


March 19, 2013
Putting Some Real Time Sting into Hive
A coalition of Hive community enthusiasts has reported that they have achieved a 45x performance increase for Apache Hive through an effort they have branded “The Stinger Initiative.”
 Consisting of resources from the Hive community, including developers collaborating from SAP, Yahoo!, Microsoft, Twitter, Facebook, and Hortonworks, the Stinger Initiative was announced last month with the goal of making Apache Hive 100x faster.
Consisting of resources from the Hive community, including developers collaborating from SAP, Yahoo!, Microsoft, Twitter, Facebook, and Hortonworks, the Stinger Initiative was announced last month with the goal of making Apache Hive 100x faster.
“Apache Hive was originally built for large-scale operational batch processing and it is very effective with reporting, data mining and data preparation use cases,” said Alan Gates, one of the developer co-founders of Hortonworks. “These usage patterns remain very important but with widespread adoption of Hadoop, the enterprise requirement for Hadoop is to become more real time or interactive has increased in importance as well.”
The goal, says Gates is to enable Hive to respond more in line with “human time” (i.e. queries in the 5-30 second range), without changing how people interact with the HiveQL interface.
The early results are in, announced Gates today, and while the initiative is still short of the 100x increase they’re aiming at, they say they’ve made great progress on the road to it. Detailing two of the most common use cases for Hive, and testing against the TPC Benchmark™ DS (TPC-DS), the group says they’ve achieved as much as a 45x increase in performance.
The group says that the test environment comprised of a 10 node cc2 cluster with a total of 100 containers over 40 disks. Their intention is to obtain query execution times with Hive on raw data, with all the optimizations enabled on partitioned data stored in RCFile format – and a data set of around 200GB.
“For the first query, we’ve calculated as much as a 35x improvement over native Hive, and have reduced query times from around 1400 seconds to 39,” exclaims Gates. In the second query, Gates says they calculated a 45x improvement, “all in open Source Apache Hive.”
More improvements are on the way says Gates, including improvements to the recently introduced runtime framework, Tez, which aims to eliminate latency and throughput contraints in Hive through it’s reliance on MapReduce, as well as testing with a new ORCFile columnar format aimed at providing a more high performance way of storing Hive data.
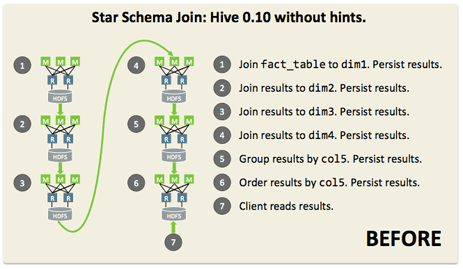
Gates provided a graphic that models what the before and after execution looks like to date:

Related Items:
How Facebook Fed Big Data Continuuity
DDN Casts Hadoop with HPC Hook
Hortonworks Proposes New Hadoop Incubation Projects
Technologies:
Frameworks
Vendors:
Hortonworks
Tags:
Alan Gates, and Hortonworks, apache, facebook, Hadoop, Hive, microsoft, real-time, SAP, Stinger Initiative, twitter, Yahoo!
Leading Solution Providers

















