


November 19, 2013
Closing the Big Data Networking Gap
With all the talk about really big data sets, it’s somewhat surprising to learn how much data moving across the network is simply not visible to most organizations. Getting access to large amounts of data at the network-packet level is not as easy as you might think. Today VSS Monitoring announced a potential solution that bridges the gap between network data flows and big data systems, like Hadoop.
![]() VSS Monitoring develops network appliances designed to provide low-level access to data flowing across the network, primarily for network performance monitoring and security applications. Its flagship vBroker network packet broker (NPB) device sits either in-line to the data flow, or connects via a span port, and works by deploying non-intrusive probes into the network that allow it to grab any piece of data flowing by, which it then filters and grooms the raw network data using its on-board processors, before sending it to downstream to packet-shaping network optimization tools and security event and information management (SEIM) tools.
VSS Monitoring develops network appliances designed to provide low-level access to data flowing across the network, primarily for network performance monitoring and security applications. Its flagship vBroker network packet broker (NPB) device sits either in-line to the data flow, or connects via a span port, and works by deploying non-intrusive probes into the network that allow it to grab any piece of data flowing by, which it then filters and grooms the raw network data using its on-board processors, before sending it to downstream to packet-shaping network optimization tools and security event and information management (SEIM) tools.
As the volume of data flowing over the network increased, VSS Monitoring was able to keep up, largely through engineering. However, problems started to pop up with the downstream tools. Those tools had a hard time dealing, in a real time way, with the huge data flows being generated.
With the advent of Hadoop and cheap storage appliances, IT managers started moving some of these activities that were strictly real-time affairs toward a more batch-oriented paradigm. However, there was no easy way to offload data stored in these network optimization and SEIM tools into Hadoop or big NAS clusters, because they typically store the packet data in a proprietary format.
So VSS Monitoring took it upon itself to address this dilemma, which it calls the “big data gap.” The offering introduced today, called vSpool, sits inside the vBroker chassis, and transforms the network packets into an industry standard format that’s readable by those systems, called packet capture, or PCAP.
It’s all about making network traffic as useful as possible to its customers, says Angelique Medina, product manager at VSS Monitoring.
“Many of our customers have started to build their own Hadoop clusters to complement their network analytics toolsets,” she says. “But they don’t have an effective way to take in those network packets, because their storage infrastructure and their Hadoop clusters are not able to natively ingest network packets. You need some type of special hardware to ingest it and write it to disk.”
In addition to outputting PCAP files, vSpool, which starts at $7,000, also generates a small metadata text file that allows customers to index their PCAPs for quick search later on. It also timestamps the PCAPs, which is often very useful during later analysis.
The security department of a large financial services firm (which didn’t want its name used) has already started using vSpool to address the need to analyze growing data flows. According to Medina, the company had been using security forensics appliances to store network session data, which it is required to do for compliance purposes. When the appliance approach grew too expensive and cumbersome, it decided to switch to Hadoop, which was only possible with vSpool converting the network packet information into PCAP format.
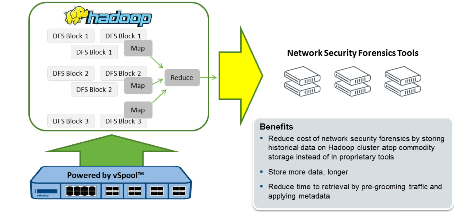 “They didn’t want to use their security forensics tools,” Medina says. “They didn’t necessarily need the analytics on those tools, because they didn’t know if they ever needed to look at the data. It was really just for compliance reasons. With this approach, they can store it, and if they need to, they can go back and find what they need.”
“They didn’t want to use their security forensics tools,” Medina says. “They didn’t necessarily need the analytics on those tools, because they didn’t know if they ever needed to look at the data. It was really just for compliance reasons. With this approach, they can store it, and if they need to, they can go back and find what they need.”
The timestamp is also critical for this customer, Medina says. “As they’re looking through this huge store, they can find precisely what they need based on the time signature,” she says. “That’s pretty important for them. And also the capability to throw away the things they don’t need. Ideally you store everything. But they too had a constraint around storage. So they wanted to toss the VPN traffic and also slice off payloads of certain types of traffic to further sift it down.”
There are vast amounts of potential useful information that are going unutilized–that are falling into the “big data gap.” VSS Monitoring is touting an IDC study that found that only 3 percent of data in motion is made available to business intelligence systems, and of that, only half a percent is analyzed. Those are pretty poor percentages.
Granted, not everybody needs access to the raw, unfiltered data feed that is a corporate LAN or a leg of the actual Internet. Unless you’re Google, it’s simply beyond the scope of current technologies to even think about trying to harness that much data into a potential business model. But for some types of operations–such as financial services firms trying to track fraud or a large telecom provider trying to track customer experience–this approach is not only possible, but can improve one’s business effectiveness and cut down on compliance costs.
As data processing capabilities expand, more organizations may find uses for packet-level networking data. While the volumes of data flows make asynchronous paradigms like Hadoop MapReduce especially pertinent, users may find that running PCAPs through a streaming data analysis products–such as Apache Storm, LinkedIn Samza, or Amazon’s new Kinesis–can extract some useful gems from the fresh data that was previously flowing out to sea.
Two of VSS’ partners, Riverbed and Hitachi Data Systems, signed on with the company for the launch of vSpool. Hitachi is looking to sell vSpool along with its Hitachi Content Platform (HCP) to give customers better big data search and security capabilities. Riverbed, meanwhile, is looking to pair vSpool with its Cascade Shark storage appliance to capture packets for later analysis.
In a separate announcement, VSS Monitoring also announced vNetConnect, another device that plugs into its vBroker NPB system. vNetConnect gives the NPB visibility into the network traffic flowing into and out of virtual machines, such as those controlled by VMware’s vSphere or Microsoft’s HyperV. Previously, the company was primarily limited to operating at the physical network layer.
Related Items:
Amazon Tames Big Fast Data with Kinesis Pipe
Splunk Pumps Up Big Data with Hunk
LinkedIn Open Sources Samza Stream Processor
Leading Solution Providers

















