


April 17, 2014
Inside zDoop, a New Hadoop Distro for IBM’s Mainframe
IBM and its partner Veristorm are working to merge the worlds of big data and Big Iron with zDoop, a new offering unveiled last week that offers Apache Hadoop running in the mainframe’s Linux environment. By gaining Big Blue’s seal of approval, zDoop could change the big data landscape for organizations that rely on mainframes.
 When you think about the IBM mainframe, you probably think about real world outfits like banks that process transactions with 50-year-old COBOL applications. You probably think about exotic processor, unusual data formats, expensive MIPS, running at 95 percent of capacity for years on end, and never experiencing unplanned downtime.
When you think about the IBM mainframe, you probably think about real world outfits like banks that process transactions with 50-year-old COBOL applications. You probably think about exotic processor, unusual data formats, expensive MIPS, running at 95 percent of capacity for years on end, and never experiencing unplanned downtime.
What you don’t think is ‘Hey, this $10-million System z would be a great place to store this 100 TB file of unstructured customer sentiment data we just got our hands on.” You don’t think “Let’s load tons of sensor data onto the mainframe, do some data discovery on it, and maybe find something interesting.”
The wild and wily Internet of Things is throwing off “data exhaust” at ever increasing rates, but most organizations haven’t figured out how to use it. Instead of throwing it out, many organizations are storing it in a “data lake,” with the hopes it will be valuable in the future. That data lake is probably running Apache Hadoop, and it’s probably running on a cluster of cheap commodity Intel servers.
The notion that the mainframe would be a good place to store this massive set of highly unstructured data with an as-yet ill-defined business value would seem completely contrary to the ethos of the mainframe, which is the poster child for structured corporate data. Surely, the mainframe and Hadoop have absolutely nothing in common?
And yet, as IBM celebrated the mainframe’s 50th anniversary last week, we heard IBM talking about the mainframe as a good place for Hadoop. We had Tom Rosamilia, IBM’s senior vice president of IBM Systems & Technology Group,
 |
|
| Tom Rosamilia, IBM’s senior vice president of IBM Systems & Technology Group, discussing zDoop last week. | |
welcoming Hadoop onto the mainframe via zDoop, which was developed by IBM’s partner Veristorm.
Rosamilia took a page right out of the Hadoop playbook in making the case for using Hadoop on the mainframe to process unstructured data. “No matter what platform you choose, you want your compute capacity and your data to be co-resident,” Rosamilia says. “We see 80 percent of world’s corporate data residing here [on the mainframe]. We want to be able to get that data and the unstructured data, and be able to process it together at the same time.”
Ironically, moving data off the mainframe has become one of the mainframe’s biggest workloads, accounting for up to 20 percent of MIPS, according to IBM studies. There’s a cottage industry of IT vendors who specialize in finding cheaper and more efficient ways to get that structured data out of VSAM, DB2 for z/OS, or flat file systems and onto cheaper data storage platforms.
However, moving that much data creates its own set of problems. “We see people creating 11 12 copies of the data. It’s not very secure when you have that many copies and how often do you have to refresh it to make sure that it’s current? Rosamilia says. “It’s a lot easier for us to move this [unstructured data] onto a zLinux environment and do that structured and unstructured analysis at the same time.”
 |
|
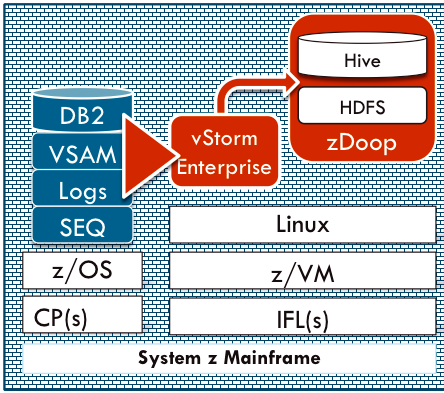
| The zDoop architecture | |
Nobody is likely to buy a mainframe just to run Hadoop. But for those companies that already have a mainframe, processing some unstructured data in a mainframe-resident Hadoop environment could make economic sense compared to exporting it to a data lake. zDoop is the first Hadoop distro to be certified to run on the IBM mainframe.
Veristorm bills zDoop as the first Apache Hadoop distribution designed to run on the Integrated Facility for Linux (IFL), which are processors in the System z that are dedicated to running Linux. Because it does not run Hadoop on z/OS, zDoop does not incur MIPS charges.
zDoop is actually a component of Veristorm’s vStorm Enterprise product, which also includes a product called vStorm Connect that moves z/OS, VSAM, and IMS data into zDoop’s HDFS environment, thereby eliminating the need to involve COBOL copybooks and other traditional processes. In a Youtube video, Veristorm’s Mike Combs demonstrates how the product’s Web-based interface makes it relatively easy to move data from mainframe data sources into the zDoop environment.
In addition to streamlining the data movement processes, Veristorm has done the hard work of integrating zDoop into the mainframe RACF security system. Customers can use their existing mainframe security credentials to sign into zDoop, and not worry about data being exposed in an unsecured Hadoop cluster.
zDoop implements HDFS and Hive data repositories, enabling customers to prodcess the data using traditional MapReduce applications or using SQL-like queries. vStorm Enterprise comes with some basic visualization tools, but customers can use their own, such as those from Tableau, QlikTech, and TIBCO.
There are several use cases where it makes more sense to move unstructured data onto the mainframe, where it can be mixed with structured mainframe-resident data and subsequently analyzed, versus moving structured data off the mainframe to a separate Hadoop cluster. One of those is analyzing bank fraud.
While many mainframe banking applications have anti-fraud capabilities built into them, the mainframe does not always store all the data necessary to detect the fraud. In these cases, moving non-relational data sources into the mainframe so it can be analyzed with zDoop will minimize the potential risks involved with moving sensitive payment data off the mainframe for analysis.
A similarly case can be made for insurance companies that are taking innovative new approaches to pricing their premiums. An auto insurance company, for example, may wish to augment the traditional sources of policy pricing information with actual real-world driving information captured through GPS and other sensors, and uploaded through telematics. It may make more sense to move that unstructured sensors data to the mainframe than moving sensitive pricing information to an unsecured Hadoop cluster.
Because of the tight security of IBM mainframes, healthcare companies are some of the biggest mainframe shops. Hospitals and doctor’s offices that are looking to utilize non-traditional sources of information to improve the quality of care may look to merge unstructured data into their mainframe apps. Sources of this unstructured data that could potentially inform healthcare decisions include frequent changes of home address, absence of emergency contacts, or lack of living relatives. This data may not live in the mainframe, but with zDoop, it can be imported and processed along with the traditional mainframe data.![]()
IBM doesn’t expect Hadoop on the mainframe to be a cure-all for processing unstructured data. In many cases, moving the data to a dedicated, high performance data warehouse, is a better option. Instead, it’s looking to take a hybrid approach that merges the mainframe with emerging technologies, such as Hadoop and the Netezza-based DB2 Analytics Accelerator, all within a “secure zone.”
Veristorm and IBM tested zDoop at IBM’s Poughkeepsie lab, and the results were satisfactory. “You might think that a large yellow elephant would be too much for a mainframe to handle, but our testing conducted shows that the mainframe is indeed more than up to the task and can handle a broad range of real-world problems quite nicely,” IBM and Veristorm say in their joint white paper, “The Elephant on the Mainframe,” which is available on the Veristorm website.
The mainframe isn’t going to be a mainstream Hadoop platform anytime soon. But for big companies that already run it, solutions like zDoop show that the mainframe doesn’t have to be entirely separate from big data projects either.
Related Items:
Veristorm Launches vStorm Enterprise
Syncsort Siphons Up Legacy Workloads for Amazon EMR
Picking the Right Tool for Your Big Data Job
Editor’s note: This story was corrected. While IBM has worked with vendors, including Cloudera, to certify Hadoop on the mainframe, zDoop is the first Hadoop distribution to actually get certification on the machine.
Applications:
Data Mining
Vendors:
IBM
Leading Solution Providers

















