

July 13, 2015
Python Versus R in Apache Spark

The June update to Apache Spark brought support for R, a significant enhancement that opens the big data platform to a large audience of new potential users. Support for R in Spark 1.4 also gives users an alternative to Python. But which language will emerge as the winner for doing data science in Spark? We spoke to Databricks Ali Ghodsi for answers.
According to Ghodsi, who is Databricks’ vice president of engineering and product management, the company has been bombarded with requests over the past year or so to add support for R in Apache Spark. While the software is open source, about three quarters of the framework was written by people who work for Databricks, so it basically controls the direction of Spark.
The outcry for R in Spark was loud and consistent. “I’m shocked by the number” of requests, Ghodsi tells Datanami. “There’s been this explosive growth, especially in the last year, for doing data science in R. I, for one, couldn’t understand where it’s coming from.”
Ghodsi researched the matter, and concluded that much of R’s growth stems from the fact that it’s become the main statistical language taught in colleges. “When people would go to school and take psychology and biology classes, back in the day they’d be taught SPSS or SAS,” he says. “Now they’re taught R. These are not necessarily people who have computing background, but the statistics they learn for talking to a computer is R.”
While R is a newcomer to Spark, it already has a solid number of users compared to the other languages that Spark supports, including Python, Java, and Scala. “Give it a year. I definitely think it’s going to be more popular than Scala and Java,” Ghodsi says. “I don’t know if it’s going to overtake Python or not. We’ve also invested a lot in Python.”
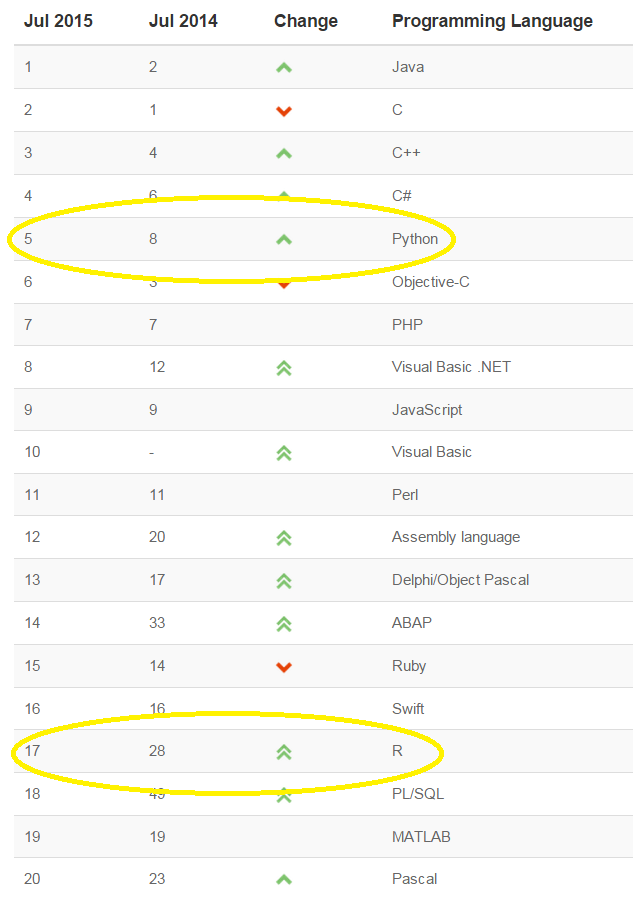
Source: TIOBE Index
Whereas R is growing in popularity across scientific disciplines, Python’s strength stems from its popularity within computer science as a general-purpose programming language. Interest in Python in booming, and not just among those practicing data science, but across all realms of computer science. According to the latest TIOBE Index, which measures the relative popularity of languages, Python moved up three spots within the last year to claim the number five spot. Meanwhile, R moved up from number 28 on the list to number 17.
The ease of doing statistics in R is driving that language’s popularity, Ghodsi says. “That’s one of the big attractions of R is all these built in statistics libraries, and also all these built-in plotting functions,” he says. “Python is closer to people with computing technology backgrounds. If you’re a programmer, or come from that background, Python might be more natural.”
It’s tough to forecast which language—R or Python—will win in the end. “Clearly these are the two popular languages that people want to do when they do data science,” Ghodsi says. “R has been growing faster. I’m not sure about absolute numbers, which one will win….[But whether] you’re a Python person or an R person, it’s making it simpler and lowering the bar for people to join and talk to their big data.”
Spark’s rocket to big data fame ignited about two years ago, and is fueled largely by how much easier and faster it is to use compared to MapReduce, which had been the go-to framework for doing big data science since the Hadoop train started rolling about 10 years ago. Not only does Spark let users program in languages besides Java, but it delivers a much more interactive experience than the batch-oriented MapReduce framework.
![]() The Spark framework is evolving at a fast pace, and one of the most important enhancements was the version 1.3 release of Dataframes, which is essentially a “smashup” of different statistical vectors, according to Ghodsi. It’s interesting that the Dataframes concept was originally developed within R, and the folks behind Spark saw how powerful that approach could be, so they copied it. The Python community also has its version of a Dataframe, which is embodied in the Pandas project. Spark today support both flavors of Dataframes, in R and Python Pandas, as well as Dataframes for Scala.
The Spark framework is evolving at a fast pace, and one of the most important enhancements was the version 1.3 release of Dataframes, which is essentially a “smashup” of different statistical vectors, according to Ghodsi. It’s interesting that the Dataframes concept was originally developed within R, and the folks behind Spark saw how powerful that approach could be, so they copied it. The Python community also has its version of a Dataframe, which is embodied in the Pandas project. Spark today support both flavors of Dataframes, in R and Python Pandas, as well as Dataframes for Scala.
Dataframes today supports Spark’s machine learning and SQL libraries, and will support the graph database and Spark Streaming libraries in the future. Eventually, Dataframes will be the main way that people interact with Spark, Ghodsi says. “One of the main ways you talk to Spark is Dataframes,” he says. “If you’re using R or if you’re using Python or even if you’re using Scala, there’s a Dataframe way you can speak to Spark.”
The Python-versus-R-in-Spark discussion also carries over to the production side of the equation. In the olden days of Spark (i.e. 18 months ago), putting a Spark job into production often required the user to re-write the job in a different language. So if the iterative data science, exploration, and discovery portion was conducted in Python, the developer might have to basically re-write those functions in Scala or Java to get it running at scale in production.
While Scala and Java may carry some benefits for running production jobs at scale, many users of Databricks hosted Spark environment are bridging that “DevOps” divide with the notebook feature in Spark. “One of the interesting features in Databricks is you can take a notebook that you interactively built out, and you can move it into production through a feature we have called Jobs,” Ghodsi says.
Ninety-seven percent of Databricks customers have adopted Spark’s Notebook features, according to Ghodsi. “People prefer the convenience of being able to go between production setting and interactive exploration, and then go back and use the same notebook they used to debug it, by interactively re-writing some of the queries in the notebook live,” Ghodsi says. “They really love that because it basically makes it easier. You don’t have to re-write the code from scratch in a packaged application that you upload to jobs.”
![]() In Apache Spark, users can interact with the notebook features using all the supported languages, no matter which specific Spark function they’re after, such as SQL or machine learning or streaming. When it comes to R, however, the MLlib machine learning library is not fully supported, which is something Databricks will be working on.
In Apache Spark, users can interact with the notebook features using all the supported languages, no matter which specific Spark function they’re after, such as SQL or machine learning or streaming. When it comes to R, however, the MLlib machine learning library is not fully supported, which is something Databricks will be working on.
Python remains the go-to language for data scientists doing machine learning in Spark, Ghodsi says. In many cases, the data scientists are spending lots of time doing data munging and cleaning before they get to the main machine learning problem they wanted to tackle in the first place.
“The first step before machine learning, you can classify as the ETL, or the feature-ization set,” Ghodsi says. “That’s the challenging part of machine learning that we’re seeing, and for that people love using notebook and they love using Python in particular.”
Python gives the data scientists more insight into the data prep process, he says. “You typically have some dataset that’s formatted in some weird way–maybe the different fields are split by commas, or date formats are off so you need to convert it to Greenwich time,” Ghodsi continues. “Python is great for…these kinds of manipulations , where you have to get the data into the right shape. And the reason you want to use notebooks for that is they want to interactively see as you’re making these manipulations. You don’t want to go off and write a program and them upload that program and run it on a big data set to see your result. That’s just too slow. You want to do this in real time.”
Spark’s position as a replacement for MapReduce seems cemented at this time. The in-memory framework is increasingly being adopted as the interactive data munging element in Hadoop clusters. With the addition of support for R—not to mention the recent backing of industry giants like IBM and Amazon Web Services–the framework is on the cusp of touching an even greater number of users.
Related Items:
Deep Dive Into Databricks’ Big Speedup Plans for Apache Spark
Apache Spark: Now Offered on Amazon EMR
IBM, Databricks Join Forces to Advance Spark
Leading Solution Providers

















