


September 29, 2015
MapR Gives Hadoop Distro More NoSQL Smarts
Hadoop and NoSQL databases share some similarities, but the platforms typically live within different levels of the big data spectrum. Now MapR Technologies is working to break those barriers down by adding a major piece of NoSQL functionality to its Hadoop distribution.
At the Strata + Hadoop World conference today, MapR Technologies announced that it’s now supporting the storage of JSON documents in MapR-DB, the enterprise NoSQL data store that ships with its Hadoop distribution. As a spruced up version of the HBase key-value store, the MapR-DB has always provided some NoSQL functionality, particularly for serving large amounts of randomly accessed data, which is not something HDFS is particularly good at doing.
But the addition of a JSON document store gives MapR’s distribution of Hadoop the same basic functionality as you’d find in commercial document-oriented NoSQL databases, such as those from MongoDB or Couchbase. (The MapR-DB already had wide-column NoSQL functionality, which is most visibly implemented in the Apache Cassandra NoSQL database.)
“What we’re announcing is the first in-Hadoop document database,” says MapR chief marketing officer Jack Norris. “It has quite a number of benefits. You’re going to see a number of developers using JSON today jump at a scalable JSON solution.”
Norris identified several ways they could gain competitive advantages by adopting the native JSON data store in its Hadoop distribution. For starters, it scales better than the document-oriented data stores.
“It picks up where some of the tools today have well-understood scalability issues,” he says. “You can take Mongo output and put it into MapR quite easily. The issue is…running Mongo on Hadoop doesn’t do anything to change the scale issue of Mongo. You still have the issue of, how does it effectively scale when the processing exceeds memory, and so forth. So there are some issues that don’t go away just by running Mongo on the same nodes as Hadoop.”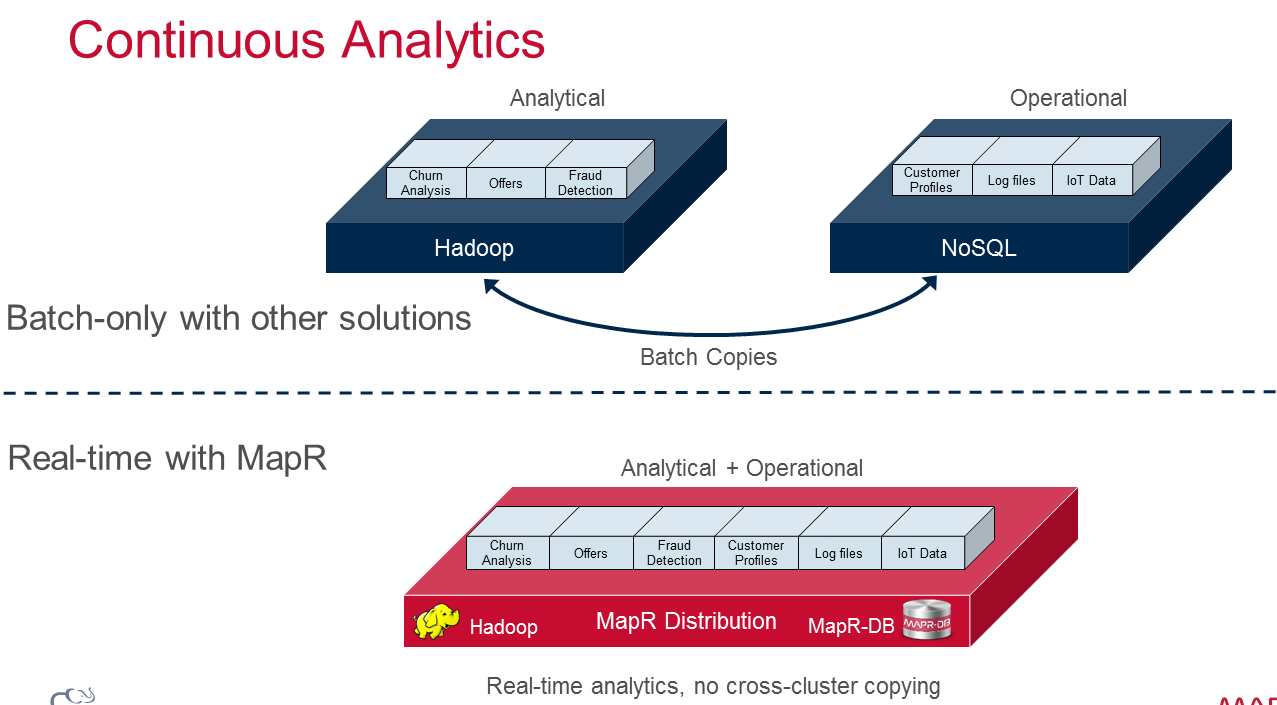
Norris says the new JSON data store will also help to “collapse the cycle” of insight by removing barriers between the two types of storage and processing mechanisms.
It’s common for customers to use both Hadoop and NoSQL databases and to move data back and forth between them. While Hadoop excels at finding insights hidden in data, those insights are useless unless they’re implemented in some way. In many cases, the business insights are often implemented via NoSQL databases, which are the scalable backend systems of record for modern Web and mobile apps.
“Instead of taking that data [from operational systems] and shuffling it off to another platform and other solutions that focus more on the analytic aspects, you’re able to do that in the same cluster,” Norris says. “It’s about providing the flexibility and agility to organizations as they leverage things and being to do the analyses in place without having” to move the data to different platforms.
Having a JSON data store integrated so closely into Hadoop will also make life easier for developers, he says. “We’ve seen a lot of excitement from developers,” Norris says. “They say ‘If you have native JSON support then I don’t have to serialize things–I can leverage this directly and it just saves a lot of time and moving parts.’ We think this is going to be very impactful.”
MapR has already offered some support for JSON, most notably as a data format used by Apache Drill, the SQL query engine that it sponsors. But the new support for JSON inside MapR-DB is a whole different ballgame.
“If you look at what’s going on in organizations, JSON as an output is really exploding,” Norris says. “It’s become the defacto data interchange format for Web apps. It’s an output of many IoT machine generated sources. It’s definitely one of the fastest growing data sources, and the ability to leverage that directly, without requiring IT processing as a precursor–that’s significant.”
MapR sees the JSON data store being implemented in a number of different industries. In the Web and retail worlds, it could help integrate analytics with operational systems, such as by serving real-time insights or highly personalized and targeted ads to Web and mobile customers. It could also be used to help detect of fraudulent transactions in real-time at the time of purchase, thereby putting a stop to fraud.
MapR did a survey recently that found that 18 percent of users had 50 or more applications running on a single Hadoop clusters. “One of the big advantages of Hadoop is to reduce the sprawl of data silos,” Norris says. “Then you look at some of the environments where you have separate Hadoop and separate NoSQL or HBase clusters, and the batch extract and loading between them. You’re kind of replicating some of the application silos that existed previously.”
Adding a JSON document to the Hadoop cluster could help to tamp down the data-sprawl problem. “That really drives agility and lowers total overall cost and makes data more impactful in an organization,” he says.
The JSON data store supports the Open JSON Application Interface (OJAITM), a general purpose JSON access layer. MapR’s implementation features bindings for Java, Python, and Node.js. MapR shipped a developer preview of the JSON store last week that contains the bindings, the API, and sample code.
When it’s ready for GA (general availability), which is expected by the end of the year, MapR’s JSON data store will be available in all editions of its Hadoop distribution, including the free community edition. Customers buying the enterprise version will get advanced features, such as support for replicating JSON data among clusters running in different data centers.
Related Items:
MapR Targets Hadoop’s Batch Constraints with 5.0
MapR Delivers Bi-Directional Replication with Distro Refresh
Technologies:
Frameworks
Leading Solution Providers

















