

September 16, 2014
MapR Puts Apache Drill into Hadoop Distro

Organizations today demand tools that provide familiar SQL-based access to data stored on HDFS. Today, MapR Technologies gave its customers yet another SQL interface when it announced support for Apache Drill 0.5 in the new release of its commercial Hadoop distribution, MapR 4.0.1.
Apache Drill is an open source framework that delivers a full SQL-compliant interface that allows users to query unstructured data stored on HDFS for data discovery purposes. The project, which is backed by MapR and is an Apache incubator project, is based in large part on Google‘s Dremel and was designed to provide a low-latency, schema-on-read query capability against trillions of data points that range well into the multi-petabyte range.
According to the folks at MapR, Apache Drill lets analysts and developers explore unstructured data through good old SQL, without requiring the assistance of a DBA or somebody else to cleanse, transform, and package the data.
“This whole data exploration step is a gap,” says MapR chief marketing officer Jack Norris. “You have to go through IT to do the plumbing, the ETL, the processing. That structured approach works really well when you know what you’re looking for, when you understand the data and you want to organize it in such a fashion to support very rapid and in-depth analysis. What we’re talking about with big data is, even before you’re doing some of these heavy duty analytics and listening to what’s going on, you want to understand what’s there.”
That level of data exploration is not possible using other SQL-on-Hadoop products, all of which require data to be hammered into a schema before accessing, Norris says. “Every other [SQL] solution in a Hadoop environment is about fixed schemas,” he says. “It’s basically taking the design center we had in a relational database world and using that same design center in big data.
Apache Drill is unique in that it allows users to query unstructured data, namely JSON, without first flattening the data or hammering it into a fixed schema (although it will also work against structured data if you’ve already taken the effort to stratighten in out). This gives MapR customers powerful new tools to analyze clickstream data collected from the Web and other Internet of Things workloads, and will fit in with other SQL tools, like Hive, Impala, and Spark SQL, all of which MapR includes in its distribution.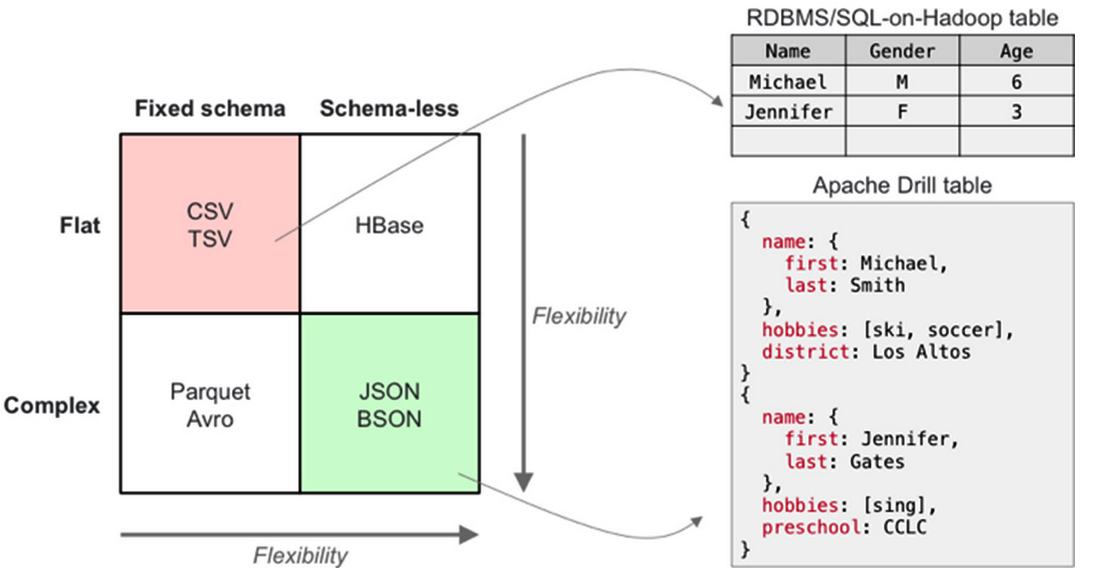
The need for fixed schemas is “one of the dirty little secrets about Hadoop,” says MapR vice president of marketing Steve Wooledge. “When Hadoop first came out everybody was excited about it because of the file system [and that] you can put in data without needing to do ETL. But what nobody talks about is, if you want to open it up to anybody with a query language, it’s back to the same old data warehousing paradigm of creating that schema in advance.”
Wooledge equates the schema-on-discovery capability of Apache Drill to using a search interface to navigate an email inbox. Ten or 20 years ago, most people would organize email by storing them in folders. “But now that email has exploded so much, I don’t know about you, but I’ve given up on folders,” he says. “I just let it all sit in my inbox and I search it. That’s the way you’ve got to look at data these days. You’ve just got to be able to query it. You don’t’ have time to structure it.”
Another advantage of Drill is its support for ANSI SQL. It uses plain SQL, not a SQL-like dialect, such as Hive and its HiveQL langague. Cloudera, the major backer of Impala, is working on supporting more of the analytic commands of the ANSI SQL standard.
Apache Drill 0.5 is one of the new features in the new 4.0.1 release of MapR’s Hadoop distribution, which is based on Hadoop 2.4. Another major new feature in 4.0.1 is the ability to run Hadoop version 1 applications within a Hadoop 2/YARN environment.
While YARN has garnered a lot of attention in the Hadoop environment for its capability to divvy up Hadoop cluster resources among competition workloads, some of the compatibility issues have been glossed over, according to Wooledge. Namely, if they want to move their upgrade their cluster to Hadoop 2 and YARN, they’re forced to rewrite their first-gen MapReduce (MR1) jobs into YARN-compatible MapReduce 2 (MR2) jobs.
With MapR 4.0.1, MR1 jobs can run unchanged on the Hadoop 2-based cluster, and MR1 can run side by side with MR2 jobs on the same nodes. This gets users off the hook of re-writing all their MR1 jobs, says Wooledge, who says the capability is a result of MapR’s fine-grained resource control.
“Customers don’t have to rewrite anything,” Norris says. “We maintain that API. No other distribution does that. They force them to re-write all the [jobs]. That’s huge when you talk about production applications.”
Version 4.0.1 also brings support for label-based scheduling, which basically allows customers to ensure that certain jobs run on certain nodes in the cluster. It also includes the capability to have failed jobs restart automatically, and other high availability functions. The new release is available now.
Related Items:
How a Web Analytics Firm Turbo-Charged Its Hadoop ETL
MapR Says Its Hadoop Tweaks Scale to Meet IoT Volumes
MapR Embraces Co-Existence with Hadoop Update
Technologies:
Frameworks
Leading Solution Providers

















