


June 8, 2012
This Week’s Big Data Big Seven
While it seems like summer tends to bring about slower news cycles, this week the pace reversed course and ramped up with announcements from several key companies in enterprise big data, not to mention news filtering out from a few research institutions.
 Our top seven this week will look at how CSC is tapping big government data, will dive into the “Data Oasis” for big data and supercomputing, and look at new enhancements for those leveraging the R statistical language. We also have some news from HP and IBM and Oracle as they firm up their positions on big data.
Our top seven this week will look at how CSC is tapping big government data, will dive into the “Data Oasis” for big data and supercomputing, and look at new enhancements for those leveraging the R statistical language. We also have some news from HP and IBM and Oracle as they firm up their positions on big data.
Let’s dive in with the first item about how one software company is finding novel uses for big, open data…
CSC Taps Big Government Data
This week CSC announced that it is tapping large wells of data from NASA, NOAA and a host of other government agencies to create a software suite to help commodity traders, investment managers and financial analysts to put weather and atmospheric data to work for them.
While it may seem odd that weather data would play a big role in financial services, Dr. Sharon Jays who heads up science and engineering at CSC says, “These data sets, previously used primarily by a small group of climate research scientists, have tremendous applicability in the finance, agriculture and energy communities.” She goes on to note that the software, called ClimatEdge, “could benefit any private or public organization that has exposure to changes in energy and agricultural commodity prices.”
 CSC says the subscription-based services will cater to those who rely on short-range weather forecasts to manage risk over a span of one to two weeks. By mining “big data” sources of climate and Earth observations, the reports are uncovering unique relationships and creating predictive indices that provide additional insight into market behavior.
CSC says the subscription-based services will cater to those who rely on short-range weather forecasts to manage risk over a span of one to two weeks. By mining “big data” sources of climate and Earth observations, the reports are uncovering unique relationships and creating predictive indices that provide additional insight into market behavior.
As an example of the many areas reports present, the reports include agriculture details that present an overview of general weather and climate-related agriculture risks, including insights into areas where a drought, flood or other extreme weather event could impact crops
Among several other factors, the reports also provide an overview of the effect that extreme climate and weather events will have on energy demand and production. Other data in the energy sector includes monitoring extreme climate and weather events so risk managers can gauge the demand for natural gas, heating oil and crude.
NEXT – SDSC Basks in Data Oasis >>
SDSC Basks in Data Oasis
The San Diego Supercomputer Center (SDSC) at the University of California, San Diego has completed the deployment of its Lustre-based Data Oasis parallel file system, with four petabytes (PB) of capacity and 100 gigabytes per second (GB/s), to handle the data-intensive needs of the center’s new Gordon supercomputer in addition to its Trestles and Triton high-performance computer systems.
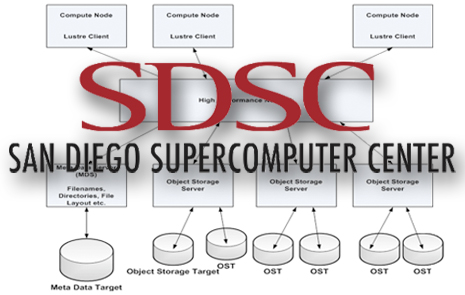
Using the I/O power of Gordon, Trestles, and Triton, sustained transfer rates of 100 GB/s have been measured, making Data Oasis one the fastest parallel file systems in the academic community. The sustained speeds mean researchers could retrieve or store 64 terabytes (TB) of data – the equivalent of Gordon’s entire DRAM memory – in about 10 minutes, significantly reducing research times needed for retrieving, analyzing, storing, or sharing extremely large datasets.
The sustained 100GB/s performance was driven by the requirement to have Data Oasis support the data-intensive computing power of Gordon, which went online earlier this year following a $20 million National Science Foundation (NSF) grant. The sustained connectivity speeds were confirmed during Gordon’s acceptance testing earlier this year. With recent deployments, Data Oasis now serves all three SDSC HPC systems.
According to Phil Papadopoulos, SDSC’s chief technical officer who is responsible for the center’s data storage systems. “The three major client clusters use different bridging technologies to connect to Data Oasis: Triton uses a Myrinet-to-10 gigabit ethernet (GbE) bridge (320 gigabits per second), Trestles uses an Infiniband-to-Ethernet bridge (240Gb/s), and Gordon uses its I/O nodes as Lustre routers for more than one terabit-per-second of network ‘pipe’ to storage.
Aeon Computing provided the 64 storage building blocks which constitute the system’s Object Storage Servers (OSS’s). Each of these is an I/O powerhouse in their own right. With dual-core Westmere processors, 36 high-speed SAS drives, and two dual-port 10GbE network cards, each OSS delivers sustained rates of over 2GB/s to remote clients. Data Oasis’ capacity and bandwidth are expandable with additional OSS’s, and at commodity pricing levels.
Data Oasis’ backbone network architecture uses a pair of large Arista 7508 10Gb/s Ethernet switches for dual-path reliability and performance. These form the extreme performance network hub of SDSC’s parallel, network file system, and cloud based storage with more than 450 active 10GbE connections, and capacity for 768 in total.
Whamcloud provided SDSC with consulting expertise in building SDSC’s Data Oasis Lustre environment, including hardware, networking, interfaces to various HPC systems, and software installation.
NEXT — Taking R to New Heights >>
Taking the R Language to the Next Level
Revolution Analytics, one of only a handful of companies that are capitalizing on the software, services and support market for users of the R statistical language, announced an upgrade to its R-based platform this week with version 6.0.

Revolution says that the new iteration of Revolution R Enterprise focuses on creating better performance and enterprise-readiness for statistical analysis of very large data sets. The company says that “R developers are now equipped with the robust tools required to meet the growing demands and requirements of modern data-driven businesses.
Using the built-in RevoScaleR package in Revolution R Enterprise, R users can process, visualize and model terabyte-class data sets in a fraction of the time of legacy products without special hardware. Key highlights of Revolution R Enterprise 6.0 include:
Platform LSF Cluster Support—Now supports distributed computing on multi-node Platform LSF grids. Support on Windows-based grids provided via Microsoft HPC Server.
Cloud-based Analytics with Azure Burst—Switch computations from a local Microsoft Windows HPC Server cluster to the Azure Cloud with a single command.
Big-Data Generalized Linear Models—Support big-data predictive models used in insurance, finance and biotech industries. Use a multi-node server or distributed grid for fast analytics on big data.
Direct Analysis of SAS, SPSS, ASCII and ODBC Data—Analyze proprietary data formats without the need for SAS/SPSS licenses.
Updated R 2.14.2 Engine—Improves performance and parallel programming capabilities. In addition, Revolution Analytics’ open-source RHadoop project (for Hadoop integration) is updated to work with this new engine.
“We’ve combined Revolution R Enterprise and Hadoop to build and deploy customized exploratory data analysis and GAM survival models for our marketing performance management and attribution platform,” said John Wallace, CEO of UpStream Software. “Given that our data sets are already in the terabytes and are growing rapidly, we depend on Revolution R Enterprise’s scalability and fast performance. We saw about a 4x performance improvement on 50 million records. It works brilliantly.”
NEXT — Viz Research Targets Disaster Management >>
Visualization Research Targets Disaster Management
Engineers and scientists at Rensselaer Polytechnic Institute are working to develop powerful new decision-making and data visualization tools for emergency management. These tools aim to help law enforcement, health officials, water and electric utilities, and others to collaboratively and effectively respond to disasters.

The new technology combines research in infrastructure systems, augmented reality and data visualization, and improvisation and decision making in unique disaster and emergency situations.
The prototype features a map of a disaster area projected onto the movie theater-sized screen, with overlays detailing the location of hospitals, power plants, temporary shelters, and many other key landmarks, infrastructure, and critical data. Due to the complexity and interconnectedness of these infrastructure systems and data, responding organizations must collaborate to be effective. The researchers’ new system enables emergency officials from different backgrounds and different agencies to interact with the data collaboratively and at the same time.
The researchers are also developing ways to use this kind of environment to better study decision making. For a variety of reasons, it is rare for researchers to have an opportunity to observe the work of emergency response managers and responding organizations during an actual disaster. So the new technology is able to simulate emergency situations using data from past disasters and other simulations techniques.
Funded by the Department of Homeland Security’s Coastal Hazards Center of Excellence, as well as a Seed Grant from the Office of the Vice President for Research at Rensselaer, this project is expected to advance basic knowledge of sources of resilience—or “bounce back”—in infrastructure systems, and to produce tools and technologies for leveraging these sources.
NEXT — IBM Tunes “Engines of Big Data” >>
IBM Tunes “Engines of Big Data”
This week IBM put another notch in its Smarter Computing belt by announcing several performance and efficiency enhancements to its storage and technical computing systems, which they have dubbed “the engines of big data.”
 Big Blue has laid out a strategic approach to designing and managing storage infrastructures with a focus on automation and intelligence, in addition to fine-tuning performance across several key storage systems and the Tivoli Storage Productivity Center suite.
Big Blue has laid out a strategic approach to designing and managing storage infrastructures with a focus on automation and intelligence, in addition to fine-tuning performance across several key storage systems and the Tivoli Storage Productivity Center suite.
As part of its Smarter Storage approach, IBM it is adding Real-time Compression to IBM Storwize V7000, as well as to the IBM System Storage SAN Volume Controller (SVC), the company’s industry-leading storage virtualization system. They’ve also added four-way clustering support for Storwize V7000 block systems that can double the maximum system capacity to 960 drives or 1.4 petabytes.
The company made performance tweaks to other storage offerings, including its DS3500, the SCS3700 and added new software to fine-tune performance on their Tape System Library Manager and their Linear Tape File System.
At the same time, the company announced its first offerings that incorporate software from IBM’s acquisition of Platform Computing earlier this year. These offerings are intended to help a broader set of enterprise customers use technical computing to achieve faster results with applications that require substantial computing resources to process growing volumes of data.
NEXT — HP Solidifies Big Data Approach >>
HP Solidifies Big Data Approach
HP remarked on the view that many organizations experiencing dramatic information growth are turning to Hadoop, an open-source-distributed data-processing technology, to meet their needs for storing and managing petabytes of information.
 With this in mind, the company announced its, HP AppSystem for Apache Hadoop, which they describe as an “enterprise-ready appliance that simplifies and speeds deployment while optimizing performance and analysis of extreme scale-out Hadoop workloads.” AppStack combines HP Converged Infrastructure, common management and advanced integration with Vertica 6 to target data processing and real-time analytics workloads.
With this in mind, the company announced its, HP AppSystem for Apache Hadoop, which they describe as an “enterprise-ready appliance that simplifies and speeds deployment while optimizing performance and analysis of extreme scale-out Hadoop workloads.” AppStack combines HP Converged Infrastructure, common management and advanced integration with Vertica 6 to target data processing and real-time analytics workloads.
To further firm up their position in the big data ecosystem, the company also announced a Big Data Strategy Workshop to help users align corporate IT and enterprise goals to identify critical success factors and methods for evolving their IT infrastructures to handle big data. They also rolled out the HP Roadmap Service for Apache Hadoop empowers organizations to size and plan the deployment of the Hadoop platform. Taking best practices, experience and organizational considerations into account, the service develops a roadmap that helps drive successful planning and deployment for Hadoop.
As part of HP’s strategy to understand 100 percent of an organization’s data, HP announced new capabilities for embedding the Autonomy Intelligent Data Operating Layer (IDOL) 10 engine in each Hadoop node, so users can take advantage of more than 500 HP IDOL functions, including automatic categorization, clustering, eduction and hyperlinking.
HP says the hope that the “combination of Autonomy IDOL and Vertica 6 plus the HP AppSystem for Apache Hadoop, provides customers with an unmatched platform for processing and understanding massive, diverse data sets.”
NEXT — Oracle Snaps Up New Acquistion >>
Oracle Snaps Up Social Intelligence Company
This week Oracle announced it has entered into an agreement to acquire Collective Intellect. Collective Intellect’s cloud-based social intelligence solutions are designed to let organizations to monitor, understand and respond to consumers’ conversations on social media platforms such as Facebook and Twitter.

Oracle’s leading sales, marketing, service, commerce, social data management and analytics, combined with Collective Intellect and the recently announced pending acquisition of Vitrue, is expected to advance Oracle’s position in the social relationship analytics space.
As Don Springer, Founder and Chief Strategy Officer at Collective Intellect said following the acquisition news, “Collective Intellect’s semantic analytics platform provides cutting-edge technology to Oracle that will create a winning combination as brand-to-customer relationships move from transactional to social.”
The combination is expected to enable organizations to build stronger relationships with consumers through intelligent understanding of their social conversations and to respond with appropriate action and engagement.
Leading Solution Providers

















