


May 27, 2014
Neo Rides the Graph Database Surge

Interest in graph databases has exploded during the first five months of the year, as the product category threatens to lap other database types in popularity, according to figures from DB-Engines.com. The surge is a natural response to people’s desire for an easy and intuitive way to find connections hidden in data, says graph database leader Neo Technology, which is rolling out version 2.1 of Neo4j this week.
Up until December, interest in graph databases closely matched the interest in NoSQL databases, including wide column stores, document stores, RDF stores, key-value stores, and others. (Graph databases are now considered a separate category from NoSQL databases, but that’s another story.) Interest in all of these database categories has been growing steadily for a while, as people seek technologies that can help solve big (and pesky mid-size) data-related challenges.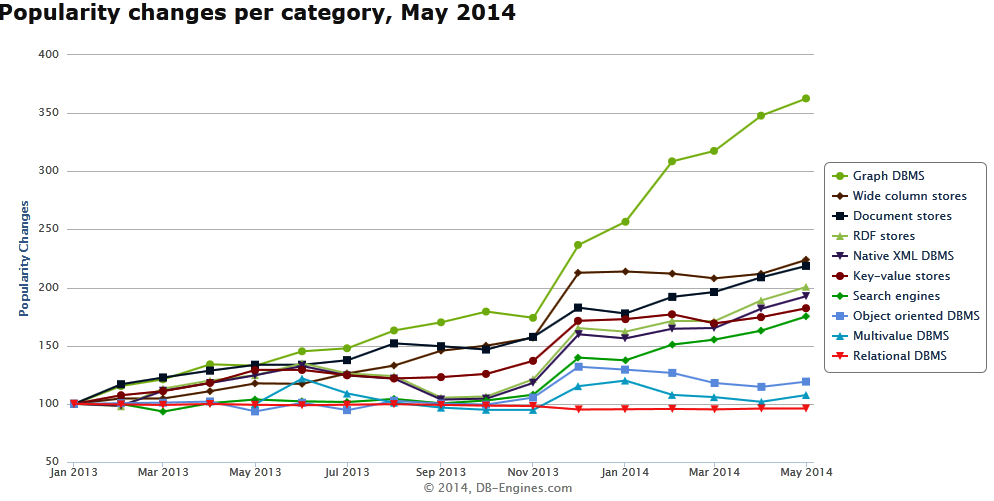
But in January, people’s interests changed quite dramatically, and the graph database category shot out far ahead of its NoSQL compatriots, according to DB-Engines, which uses various sources of data to rank databases and track database adoption trends, including Web searches, discussions in public forums, and job offers, among others.
It’s hard to tell what caused the sudden interest in graph databases. It could be that people suddenly realized relational databases can’t do what they need them to and decided to give graph a try. It could be that organizations felt a sudden and intense desire to emulate the technology that power the social media empires of Facebook and LinkedIn. Or it could be that the Seattle Seahawks won the Super Bowl. In big data, when faced with a multitude of facts, it’s tempting to downshift from causation to correlation.
But if DB-Engines’ numbers are to be believed (and there’s good reason to say they should), then it’s clear that Neo Technology had something to do with it. The San Mateo, California, company is the clear leader in the emerging graph database field, and its product, Neo4j, has a popularity rating that’s 10 times bigger than that of its closest competitor, the Titan graph database.
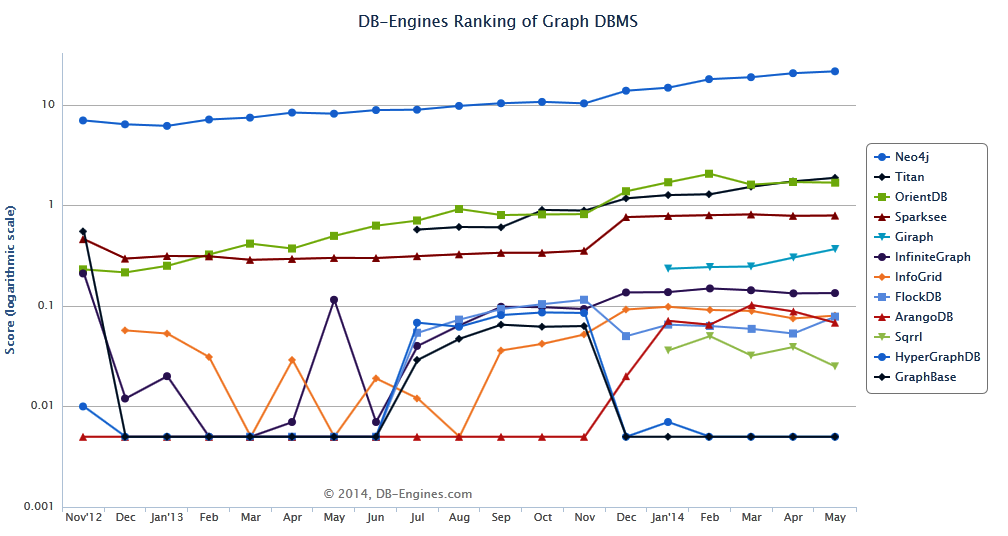
The LOGARITHMIC graph database popularity chart from DB-Engines.com
A peek at DB-Engines graph database comparison (graphed in a slightly non-intuitive logarithm scale) shows steady growth for Neo4j. Titan and OrientDB, a multi-modal database, show some growth. But the only other notable change in the graph that could explain such a big uptick is the category as a whole is the addition of two new graph players in January, including Apache Giraph and Sqrrl, the security-related graph database.
Philip Rathle, vice president of products at Neo Technology, has an idea what may have triggered the rush on graph: the release of Neo4j version 2.0 in late December. “Adoption [of version 2.0] has grown so explosively that the entire graph database category has grown significantly faster than any database category in popularity,” he tells Datanami.
While Rathle has his own biases (and causality may never be properly rendered), the data points speak for themselves. “It’s pretty amazing,” he continues. “In my career in data and databases for close to 20 years, I’ve never been in a situation where a company has dominated a category by this much.”
To what does Neo Technologies owe this success? A combination of “luck and foresight,” Rathle says. Frustrated by the limitations of relational databases, the founders started working on Neo4j in the early 2000s. By storing data in a way that makes it easy to establish connections that link data, the founders had created a whole new database category.
Over the years, the database was gradually brought up to enterprise-grade strength with the addition of features such as support for ACID consistency and high availability. Instead of trying to force SQL to perform big joins in relational databases, developers were finding they could accomplish the same tasks more easily in Neo4j using its Cypher query language.

Neo Technology’s “NASCAR” logo chart
Today, Neo4j-based graph databases are running at big companies, including Wal-Mart, EBay, Cisco, and HP, not to mention lots of Web startups. The database isn’t always brought in to solve classic “big data” use cases involving petabytes of data and trillions of records. Rather, Neo4j excels in finding connections in mid-size data sets involving less than 10 billion entities.
One of these emerging graph database use cases is making product recommendations, which is also something that people are using Hadoop for. The fast and real-time nature of a graph database makes it an excellent platform for this type of workload, Rathle says.
“Many people use Hadoop or even things like relational data warehouse to pre-compute scores. The problem is because Hadoop doesn’t operate in real time, you end up having these batch jobs that pre-compute scores for everybody,” he says. “From a technology perspective, you end up burning huge amount of computing resources to generate recommendations for everyone, including the 99 percent of people who aren’t going to actually touch you today. So doing it in real time is both more effective on the business side and efficient technologically.”
As the graph database market matures, you can expect other database makers to look for a spot on the graph database bus. But Rathle isn’t worried that Neo Tech will be passed. “It takes five to seven years to actually build a database, from a first line of code to something you can run in production at multiple companies. We’re in a lucky position to have done that groundwork before the market was ready,” he says.
Rathle is especially nonplussed when it comes to attempts to conjure a graph database by outfitting a NoSQL database with graph add-ons. They may be able to come up with a good API to hand to end users, but building a graph database engine that doesn’t corrupt data when running at scale is easier said than done, he says.
This week the company will be unveiling Neo4j 2.1, which adds a new “Load CSV” feature to the Cypher query language. The new function will be useful for pulling data out of relational data stores in a manner that they’re already familiar with. “It’s a small feature that’s going to be incredibly useful in helping lots of people unlock the insights that are just sitting latent in their databases, waiting to happen but can’t happen because you can’t easily express the queries,” he says.
Related Items:
Set Your ‘Inner Graphista’ Free, Neo Says
Intel Goes Graph with Hadoop Distro
Facebook Graph: More Than a Trillion Edges Served
Technologies:
Middleware
Vendors:
neo technology
Leading Solution Providers
















