


October 19, 2015
Teradata Puts Aster in Hadoop for IoT Analytics

The Internet of Things (IoT) is simultaneously a colossal data management challenge and the analytic opportunity of a lifetime. Teradata (NYSE: TDC) addressed both of those today with two product announcements, including an Apache Kafka-based applications for routing IoT data into Hadoop, and the introduction of a Hadoop-native version of its Aster analytics suite.
The rapid proliferation of connected devices is changing how we view and interact with the world around us. From smart phones and intelligent thermostats to smart semi-trucks and industrial appliances, the rapid growth of the IoT—projected by Cisco CEO Chuck Robbins to go from about 15 billion devices today to 500 billion by 2030–will test our ability to make sense of data.
Teradata hopes to be at the forefront of this big data opportunity with a pair of products it unveiled today at its Teradata 2015 PARTNERS conference in Anaheim, California. The first product, called Listener, will help customers get a handle on the massive flow of real-time data.
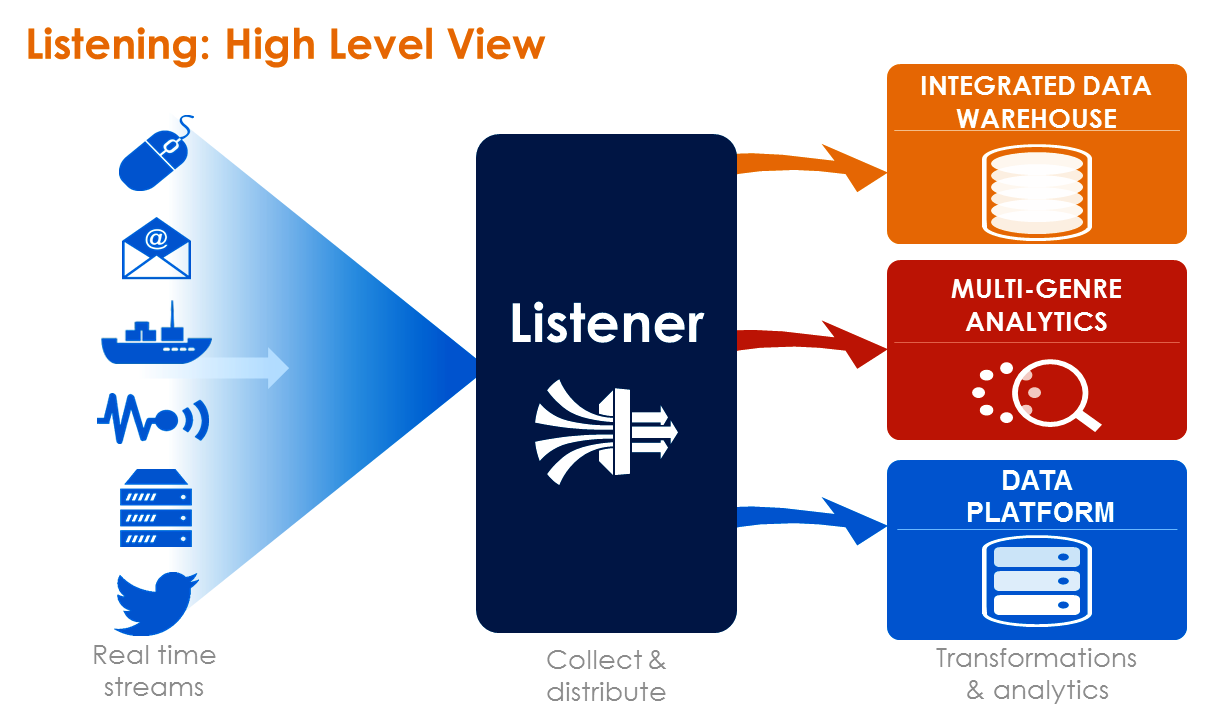
Source: Teradata
“Listener is an intelligent self-service platform for collecting real time data form multi system at high volume and then propagating it out to analytical ecosystem for doing analytics,” explains Chris Twogood, Teradata’s vice president of product and services marketing. “It’s built on top of a number of open source technology components, including Kafka for ingestion, ElasticSearch for metrics, Cassandra for configuration, and it’s all built on Mesos and Docker containers and microservices” for fast deployment.
Getting Listener hooked up and feeding data to an application is as simple as pasting an API into the application’s code base, Twogood says. More often than not, he says, that application will reside in Hadoop, although Listener can also point to more traditional analytic platforms, such as the Teradata Database or other SQL-oriented data stores.
“We believe a lot of IoT data will be captured in the Hadoop infrastructure,” Twogood continues. “Hadoop is good for storage, but we’re still seeing challenges of broad usage of getting value from the data in Hadoop. There’s a lot of great tools on Hadoop but a lot of them are really designed for data scientists, so having Aster natively in the Hadoop infrastructure” will help address that demand.
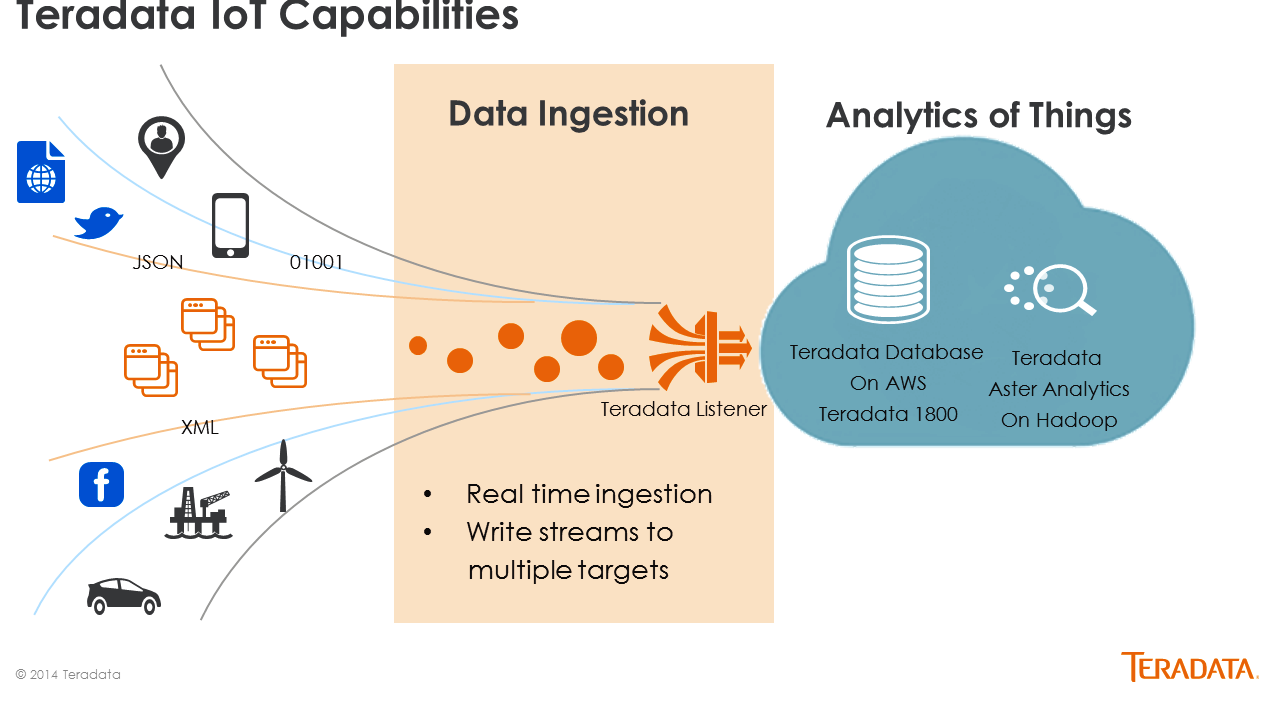
Source: Teradata
Aster is a big data analytics and discovery solution that Teradata acquired in 2011. The software is designed to enable non-data scientists to explore and analyze big data sets through a combination of techniques, including text analytics, graph analytics, and machine learning. The software, designed 10 years ago to run on distributed clusters of commodity servers, presents a visual interface to the user, who need only know SQL to be productive with the system.
Getting Aster supported on Hadoop is the second major IoT-related announcement Teradata made at its conference today. Previously, Aster customers who wanted to analyze data stored in Hadoop would have to move that data to Aster, which ran on a dedicated appliance, on a separate X64 cluster, or in a cloud. That requirement to move the data is anathema to today’s big data ethos, and caused many potential Aster customers to look elsewhere for software.
But now that Aster is running natively on Hadoop—and letting YARN manage resources for it and using HDFS to read and write data—that should open the number of use cases for Aster, Twogood says. “Having Aster natively in the Hop infrastructure means now you can have data analysis running machine learning algorithms at scale, whether that’s MPATH or K-Means or MinHash,” he continues. “We have 150 [algorithms] that invoke our SQL, graph, and MapReduce engines for doing this broad set of analytics.”
Teradata had to make some tweaks to the Hadoop implementation of Aster to address some of HDFS’s shortcomings around handling data updates and inserts on fast-moving data, but that work is done and Aster will be supported on the Hadoop distributions from Hortonworks (NASDAQ: HDP) and Cloudera.
“Now it runs on Hadoop as a native, first-class engine just like Spark or Giraph or Hive or Impala,” Twogood says. “It’s all about making the core capabilities of IoT more accessible to a broader set of users.”
Both new products–Listener and Aster running in Hadoop–are expected to be available in the first quarter of next year.
(feature image: a-image/Shutterstock.com)
Related Items:
AWS Cloud Pact Shows How Far Teradata Has Come
Teradata Edges Closer To Hadoop
Teradata Adds Graph Engine to the Data Discovery Mix with Aster 6
Tags:
Aster, big data, cassandra, cloud Teradata Database, Data Analytics, Docker, elasticsearch, Hadoop, iot, Kafka, machine learning, Mesos, Spark
Leading Solution Providers

















