


January 14, 2014
Google Bypasses HDFS with New Cloud Storage Option
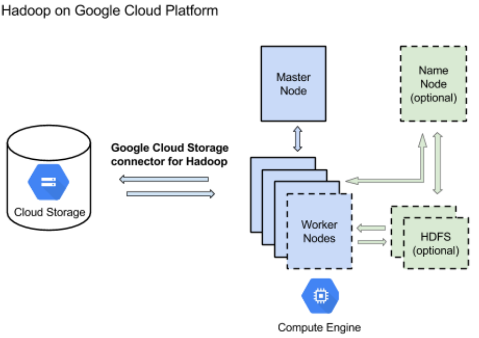
Google Hadoop customers can now run MapReduce jobs directly against data stored in the Google Cloud Storage and leave HDFS out of the big data equation as a result of a new cloud storage Hadoop connector the Web giant unveiled today.
There are many reasons why you might want to bypass the Hadoop Distributed File Systems (HDFS) when running Hadoop jobs on Google Compute Engine slices running in the Google cloud. For starters, using Google’s object storage lets you focus on data processing logic instead of on managing a cluster and file system, according to Google.
Using the Google Cloud Storage instead of HDFS means no more running file system checks, rebalancing, upgrades, rollbacks, and NameNode restarts, the company says. “Google Cloud Storage just works,” the company says. “Your data is safe and consistent with no extra effort.”
 Getting started is faster too, since you don’t have to wait while the Google Compute Engine to copy data to the HDFS and for the NameNode to come out of safe mode, according to Google, which unveiled the new connector on its Google Cloud Platform blog.
Getting started is faster too, since you don’t have to wait while the Google Compute Engine to copy data to the HDFS and for the NameNode to come out of safe mode, according to Google, which unveiled the new connector on its Google Cloud Platform blog.
The data is also safer on the Google Cloud Storage, the company says, because it’s globally replicated. Because of this, there’s no need to pay for additional backup (as you would if storing data in HDFS on Google Compute Engine VMs), further reducing costs.
Storing the data separately from HDFS also keeps it separate from the Hadoop compute nodes and the NameNodes. (In fact, users don’t even need the NameNode when using Google’s object store.) This provides higher data resiliency, because if the Google Compute Engine VMs on which the Hadoop cluster live are turned off or crashed, the data is gone, the company says.
Google Cloud Storage, called Colossus, is a RESTful service for storing and accessing data objects stored on Google’s infrastructure. Changing a Google Hadoop instance to use Colossus is a simple matter of changing the URL to point to the object store instead of HDFS. Google also gives customers the option to store data in both HDFS and its Cloud Storage platform, whereby users access it using a different file path.
Related Items:
DataStax Puts Big Database in Google’s Cloud
Can Google Harness Big Data to Ward Off Death?
Leading Solution Providers

















