


September 26, 2016
MemSQL Delivers an ‘Exactly Once’ Real-Time Pipeline

MemSQL today unveiled a new release of its in-memory relational database that can process a real-time flow of messages from Apache Kafka using “exactly once” semantics. The NewSQL database accomplished the feat by creating a new “Create Pipeline” SQL command, and in part by bypassing Apache Spark.
Like many vendors in the big data space, MemSQL is seeking to help customers to process large amounts of streaming data arriving from Web logs, devices, and sensors on the IoT. Much of this data has been processed in batch, but real advantages can be had in customer 360, fraud detection and other initiatives by processing the data continuously.
To that end, MemSQL last year unveiled its “Spark Streamliner” initiative, in which it incorporated Apache Spark Streaming as a middleware component to buffer the parallel flow of data coming from Kafka before it’s loaded into MemSQL’s consistent storage. This enabled customers like Pintrest to eliminate batch processing and move to continuous processing of data.
But drawbacks with that approach—specifically, the difficulty in getting to “exactly once” processing of incoming data—led MemSQL to seek a better solution. The best that the Streamliner initiative could do was “at-least once” processing or “at-most once” processing, but those approaches had drawbacks in balancing process guarantees and resource consumption, says MemSQL’s chief marketing officer Gary Orenstein.
“With at-most once, what you’re doing is you’re pulling a message across once. You may or may not get it guaranteed. But the one thing you’re not doing is you’re not pulling extra bandwidth or storing duplicates,” Orenstein says. With at-least once processing, you’ll likely pull the message more than once. “You get guaranteed receipt. But you’ll use a lot of bandwidth and there could be duplicates.”
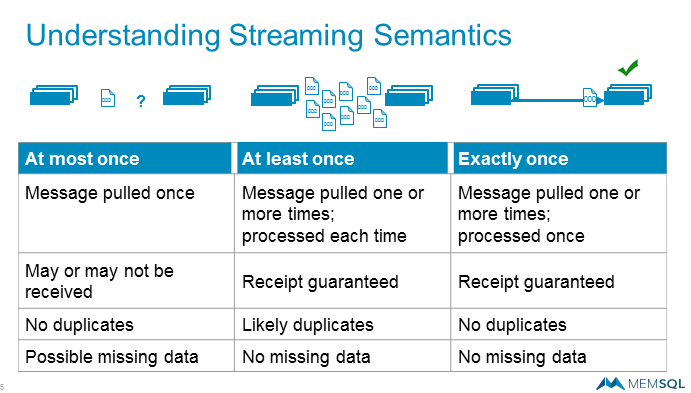
Image source: MemSQL
Getting exactly-once processing has been the “Holy Grail” of real-time processing, Orenstein says. Since Kafka doesn’t deliver it out of the box, he says, it’s up to other parts of the real-time stack to deliver it. That’s what MemSQL is delivering with version 5.5 of its NewSQL database, he says.
“It’s been challenging because you not only have to capture the data but you have to capture the offset so you can handle errors or for stopping or restarting the pipeline,” Orenstein explains. “If you have to store the offset in another database, it becomes extremely hard to manage. With MemSQL, we’re a transactional, durable, persistent relational database, so we can use MemSQL itself, not just to capture the data, but to manage the offset and the error condition. This co-location is what enables the exactly-once semantics.”
Having a bit of processing overhead or losing a few messages isn’t critical in many situations, such as when you’re analyzing billions of Web sessions to feed a machine learning model, for instance. But in MemSQL’s vision, emerging business-critical use cases–such as ensuring the flow of real-time financial data to stock traders or processing customer orders in an ERP system–do not give developers the luxury of saying “well that’s good enough.”
“Today when people look at streaming, they often think about sensor on IoT items, where missing a data point or two might not be a challenge,” Orenstein says. “But if you’re building and architecting enterprise applications or reporting on customer environments, you don’t have that option. If you want to move to a streaming solution, you’re going to need to have that kind of exactly-once guarantee to build those critical applications.”
The exactly-once semantics are enabled through the new “Create Pipeline” command in MemSQL version 5.5. The command will automatically extract data from the Kafka source, perform some type of transformation, and then load it into the MemSQL database’s lead nodes (as opposed to loading them in MemSQL’s aggregator nodes first, as it did with Streamliner). The database can work on multiple, simultaneous streams, and while adhering to exactly-once semantics.
![]() MemSQL is still working with Spark. The company isn’t unhitching from that boat. Spark is still a great thing to have, particularly for those customers who need the richness of the Spark libraries, Orenstein says. But for a certain class of emerging real-time streaming apps, and for doing operational analytics upon fast-flying data, a streamlined architecture will often be preferred.
MemSQL is still working with Spark. The company isn’t unhitching from that boat. Spark is still a great thing to have, particularly for those customers who need the richness of the Spark libraries, Orenstein says. But for a certain class of emerging real-time streaming apps, and for doing operational analytics upon fast-flying data, a streamlined architecture will often be preferred.
“We see a big shift happening in adoption of streaming in classic enterprise workloads that have been too focused on batch processing, and for these customers to move forward with digital transformation, customer 360 initiatives, and IoT activity, which is generally based on real-time mobile phone input–they’re going to need to move to a streaming solution.”
MemSQL will be showing off version 5.5 at the Strata + Hadoop World conference this week. It will also have the benefit of Dell/EMC chief platform architect Darryl Smith, who will talk about how Dell/EMC is using MemSQL to deliver a personalized customer experience for data flowing out of its data lake.
“It’s been a challenge for folks, but this is the big capability we’re introducing with MemsQL 5.5,” Orenstein says. “In our opinion, this will represent a turning point for the way the industry looks at streaming.”
Related Items:
Put a Data Warehouse In Your Operational Data Store, MemSQL Says
Vendors:
MemSQL
Leading Solution Providers

















