


February 13, 2015
Apache Spark Continues to Spread Beyond Hadoop
Apache Spark is most often thought of as a faster replacement for MapReduce, the batch-oriented programming framework that enabled first-gen Hadoop to catch traction 10 years ago. Indeed, Spark was initially created with Hadoop in mind. But Spark’s promise of speedy and accessible analytics is catching on with other data stores beyond Hadoop, including relational databases.
Spark’s relationship to Hadoop is strong. All of the major Hadoop distributors include the in-memory processing framework with their particular Hadoop distributions. Core Spark is compatible with YARN, the resource manager calling the shots in diverse Hadoop version 2 clusters (although its YARN support can be improved, as Hortonworks co-founder Arun Murthy explained to Datanami last year).
You see lots of Spark in the Hadoop ecosystem, with application vendors like Platfora, ClearStory Data, Alpine Data Labs and H20 using it; data munging and transformation experts Trifacta, and Paxata supporting it; and Hadoop as a service (HaaS) companies like Amazon Web services and Google supporting it too. (You can expect to see more Spark-on-HaaS offerings unveiled during next week’s Strata + Hadoop World conference.)
Yet for all the affinity Spark has for Hadoop, it exists separate from the big yellow elephant. Databricks, the company commercializing Apache Spark, offers a hosted Spark environment that has no Hadoop. NoSQL database vendors like DataStax actually run Spark in its Cassandra database, while Glassbeam, which has a NoSQL database at the heart of its Internet of Things (IoT) analytics application, is also riding Spark’s fast, accessible, and easy-to-use programming interface to develop compelling IoT analytic apps.
Spark for Relational
The latest database maker to hook into Spark is MemSQL, one of the newer in-memory distributed relational databases that are sometimes referred to as NewSQL databases. MemSQL offers support for ACID transactions powered by good old ANSI SQL, which makes it an attractive place to build applications where transactional integrity is paramount, like e-commerce.
But MemSQL’s capability to query massive amounts of data in a short amount of time also makes it handy for doing light, real-time analytic work, what is commonly referred to as operational analytics. This is why organizations are adopting the database for to do things like fraud detection on credit card transaction, real-time attribution for digital advertising, and packet analysis for network security.
The new Spark connector that MemSQL unveiled earlier this week will bolster that use case for real-time analytics. The relational database won’t house Spark directly, but it will enable the free flow of data between a MemSQL cluster and a Spark cluster.
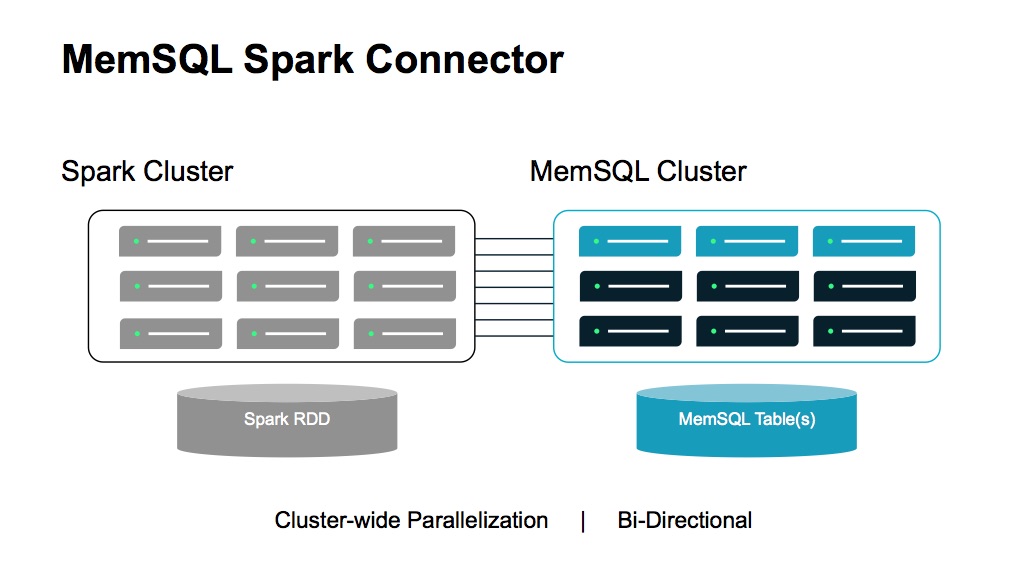 It’s all about building real-time analytic pipelines that can automate decision-making in fast moving data, according to Gary Orenstein, chief marketing officer of MemSQL. “If you think of large website, the bulk of the traffic isn’t unusual,” he says. “Most customers are doing the same thing. But the users at the end of the bell curve are more interesting to the company.”
It’s all about building real-time analytic pipelines that can automate decision-making in fast moving data, according to Gary Orenstein, chief marketing officer of MemSQL. “If you think of large website, the bulk of the traffic isn’t unusual,” he says. “Most customers are doing the same thing. But the users at the end of the bell curve are more interesting to the company.”
Spark’s speed is well-suited for analyzing the behavior of website visitors at the ends of the spectrum. Once the analysis is run and Spark has identified the unusual behavior–maybe the user took an atypical route to the website or made an inordinate number of clicks—then the knowledge can be acted upon immediately within the application. That’s where the hooks into MemSQL come in.
This joining of Spark and MemSQL creates a sort of feedback loop, says Eric Frenkiel, co-founder and CEO of the San Francisco company. “There’s a way now to ensure that the Spark results are immediately implemented, that there’s a hand-off between the data science and application development engineers,” says Frenkiel, who will be speaking about MemSQL and Spark at next week’s Strata show. “[SQL] is good at giving you a very broad language to answer any type of business question, but certain things are not SQL expressible. You can’t have a language do everything. For us [having Spark support] gives customers a way to ask anything they desire.”
The mix of Spark, which is very good at data exploration, and MemSQL, which offer lightning fast SQL queries and ACID compliance, will be a boon to customers, Orenstein says. “There’s a really good fit between MemSQL and Spark in that we’re both in-memory distributed architectures,” he says. “When the connector is in use, it’s not a single-threaded stream—it’s actually parallel processing from one data set to a second data set across multiple nodes in the cluster. That kind of throughput and performance is what gives the combination the extra boost.”
Sparking in the Real World
Besides speed, ease-of-use is the benefit most often cited by Spark adopters. Anybody who is proficient in Scala can utilize the Spark APIs to access Spark’s capabilities, whether it’s the machine learning library (MLlib), SQL processing, stream processing (via Spark Streaming), or newer engines like graph processing engine (GraphX), and an R environment (Spark R).
Event stream processing is currently the most common use case for Spark, according to a recent survey on Spark conducted by Typesafe, followed by ETL, ad hoc queries, writing data to HDFS, and conducting SQL queries. Among customers who are using Spark for event stream processing, 71 percent of respondents are using Spark as part of a larger data pipeline, 65 percent are using Spark to extract data more quickly, while only 40 percent are using it to automate decision making at runtime.
 Interestingly, the majority of Spark implementations are run on stand-alone clusters, according to the survey, which involved more than 2,000 users. Forty-two percent say they’re running Spark on YARN (i.e. Hadoop). Slightly less popular was Mesos, the data center resource manager that was developed alongside Spark at Cal Berkeley’s AMPLab, while Cassandra rounded out the Spark deployments with 20 percent.
Interestingly, the majority of Spark implementations are run on stand-alone clusters, according to the survey, which involved more than 2,000 users. Forty-two percent say they’re running Spark on YARN (i.e. Hadoop). Slightly less popular was Mesos, the data center resource manager that was developed alongside Spark at Cal Berkeley’s AMPLab, while Cassandra rounded out the Spark deployments with 20 percent.
The diversity of where Spark runs and what it can do is a strength of the platform, according to Matei Zaharia, who is the CTO at Databricks and is widely considered the father of Spark.
“This survey of over 2100 developers alone highlights that over 500 enterprises using or planning to use Spark in production in 2015, in environments ranging from Hadoop clusters to public and private clouds, with data sources including key-value stores, databases, streaming data and file systems,” Zaharia says in the report. “Their use cases range from batch workloads to SQL queries, stream processing and machine learning, highlighting Spark’s unique capability as a simple, unified platform for data processing.”
Related Items:
Apache Spark and Java 8: The Big Data Team for 2015
Spark Just Passed Hadoop in Popularity on the Web–Here’s Why
Put a Data Warehouse In Your Operational Data Store, MemSQL Says
Leading Solution Providers

















