


February 9, 2017
Exactly Once: Why It’s Such a Big Deal for Apache Kafka

Organizations building real-time stream processing systems on Apache Kafka will be able to trust the platform to deliver each messages exactly once when they adopt new Kafka technology planned to be unveiled this spring, executives with Confluent tell Datanami.
While Kafka has emerged as a powerful and capable platform for building real-time streaming applications, it has lacked a key architectural feature that enterprise customers are demanding, Confluent co-founder and CTO Neha Narkhede says.
That feature–exactly once guaranteed delivery of messages hitting the queue–is being developed right now and will be fully enabled by the time Kafka Summit takes place in New York City this May.
Exactly once processing is a really big deal, Narkhede says. “Getting exactly-once guarantees at scale is not an easy problem,” she says. “It’s a distributed systems problem that some of our best engineers have worked on and what our Kafka community is most looking forward to this year.”
Distributed systems typically can offer several levels of guaranteed message delivery, including at-least once processing, at-most once processing, and exactly once processing. Current Kafka users often deploy the distributed message platform with an at least-once guarantee, which guarantees that the message will be sent, but with the caveat that it’s possible some messages may be duplicated.
“There are cases where you can get the same message twice. This is a very typical distributed system problems to solve, which is that networks are unreliable,” Narkhede says. “When you publish a message and you don’t hear back, you either lost it or you didn’t, and so you try to send it again and that’s when you introduce a duplicate.”
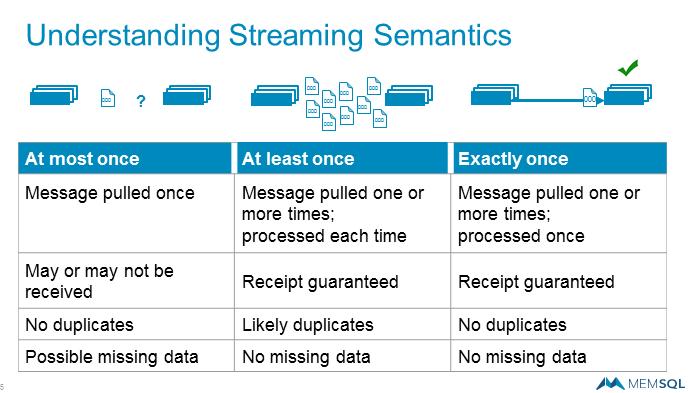
Exactly once processing is the “Holy Grail” of real-time computing (Source: MemSQL)
Having duplicate data is not a major problem for many applications, such as for sending friend requests on a social media platform like LinkedIn, which is where Narkhede and her Confluent co-founder, CEO Jay Kreps, originally developed Kafka.
But there are other applications where duplicate data is a deal-breaker, most notably in financial services. Large enterprises, including banks, are starting to use Kafka to feed fast-moving data into system-of-record applications, such as billing systems. Needless to say, the possibility duplicate data is a big concern for CIOs at these companies.
At-least once processing also consumes more bandwidth and computer resources than other approaches. If resources are constrained, users may opt to use an at-most approach to delivering messages. However, at-most once processing carries the possibility that the message may not be delivered at all, which introduces its own set of problems.
Up to this point, Kafka users have gotten around this limitation by coding guarantees directly into the applications. But that is not a good long-term solution for Kafka or the company developing it, Confluent, which has big plans for Kafka becoming a core architectural component of the emerging real-time streaming data world.
“It’s a pretty hard problem,” Narkhede continues. “Right now the only way to solve it on top of Kafka has been solve it in the application and have every message have a unique identifier. But that puts a lot of burden on the user, which we don’t want.”
Other software vendors have taken up the exactly once torch. Last September, MemSQL unveiled a new release of its NewSQL database that offered exactly-once guarantee of data flowing in via the Kafka pipeline, and landing in its relational database. The approach requires some additional processing within the database, but it conceals the complexity from the user.
Uber is taking a similar approach with Chaperone, a new auditing tool for Kafka that it released on GitHub last month and is available as open source. With Chaperone, Uber uses a write-ahead logging (WAL) approach to guarantee that data hitting the Kafka que is read only once for the purpose of auditing.
![]() Such approaches work, but they add complexity. Confluent is keen to keep the complexity low as Kafka gains traction in enterprise environments. Narkhede says Confluent has customers in one-third of the Fortune 500, and recently replaced Oracle‘s GoldenGate change data capture (CDC) in a production setting, which was the source of great excitement within the big data startup.
Such approaches work, but they add complexity. Confluent is keen to keep the complexity low as Kafka gains traction in enterprise environments. Narkhede says Confluent has customers in one-third of the Fortune 500, and recently replaced Oracle‘s GoldenGate change data capture (CDC) in a production setting, which was the source of great excitement within the big data startup.
Getting exactly once capabilities within Kafka will become even more important as the IoT begins to flourish and real-time streaming spreads. Narkhede brings up another use case revolving around ad tech business.
If you’re using Kafka to count ad impression, then you’d want it to be pretty accurate. “In fact, you’d want it to be perfectly accurate,” Narkhede says. “And this is what we are enabling. You can count in real time whether small or large scale, and that will give you the perfect answer, not the somewhat accurate answer.”
Narkhede has scoped out the solution with Kreps and the engineering team at Confluent, and the company’s best engineers are currently working on the problem. Confluent plans to offer exactly-once guarantees of message deliveries in a new release of the open source Apache Kafka platform next month, and exactly-once guarantees for the entire data pipelines running at scale around the May timeframe.
“What we’re enabling is end-to-end exactly once guarantee….and being able to do that in the event of any failures that are possible,” she says. “It behooves us to solve the complete problem end-to-end, and we believe we have a truly innovative solution.”
Related Items:
Commercial Kafka Distro Gets Global Smarts
Fresh Streaming Data: Get It While It’s Hot
MemSQL Delivers an ‘Exactly Once’ Real-Time Pipeline
Leading Solution Providers

















