


August 31, 2015
Rethinking Enterprise Search for the Big Data Age

The humble search engine has retained a prominent place in the toolboxes of would-be data explorers. You see Solr and Lucene sitting at the Hadoop table, right alongside SQL and machine learning. But some search experts–including one who helped build Microsoft Bing–say traditional search engines are too long in the tooth for today’s big data challenges.
There’s no doubt that Internet search engines, such as Google and Bing, have changed how we retrieve information, says Donald Thompson, the co-founder and CTO of Maana and a long-time Microsoft developer. But when it comes to the enterprise search engines that companies often use to index and retrieve internal documents, there has been a major failure of innovation.
The problem is that enterprise search has failed to keep up with their consumer-grade cousins, Thompson tells Datanami. “Go to Bing and type in ‘Tom Hanks,'” he says. “You don’t just get Web pages with Tom Hanks. You get the entity experience of Tom Hanks. The search engine knows something about Tom Hanks.”
There’s no such innovation in enterprise search, he says. “There’s not even a page-rank level of innovation,” he adds. “It’s literally just term frequency and documents. They have done some faceting and things like this. But [it’s mostly] a very manual construct. You have to go in, a priori, and define your schemas.”
Enterprise Search Unchained
Thompson hopes to change that with Maana, the big data search engine company he founded about two years ago with Babur Ozden, its CEO. If anybody has the chops to tackle this problem, it would be somebody like Thompson, who founded Project Satori (the Bing knowledge and reasoning team) and was the leader of Project Arena, which shipped as the SQL Server 2012 Semantic Engine.
“Enterprise search has always been hobbled. It’s not their fault, but they’ve been hobbled by the fact that they’re just looking at hits and documents,” Thompson continues. “Even Splunk, which has a great product, is a hits-in-documents kind of approach…To me, this is entirely unsatisfying.”
 Instead of taking the bottom-up approach—looking for specific phrases in documents and counting the hits to rank them—Thompson proposes more of a top-down view that better meshes with how humans search for knowledge.
Instead of taking the bottom-up approach—looking for specific phrases in documents and counting the hits to rank them—Thompson proposes more of a top-down view that better meshes with how humans search for knowledge.
“What we want to do is navigate through the vast amount of data you’ll have in a big data environment, and allow you to filter down and explore and find the connections,” he says. “We don’t want to just index the website, like a library index of books. We want to learn and extract the information from multiple things we’re covering, and then roll them up into domain concepts that users are familiar with.”
Built On Spark
The company, which has offices in Washington, California, and Texas, is still in the midst of developing the Maama search engine. But the software, which is shipping now, has been tested at some of the world’s largest corporations. Their strategic investors include GE, Chevron, Intel, and Conoco Philips, which have invested a total of about $14 million in the startup.
The Maana Search and Discovery Platform, as its flagship search engine is called, is built on a modern Hadoop stack that leverages HDFS, the Accumulo graph database, Apache Spark, heaps of Scala code, and a host of various machine learning algorithms for teasing knowledge out of reams of unstructured data.
Converting data to knowledge is no easy task, and requires human supervision at the end of the day—most likely by data analysts and data scientists who are skilled at data modeling. But Maana can ride the algorithms as far as they can take them. “The problem of semantics hasn’t been solved by computer science,” Thompson says. “The algorithms aren’t magical but they can get you a long way toward your goals.”
The Maana user experience begins in a familiar manner: with a basic search bar. But instead of getting back a screen of links to diabetes, for example, the system embarks on a series of disambiguations in an attempt to refine the search’s intent.
These filters are key to how Maana works. “Say you were interested in a diagnosis of diabetes in your patients, so you’d want patients related to diabetes,” Thompson says. “That’s the concept you’re looking for. Maana shows you a roll-up or summary of patient information who have been diagnosed with some form of diabetes, so you can see the demographics, age ranges, time diagnosed, locations around the world they may have been diagnosed.”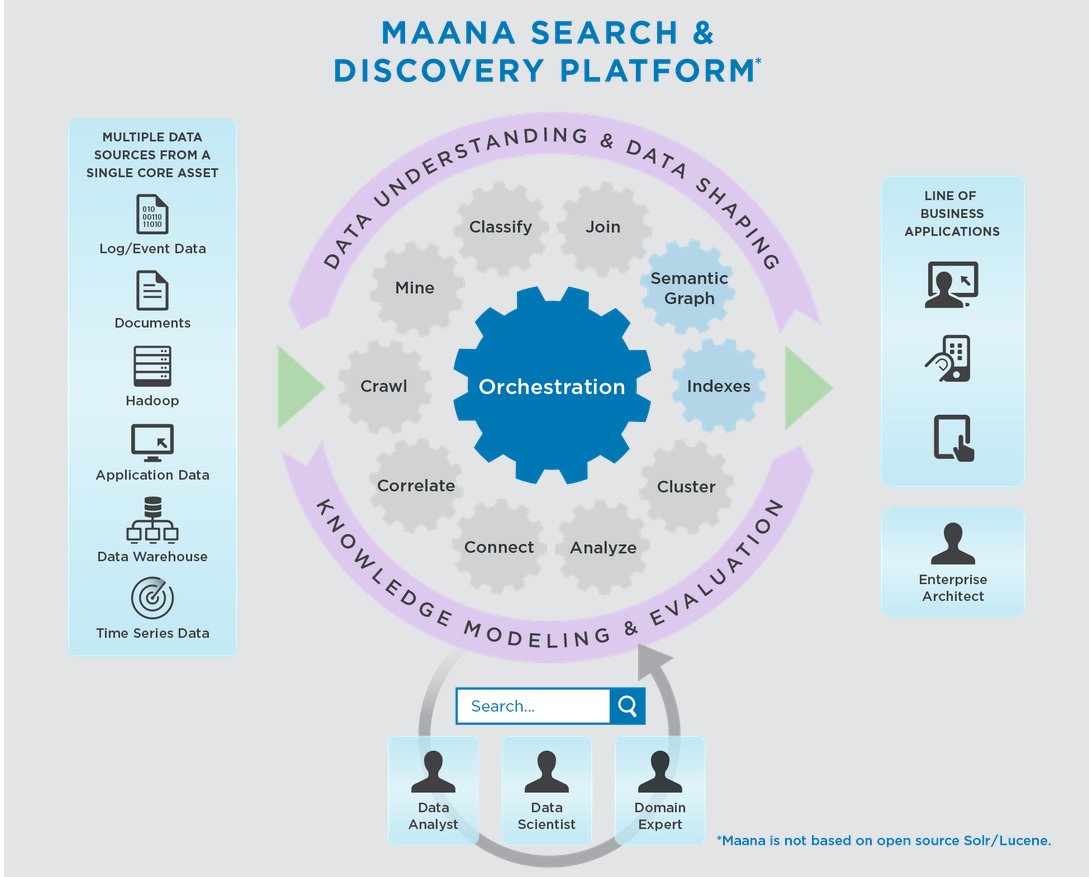
Each search experience will be different, depending on the industry. The healthcare industry is rife with structured data, such as ICD9 and UML data sets. That’s not the case in the oil and gas industry, where the most important pieces of information are unstructured and relate to things like oil wells, drill bits, seismic data, sensor data, and superintendents.
“You can tell Maana, ‘I want to know all pieces of equipment that have led to most unplanned downtime,”” Thompson says. After telling it to look in the Gulf and entering the appropriate EQP code, the system returns of histogram of pieces of equipment with the most amount of downtime. “So you get very quickly through a simple search and filtering operation a visual representation of the underlying data.”
In this manner, Maana can join multiple disparate data sets and enable users to search and discover data across them in a semantic method. “It’s very simple to navigate the entire information space, which may be being fed from many different sources simultaneously,” Thompson says. “But you’re working at level of domain concepts.”
Rethinking Search
Organizations are storing all types of big and messy data in their Hadoop systems, and the challenge has become how to effectively mine that data lake for business value.
In some cases, the right approach may be the SQL route, which involves hammering the data into more-structured data types reminiscent of enterprise data warehouses, while other times setting machine learning algorithms loose to find patterns in the data that reflect correlating conditions in the real world is the right approach.
Thompson thinks search still has a lot left to offer. “Search is a great paradigm,” he says. “People are familiar with it. It’s a great starting point for an exploration. But the search experience needs to radically change from the document-centric approach.”
Today’s enterprise search engines don’t stand up well to the big data challenges that organizations currently face. “The reason they never took a data-driven approach [to search] is it has been too cumbersome and daunting for them to go off and find the hundreds of places that data might live,” he says. “Maana has basically solved that problem.”
Related Items:
Solr or Elasticsearch–That Is the Question
Here’s Another Option for Hadoop Enterprise Search
Under New CEO, Lucidworks Aims to Redefine Search and Itself
Technologies:
Middleware
Leading Solution Providers

















