


February 1, 2017
Solving Storage Just the Beginning for Minio CEO Periasamy
Yesterday marked the first day of general availability for the free and open source object storage system from Mino. But as Minio co-founder and CEO AB Periasamy explains, delivering the deceptively simple, S3-compatible file system is just a prerequisite for doing what he really wants—using deep learning techniques to extract insight from massive piles of unstructured data in new and powerful ways.
You may recognize the name Anand Babu (AB) Periasamy as one of the creators of GlusterFS, the scale-out file system that Periasamy and Gluster co-founder Hitesh Chellani developed in the early 2000s after they both spent time at California Digital Corp. building the Itanium-based “Thunder” supercomputer for Lawrence Livermore National Lab.
Gluster’s performance advantage over other file systems like Luster and GPFS attracted some big customers in the private sector that needed to move big data in big ways, like Pandora, Deutche Bank, Samsung, and BAE Systems. After Gluster was acquired by Red Hat in 2011 for $136 million, Periasamy stayed on with the company to help with the integration.
But ever the restless hacker, Periasamy wanted to create again, and so in 2014 he co-founded Minio with the idea to “solve storage.”
Storage Solved?
In a far-ranging interview with Datanami last week, Periasamy explained his minimalist design goals with Minio, his disdain for massive global namespaces, his appreciation for what Amazon Web Services has accomplished with S3, his dreams of massively multi-core ARM chips, and his ambitious plans for building a new deep learning engine, fittingly dubbed X.
The idea for “Minio,” which roughly stands for “minimalist object storage,” was to give the world a simple but capable file system that allows users to easily store large amounts of immutable data, such as pictures, video files, audio recordings, and the like. “Minio solves the cost of storage, and the frustration,” he says.

AB Periasamy is the co-founder and CEO of Minio
Object storage systems are the best approach for storing the huge amounts of unstructured data that the world will create over the next five to 10 years, according to Periasamy. However, the current crop of object storage systems, including both open source system like Ceph and OpenStack and proprietary affairs like Scality and IBM’s Cleversafe, are too complicated, he says.
“Storage still is very much complicated. The skills required to set up Open Stack with Ceph–that kind of complexity, you clearly cannot scale,” he says. “An object storage server is typically just a Web server with an API and it needs to store blobs of immutable data. There is really no good reason to complicate them.”
This is what Periasamy has strived to do with Minio: uncomplicate the object store. He describes Minio as “a ridiculously simple object store that looks like S3.” Whereas other object stores require advanced skills to set up, tune, and run, Minio is so simple that even application developers can use it.
Prospective Minio users can just download the binary and run, Periasamy claims. The object store, which was written in the language Go, lives within a container managed by Kubernetes, Mesos, or Docker. The Minio instances managed by the container are relatively small, at least by object storage standards.
“We purposely limited a single tenant into a manageable failure domain, that is 16 drives,” he says. “With 16 drives, you’re talking about…80 TB of usable capacity. It’s not a good idea to put all the eggs in one basket.”
When the 80TB is used up, the Minio user simply orders his container OS to create another instance of Minio. “There’s no scalability problem here because that provisioning of new Minio instance is a Kubernetes or Mesos orchestration problem,” he says.
Bye Bye, Global Namespaces
The relative simplicity of object storage systems is a godsend to those collecting big data sets. Because there is no theoretical upper limit, some object storage system deployments have extended to thousands of nodes, tens of thousands of disks, and upwards of 100PB of storage. Some of these are in a single global name space. But Perisamy is no fan of giant global name spaces.

Minio runs on containers, and features a cloud-native architecture
“There is no need for a global name space,” Periasamy says. “You can have 10PB of data in a single namespace. But that’s not a requirement in a cloud environment, because if you do all that, any update or security failure means huge downtime. Failure means you expose all the data. All the data is corrupted. So we deliberately avoided that by taking a different approach.”
Breaking up storage systems into smaller, more independent pieces may seem like taking a step backward, Periasamy acknowledges. After all, data silos are anathema to the big data theory that all data must be centrally stored—or at least connected logically—for the data to be analyzed and turned into useful information.
“But in reality, taking a step backward …allowed us to push it further,” he says. “In theory they [traditional object stores] are distributed, but in practice they behave like a monolithic system that are so rigid across many machines, and they want to do all the stuff themselves. When they fail, they fail in unpredictable ways.”
Keep It Simple, Stupid
Periasamy is clearly a big believer in the KISS theory, which holds that simplicity is a design goal in its own right, and that needless complexity should be avoided at all costs.
While much of the computing stack has been simplified, storage has not been a part of it. “Storage is the one part that is still complicated, expensive, and requires a lot of skills,” he says. “With Minio, we do one thing, and one thing very good. It’s not a string theory of storage.”

Minio already sports a number of customer logos
Periasamy makes no bones that Minio is modeled after the minimalism of Amazon and Simple Storage Service (S3). And it doesn’t hurt that S3 has also become the defacto industry standard protocol for object storage systems. “We want the rest of the world to have what Amazon has,” he says. “We want storage to become nearly free and simple and easy to use.”
Data is protected in Minio using erasure coding and bitrot protection. The deliverables include an SDK and a Web-based client, as well as Lambda functions that offer connections to other open source components, like Elasticsearch, Redis, PostgreSQL, AMQP, Kafka, and NatsIO.
Mino has been GA for just one day, but that’s a bit misleading, as the product has been used in production by quite a few organizations for a number of months. While IT products and projects inevitably grow in scope, Periasamy hopes to keep that growth to a minimum.
“We try very hard not to add new features,” he says. “Last year we removed a considerable amount of code. We honestly try to keep it minimal.”
While other file system projects may look to add features like decompression or encryption, that’s clearly not in Minio’s future. “By the time we reach version 4 or 5, in the enterprise space, it becomes a more complicated product, and then we have training and certification,” Periasamy says. “That’s certainly a route we do not want to take.”
The X Factor
Whether or not Minio will solve the storage crunch is debatable. After all, the product has been GA for just a day. It sounds promising, but the market will ultimately determine if Periasamy was successful in his quest to radically simplify object storage systems.
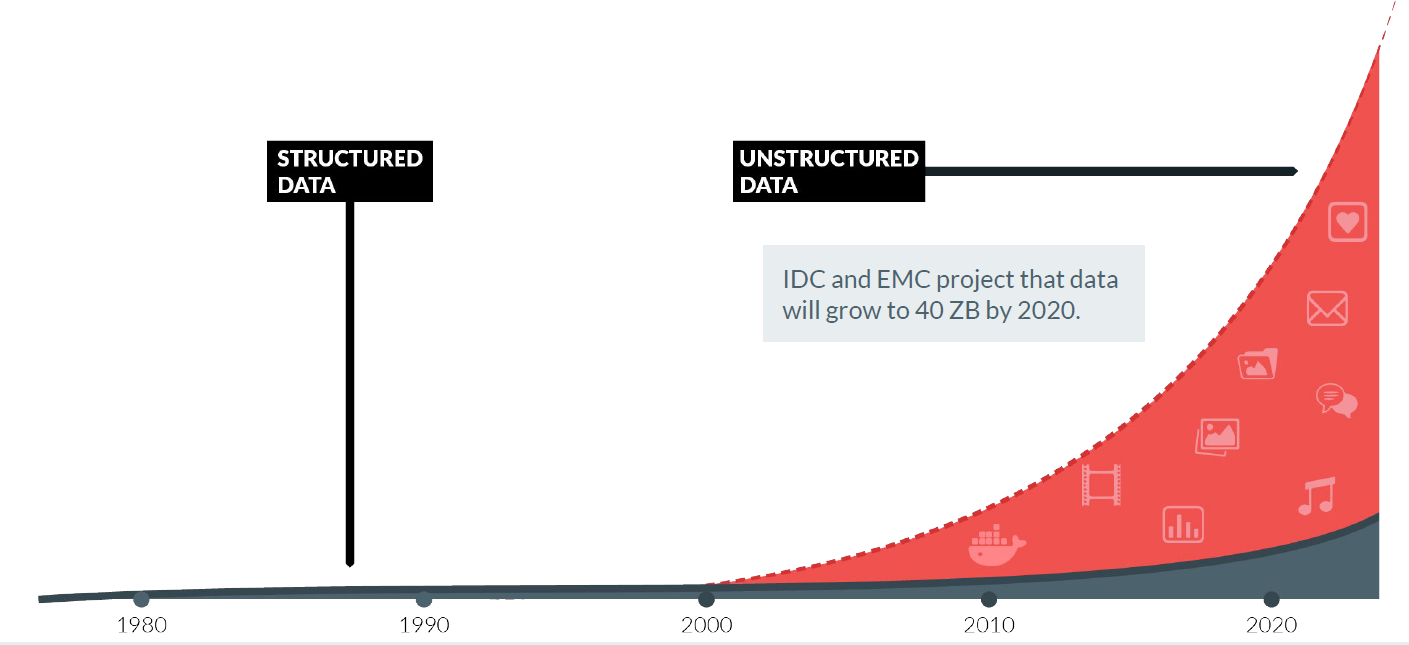
The growth of unstructured data threatens storage (Source: Human Compuer Interaction % Knowledge Discovery)
But all this is beside the point, to a certain extent, as Periasamy has bigger fish to fry. “We wanted storage to be free so we can capture more data,” he says. “We never saw ourselves as a storage company. The value is in data.”
This is where his new project, dubbed X-Ray, comes into play. Just as x-ray machines let doctors see the bones hidden beneath the skin, Mino’s X-Ray lets data scientists see inside an object stored in the file system.
“What good is it if we can store billions of photos, but we can’t really understand what it is, what the photos are?” he asks. “Without any context of the data, it’s merely useless.”
X-Ray will use deep learning techniques to automatically extract useful information from unstructured objects stored in the Minio file system, such as photos, videos, and audio recordings. “There are rich application you can produce, smart apps, once you understand what’s inside the object,” he says.
Analyzing Video
This is particularly true in burgeoning field of video storage and analysis, which IBM predicted in 2016 would be a $100 billion business over the next three years. Periasamy hopes to be at the forefront of developing the next generation of deep learning techniques for analyzing video data.

Minio’s second phase revolves around deep learning and X-Ray
“The current deep learning technologies are not good enough to understand streaming video content,” he says. “It requires a lot of pre-training and only known objects can be found. So we are actually working on a newer technique…so we can do streaming, real-time detection of objects using unsupervised learning.”
There are a number of potential uses in the real world for combining smart deep learning with an ultra cheap storage system. For example, a video surveillance system could be set up to only store video segments in Ultra-high definition (4K) when there’s a person in the field of view, and to store everything else in a low definition format to save space. (Despite the cost advantages of Minio, storing all content at 4K levels is not economically feasible.)
The OpenCV computer vision library is a good starting point for X-Ray, which will include OpenCV. “OpenCV already has the framework to understand streaming video content,” Periasamy says. “It’s a great start for us. Where we want to end up is not just straight forward (video) stream.”
Hardware Evolution
While Periasamy works on the software side of things, he sees much of the advances needed to fulfill his goal coming from hardware vendors.
“Intel Xeon Phi looks promising. NVIDIA GPUs are promising too, but they’re promising only for a certain category of work we are doing,” he says. “A 1,000-core ARM chip meant for deep leering would be great, but they don’t exist.”

Periasamy would love to see a massively multi-core ARM chip dedicated to deep learning workloads. “But they don’t exist today.”
There’s a certain amount of hype connected to deep learning at the moment. The prospect of training intelligent machines on deep neural networks has shown a lot of promise in the lab, on the Web, and in the street, where self-driving cars are nearly a reality.
But the real breakthroughs—the ones where intelligent machines are reliable and pervasive and easy enough for one’s mother to use–won’t happen for at least five years, Periasamy says. CPU architectures will need to be adapted for the new deep learning paradigm, and that will take time.
Until then, Periasamy will keep his eye on the big data ball, and be confident in his assertion that the true value of data will eventually be more easily extracted.
“Information is the new currency,” he says. “The value is in data. It’s almost like the energy industry. The energy that came out of oil powered the world. Computing will become like that. Computing will become a commodity, and the companies that extract information from data will be the Chevrons of the world.”
Related Items:
Analyzing Video, the Biggest Data of Them All
Tracking the Ever-Shifting Big Data Bottleneck
Software-Defined Storage Takes Off As Big Data Gets Bigger
Applications:
Artificial Intelligence
Tags:
AB Perisamy, amazon, ARM, deep learning, global namespace, gluster, GPU, Intel Phi, Minio, multi-core, Object Storage, object stores, s3
Leading Solution Providers

















