


July 13, 2012
Cascading into Hadoop’s Golden Era
Necessity really is the mother of invention, especially in the world of application development. There are thousands of untold stories from the dev corner, many of which eventually score a happy ending in the form of an open source project or new business model.
![]() One story of need-spawned inventions from development land that is worth telling, however, especially in this era where one could easily believe Hadoop can save the world, is best narrated by Chris Wensel, the author of the Cascading open source project and current CEO and founder of the Cascading framework-based company, Concurrent.
One story of need-spawned inventions from development land that is worth telling, however, especially in this era where one could easily believe Hadoop can save the world, is best narrated by Chris Wensel, the author of the Cascading open source project and current CEO and founder of the Cascading framework-based company, Concurrent.
At the heart of his tale is the invention that spawned from a “simple” struggle writing a MapReduce application, which Wensel openly admits was one of the most atrocious experiences solving problems he’d ever encountered. Outside of the practical process of writing this, which he says was even a simple MapReduce app, was one major stumbling block—it’s almost impossible to think in MapReduce, let alone operationalize a concept in it.
There is a clear need for developers who can build MapReduce applications, which are at the core of the Hadoop implementations that are supposed to become more commonplace. As Wensel’s experiences highlight, however, it’s hard to find people who can write these apps for Hadoop deployments—and more practically, it’s hard for even experienced developers to wrap their brains around at times.
Wensel says that after experiences with Nutch (a precursor to Hadoop) and working with companies in the pre-Cascading days he saw the real value of massive scalability, but he knew that without an abstraction layer, the promise of a data-driven business would remained obscured under programmatic complexities—complexities that were not necessary.
And so Cascading was born in 2008. Since that time, numerous offshoots have emerged from data science teams at Twitter and through standard open source channels. He points to how the ecosystem around Cascading has been pushed forward by contributors, including Twitter and others, in part because of the need for integrating multiple tried and true languages:
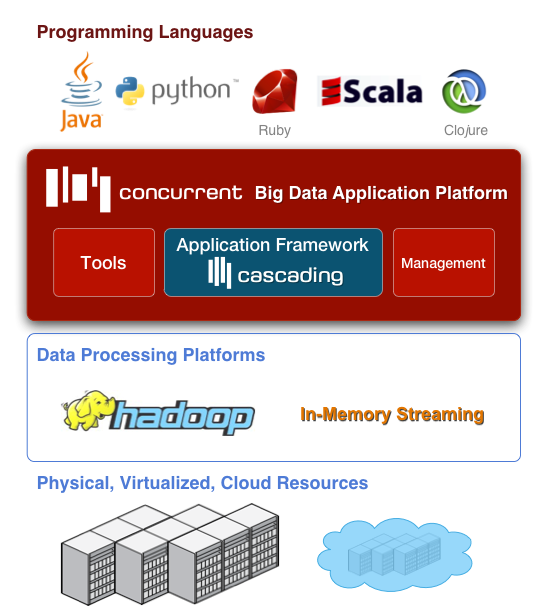
In essence, the company wants to drive robust big data application development for users whose sole business hinges on making use of clunky, massive or otherwise unwieldy data. His young company, which has found some funding and is rolling forward with some interesting use cases (Twitter, Etsy and Trulia are some good examples) provides a Java framework that lets developers build enterprise-grade analytics and data management apps that can be lugged around the cloud circuit or with on-premise Hadoop clusters and across the API compatible distros.
Quite simply, developers needed the ability to tap into a powerful framework that would let them do new things to productize data. Once one appeared, it was so appealing that finding a barrier in something as fundamental as the MapReduce side was an atrocity.
Wensel says that since the problem with working in MapReduce is not just complexity, it’s that it’s difficult and unfamiliar to try to conceptualize problems in it at a velocity that makes sense for data-driven businesses that change daily. One solution is to put a high-level layer inside, like SQL on Hadoop, which he says is reasonable, but it limits the freedoms that are really the “point” of having a Hadoop cluster. As he stated, you could use “SQL but users want to hit loops, write their own functions and filters—they don’t want to be beholden to the limitations of SQL and stuck using arcane mechanisms to add to primitive SQL.”
What is useful, however, is that Cascading looks like everything you’d find right under the SQL syntax. BY developing it that way he says Cascading can give enterprise java developers a way to work the way they’re used to thinking about complex business problems. He also says that the other advantage of being right under the SQL is that there’s been no dictating about which syntax to use; users can build their own framework or syntax to use freely. He says that with this single-platform abstraction, Hadoop is no longer off-limits to the traditional enterprise java person, just as it’s more within reach for the lone data scientist who wants to have a shell and ask questions over and over until they have an answer to work with again. This capability is further added by elastic clouds, he says, because now users can do their testing on a few nodes, then scale out their production environment to many thousands of nodes.
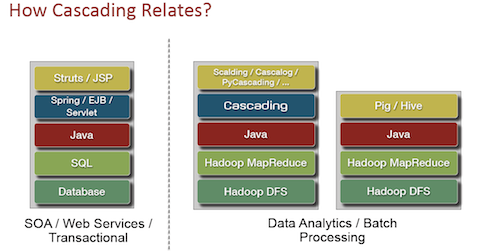
On that note, he says that many Cascading users are tapping into Amazon for their projects, and then want to be able to transfer this over to a production environment on-site. While this might sound simple, there are potential complications. For instance, many environments leverage one of the handful of Hadoop distributions, which Wensel says is great, but those distro vendors need to make sure that they are compatible with Cascading. He says that it’s in their best interest to make use of the testing kits they provide because users can switch out their Hadoop clusters, but they can’t swap out their Cascading projects. He claims that compatibility is the great threat to the “promise of Hadoop.”
Next — Cascading into the Future >>
Wensel drove home another point of caution that bears repeating; despite all the talk from the vendor community that Hadoop will drive performance, the fact remains that it’s something of a lumbering elephant; it’s real power is in scale versus the ability to stampede over problems in a real time. While there are a number of vendor efforts he says claim to speed Hadoop to make it fast over large, complicated problems, there are sacrifices that defeat the very purpose of Hadoop because they inadvertently limit the bandwidth and the scope of the data needed to solve true data-driven problems.
While Wensel is quick to point to the true value behind the buzz around cloud computing, if you ask him about the “big data” buzz that’s been circulating, he’ll tell you it’s a skewed concept that’s been thwarted in meaning.
Wensel claims that the only real meat to all the big data discussions is in the ability to solve new or previously impossible problems with complex data sets. Size alone, he says, is not really an issue, especially for companies that are in the business of data, versus just using large volumes of data to do what looks a lot like traditional BI.
Related Stories
Six Super-Scale Hadoop Deployments
Chips, Stats & Stones: A Morning with SAS CEO Dr. Jim Goodnight
How 8 Small Companies are Retooling Big Data
Technologies:
Frameworks
Vendors:
Startups and More...
Leading Solution Providers

















