manager for Hadoop Technologies at General Electric (GE), sentiment analysis is tough—it’s not just a technical challenge, it’s also a business challenge.
According to Linden Hillenbrand, Product Manager for Hadoop Technologies at General Electric (GE), sentiment analysis is tough—it’s not just a technical challenge, it’s also a business challenge.
At GE, the Digital Media and Hadoop teams joined forces to build an interactive application for marketing functions that hinged on advanced sentiment analysis.
The goal was to give the marketing teams the ability to assess external perception of GE (positive, neutral, or negative) through our various campaigns. Hadoop powers the sentiment analysis aspect of the application as a highly intensive text mining use case for Hadoop.
He claims that leveraging Hadoop to manage these challenges on the technical side has led to vast improvements.
To drive this home, Hullenbrand cites their unique NoSQL approach to sentiment analysis as producing an 80% accuracy rate and the basis of the core platform for future GE data mining growth. As the graphic below highlights, there are significant improvements over how data mining used to be handled at GE and how the new platform could enable a new class of insight.
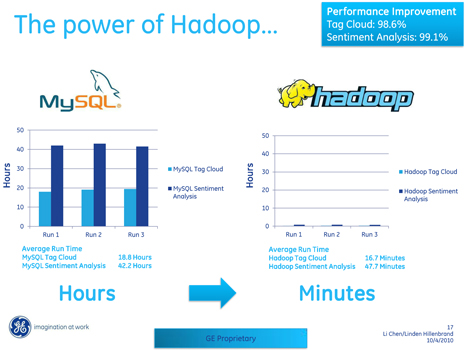
Hilenbrand says that in terms of GE’s outlook for the future of Hadoop internally, the sentiment analysis project was a double success. Not only did it deliver better results for the marketing team behind the Fortune 50 company, it set the stage for the company’s next generation of deep data mining, analytics and visualization projects.
NEXT — Case #3: Travel’s “Poster Child”
Travel’s Poster Child Use Case
Orbitz Worldwide’s portfolio of global consumer travel brands processes millions of searches and transactions every day.
 Storing and processing the ever-growing volumes of data generated by this activity becomes increasingly difficult through traditional systems such as relational databases, thus the company has turned to Hadoop to help manage some of the complexity.
Storing and processing the ever-growing volumes of data generated by this activity becomes increasingly difficult through traditional systems such as relational databases, thus the company has turned to Hadoop to help manage some of the complexity.
Jonathan Seidman, The company’s Lead Software Engineer, Jonathan Seidman and engineer Ramesh Venkataramiah have been open about discussing how the travel site’s infrastructure is managed. In a recent talk that they delivered for multiple audiences, the two discuss the role of Hive for some critical search functions, in particular.
Hadoop and Hive help the online travel hub do everything from improve the ability to allow quick hotel filtering and sorting and to examine larger internal trends. Their big data problems make them a “poster child” for Hadoop according to the Orbit data duo, who say that there is nothing simple about handling these millions of daily searches and transactions across their scattered network of services that create daily log sizes in the many hundreds of gigabytes per day.
In the slideshow above, the two demonstrate how Hadoop and Hive are being used to process the data—and perhaps more important, what made their particular problems a perfect fit for Hadoop (sice it bears reminding that not all business would ever even have a use for it).
NEXT — #4: Updating Hadoop’s Status…>>>
Updating Hadoop’s Status
While some companies and agencies have enormous systems under wraps, in terms of what is known to exist, the Datawarehouse Hadoop cluster at Facebook has become the largest known Hadoop storage cluster in the world.
 Here are some of the details about this single HDFS cluster:
Here are some of the details about this single HDFS cluster:
- 21 PB of storage in a single HDFS cluster
- 2000 machines
- 12 TB per machine (a few machines have 24 TB each)
- 1200 machines with 8 cores each + 800 machines with 16 cores each
- 32 GB of RAM per machine
- 15 map-reduce tasks per machine
That’s a total of more than 21 PB of configured storage capacity, larger than the previously known Yahoo!’s cluster of 14 PB. In the early days of Hadoop, well before the stuffed elephant’s merry face was plastered all over anything big data-focused, Facebook, among a few other web giants, was making use of the framework to manage its expanding operations.
With over 400 million active monthly users, well in the 500+ billion pageview arena, and with 25 billion pieces of content shared each month, Facebook is the best use case for any technology touting itself as capable of handling web-scale problems.
Facebook engineers work closely with the Hadoop engineering team at Yahoo! to push Hadoop to greater scalability and performance. Facebook has many Hadoop clusters, the largest among them is the one that is used for Datawarehousing. Here are some statistics that describe a few characteristics of the Facebook’s Datawarehousing Hadoop cluster:
- 12 TB of compressed data added per day
- 800 TB of compressed data scanned per day
- 25,000 map-reduce jobs per day
- 65 millions files in HDFS
- 30,000 simultaneous clients to the HDFS NameNode
Jonathan Gray, software engineer with Facebook and open source advocate demonstrated how Facebook has been using one component of the larger Hadoop block, HBase, to power both online and offline applications in production environments.
While the slideshow above is a bit dense and specific, it gives a sense of the complex data environment HBase has been fit into—but more important, how the environment requires some significant tweaking and expertise to manage. HBase is just one of the ways that Facebook is managing massive amounts of data to provide exceptionally smart services for users.
NEXT – #5: The Millionfold Mashups…>>>
Infochimps Tackle the Millionfold Mashups
Ask Phillip “Flip” Kromer, where to find just about any list, spreadsheet or dataset and he’ll gladly point you to his company, InfoChimps, which touts itself as “the world’s data warehouse.”
 Many thousands hit the site up in search each month on a quest for specific data. Most recently the site’s users are looking for Twitter and social network data. It’s more traditional base of data includes other hot items like financial, sport and stock data.
Many thousands hit the site up in search each month on a quest for specific data. Most recently the site’s users are looking for Twitter and social network data. It’s more traditional base of data includes other hot items like financial, sport and stock data.
Sure, users could find these datasets elsewhere but they often come to InfoChimps, not necessarily because there’s a shortage or its hard to obtain, says Kromer, but because it’s been prohibitively expensive or in formats that are suitable for using—at least for the developer customer set Infochimps caters to.
The company is assembling a data repository containing thousands of public and commercial datasets, many at terabyte scale. Modern machine learning algorithms can provide insight into data by drawing only on its generic structure, even more so when that data is organically embedded in a sea of linked datasets. All of these ambitions, of course, create a complicated data environment and necessitate a platform that can work across multiple objectives, both internally (data collection and management-wise) and for users of the platform.
Infochimps lets users make use of their data with infrastructure that leverages Hadoop and both Amazon and Rackspace clouds. As you see below, the company takes advantage of elastic Hadoop and leverages both AWS and Rackspace while on the backend leveraging Hadoop for its own needs.

The company lets users get Hadoop resources when they need them, whether scheduled, ad-hoc, or dedicated. This breadth in capability enables nightly batch jobs, compliance or testing clusters, science systems, and production systems. With the newest addition to their Hadoop-fueled capabilities, Ironfan, Infochimps’ automated systems provisioning tool, as its foundation, Elastic Hadoop lets users tune the resources specifically for the job at hand. They claim that this simplifies a process of mapping or reducing specialized machines, high compute machines, high memory machines, etc. as needed.
NEXT — #6 Boosting Military Intelligence >>>
Hadoop’s Role in Mining Military Intelligence
Digital Reasoning claims to lead the way in “automated understanding for big data” for one of their core markets—the United States government.
 According to the company’s CEO and founders, Digital Reasoning was founded with the idea that software should be intelligent enough to both read and understand text as humans do.
According to the company’s CEO and founders, Digital Reasoning was founded with the idea that software should be intelligent enough to both read and understand text as humans do.
Digital Reasoning put their work toward this goal during a recent effort to comb through vast amounts of unstructured textual data from U.S. intelligence agencies to look for potential threats to national security. This purpose-built software for entity-oriented analytics became the core of the Synthesys technology at the root of their business.
The company uses Cloudera’s distribution along with support of HBase, the open-source, distributed, column-oriented store in its Synthesys platform. According to Digital Reasoning, “this integration allows us to achieve extreme scale capabilities and provide complex data analytics to government and commercial markets.”
In the following slideshow, the company’s CEO, Tim Estes, puts the company’s infrastructure and this use case in context:
“Cloudera and its team of Hadoop experts have worked closely with us to break new ground in complex analytics. Together, Cloudera and Digital Reasoning deliver identification and linking of entities on extremely large and diverse data sets for the most demanding customers ,” said Tim Estes, CEO of Digital Reasoning.
He went on to say how previously, only silos of “key intelligence data could be analyzed in isolation, but with Synthesys’ integration of Cloudera’s CDH3 and HBase support we can combine algorithms for our automated understanding with a platform that can handle scale and complexity to connect the dots in a way not possible before.”
Next — The Hadoop Use Primer…>>>
The Hadoop Backlog…
In our exploits covering news about big data analytics, we’re no strangers to presenting news about Hadoop and its companion technologies.
Since we’ve offered up some of the larger use cases, it seemed necessary to step back and give a broader picture of the news and use trends over the last 6 months through the following catch-up reads:
Inside LinkedIn’s Expanding Data Universe
This week we spent some time with LinkedIn team lead, data scientist and economist, Scott Nicholson to get a sense of what possibilities the big data of 150 million users present. We were able to get behind the scenes of the infrastructure and diverse stack (it’s more than just Hadoop), and to tap into some visualizations that would make even a seasoned economist…
Six Big Name Schools with Big Data Programs
Hadoop and related technologies are central facets in many of the listings. We whittled down the small but growing list of “big name” universities that are helping to solve the big data technologies talent gap. From degrees in data science to more specific certification programs for current IT professionals, these six schools….
Hadoop Hits Primetime with Production Release
After six years of endless refinements among a set of big name users including Facebook, Yahoo and others, the Apache Software Foundation announced this week that the first enterprise-ready version, dubbed 1.0, of Hadoop was ready to roll forward in production environments.
Hadoop Events Crowd 2012 Calendar
If this is indeed the “Year of Hadoop” then it stands to reason this should also be the year of Hadoop-flavored events. In true form, Hadoop conferences in 2012 are growing in number, as are user groups, training sessions and workshops to….
For the business angle, it’s been one heck of a six months for Hadoop and big tech as well….
SAS Extends Integration with Hadoop
SAS has announced that SAS Enterprise Data Integration Server users can make the Hadoop connection with the release of the newest update. Hadoop will join the ranks of other data source possibilities within their Data Integration Server…
Fujitsu Puts Proprietary Twist on Hadoop
Fujitsu has released a new twist on its ever-expanding big data theme. With the release of Interstage Big Data Parallel Processing Server V1.0 today, they claim the ability to simplify massive Hadoop deployments via the injection…
Latest Hadoop, Analytics Partnership Unfolds
In the wake of Cloudera’s recent announcement of an Oracle partnership, a new wave of Hadoop distribution vendors are finding established vendor partners to ally with. The big data marriage of this week, however, was formed between Teradata and….
Analyst Group Crowns Hadoop Distro King
Forrester Research recently reviewed the vast ecosystem that has developed around Apache Hadoop, this time pointing to the top vendors that are making their bread and butter by pitching their own supported distributions of the popular open source….
Another Brick in the Hadoop Wall
Announcements, especially from the business intelligence camp, about Hadoop support have rolled in steadily since mid-last year from vendors like Pentaho, Actuate, Tableau, Jaspersoft, SAS, and a host of others—all of whom…
Stay tuned for the next six months where we’ll find out if the dramatic deployment growth plays out.
Vendors:
Cloudera
Leading Solution Providers

















