


July 16, 2014
Software-Defined Storage Takes Off As Big Data Gets Bigger

The ongoing explosion of data is forcing users to adapt their storage methodologies beyond traditional file- and block-level storage. Object stores and software-defined storage mechanisms, in particular, are quickly gaining footholds at organizations that need to store massive unstructured data sets. Meanwhile, some vendors are promoting a twist on object stores with new “data-defined” storage techniques.
File-level storage works well with traditional structured data, such as what you might find in a commercial accounting system using direct-attached storage devices (i.e. hard drives). As data volumes increased, many customers found success using block-level storage, where data volumes are virtualized across groups of devices that make up a storage area network (SAN), such as those from NetApp, IBM, and EMC.
As the data sets get bigger and more diverse, object-based storage mechanisms begin to shine. By breaking data away from the file-based hierarchies and assigning the object a unique identifier, object stores complete the virtualization of data from the underlying storage device, thereby enabling scalability that is theoretically unlimited. And since object stores typically run on clusters of commodity hardware–as opposed to proprietary appliances with the big-name SANs–they bring big cost benefits to the equation.
Object stores have become increasingly popular over the past few years, particularly as the storage backend for hyperscale Web outfits like Facebook and Spotify. Large-scale object stores implemented by these Web giants–Amazon S3 is the world’s largest object-store–are beginning to account for a bigger share of the total storage market.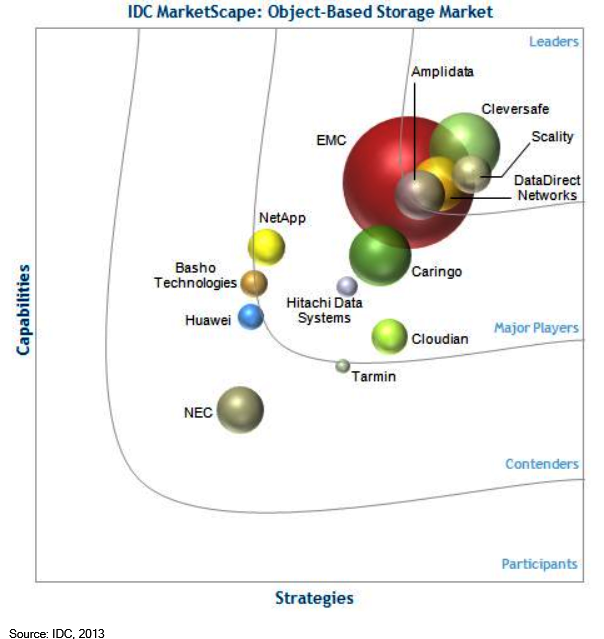
According to a 2013 IDC report, spending on scale-out object-based and file-based storage will reach $38 billion by 2017, up from 2013 revenue of $23 billion. While traditional file-based storage is now retracting, the scale-out object and file-based storage is growing at 24 percent. Within this segment, software-defined platforms will grow faster than any other market segment in the file- and object-based storage market, says IDC research director Ashish Nadkarni. “This growth will primarily be driven by a rich and diverse set of data-intensive use cases across multiple industries and geographies,” he says.
Eager to reap the cost and scalability benefits, large enterprises have begun implementing their own object stores from big data storage vendors like DataDirect Networks, Scality, Cleversafe, Amplidata, and EMC. In most cases, these vendors refer to their object-based storage offerings as software-defined storage; the terms are essentially interchangeable.
The customer wins are starting to stack up. Verizon recently tapped Amplidata and its object store, dubbed Himalaya, to power its new Verizon Cloud Storage platform. Himalaya can scale into the zettabyte range, the company says, while maintaining durability and the ability to run on commodity hardware. In June, Scality announced that Los Alamos National Laboratory will use Scality’s software-defined storage architecture, dubbed RING, as the active archive for the data used in simulations of the US nuclear weapons stockpile.
DDN has achieved success with its object-based storage offering, called Web Object Scaler (WOS). In a recent story, DDN CMO Molly Rector explained the five areas where the company is hoping to differentiate WOS. Those include: driving scalability; maintaining broad accessibility to different APIs (such as Amazon S3 and OpenStack Swift); maintaining efficiency; ensuring reliability; and boosting performance.
There are also open source object stores, and they’re starting to make inroads too. Today, Red Hat announced the availability of Inktank Ceph Enterprise version 1.2, the commercialized version of the open source Ceph object store from Inktank, which the company bought in April for $175 million.
Ceph is one of the most commonly used back-end storage layer used in OpenStack, and competes with the Swift interface. In addition to providing a standard REST interface for the object store, it includes an Amazon S3 interface and block- and file system interfaces. The file system interface is available in the open source version of Ceph, but is not yet ready for primetime, and therefore isn’t in Inktank Ceph Enterprise.
As the volume of variety of big data increases, organizations will look to object stores and software-defined storage to handle it, says Ross Turk, the vice president of marketing and community at Inktank. “The value of software-defined storage is it runs on everyday hardware and you can grow or shrink the cluster at will with a very small increment, one box here one box there,” he tells Datanami. “If you need to build a system that handles outages automatically and rebalances data based on the status of the cluster it really needs to have an object base, because it’s really difficult to dynamically move around files and directories the way you can moved around objects.”
Meanwhile, the prospect of data-defined storage is starting to make itself known. One of the early leaders in this emerging areas is Tarmin, which was founded by two former MasterCard employees, Shahbaz Ali and Steve Simpson, who had trouble storing financial transactions at the credit card giant.
Tarmin’s data-defined storage platform, dubbed GridBank, is built upon the precepts of object stores and software-defined storage, but adds several new elements to get beyond some of the limitations of software-defined storage. In particular, this includes addition of global storage that’s independent of media types; integrated data security and identity management; and a distributed metadata repository.
In a recent article, Tarmin co-founder Shahbaz Ali explained one of the key advantages of the data-defined storage approach compared to software-defined storage. “To ingest existing file data and support data access for file based workflows, a third-party file gateway server must be added [to the object store], with file protocols on one side and object API commands on the other. These gateways often eliminate many of the advantages of using object storage, including scalability, parallel object access, architectural flexibility, and improved data availability.”
While the standards around these new storage mechanisms are still being established, it’s clear that the world is moving beyond the limitations of file- and block-based storage, and embracing new forms of storage that can scale with the growth of big unstructured and semi-structured data sets. Look for this area to generate lots of interesting developments in the years to come.
Related Items:
Demand for Software-Defined Storage Is Up: Survey
Primary Data Gains $50M for Software Defined Storage
Rebuilding the Data Center One Block At A Time
Leading Solution Providers

















