


February 14, 2017
Here’s What a Neural Net Looks Like On the Inside
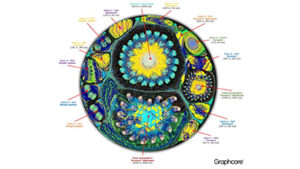
(Image Source: Graphcore)
Ever wonder what the inside of a machine learning model looks like? Today Graphcore released fascinating images that show how the computational graph concept maps to a new graph processor and graph programming framework it’s creating.
Graphcore is a UK-based startup that’s building a new processor, called the Intelligent Processing Unit (IPU), which is designed specifically to run machine learning workloads. Graphcore says systems that have its IPU processors, which will plug into traditional X86 servers via PCIe interfaces, will have more than 100x the memory bandwidth than scalar CPUs, and will outperform both CPUs and vector GPU for emerging machine learning workloads for both training and scoring stages.
The company is also developing a software framework called Poplar that will abstract the machine learning application development process from the underlying IPU-based hardware. Poplar was written in C++ and will be able to take applications written in other frameworks, like TensorFlow and MXNet, and compile them into optimized code to execute on IPU-boosted hardware. It will feature C++ and Python interfaces.
All modern machine learning frameworks like TensorFlow, MxNet, Caffe, Theano, and Torch use the concept of a computational graph as an abstraction, says Graphcore’s Matt Fyles, who wrote today’s blog post.
“The graph compiler builds up an intermediate representation of the computational graph to be scheduled and deployed across one or many IPU devices,” Fyles writes. “The compiler can display this computational graph, so an application written at the level of a machine learning framework reveals an image of the computational graph which runs on the IPU.”
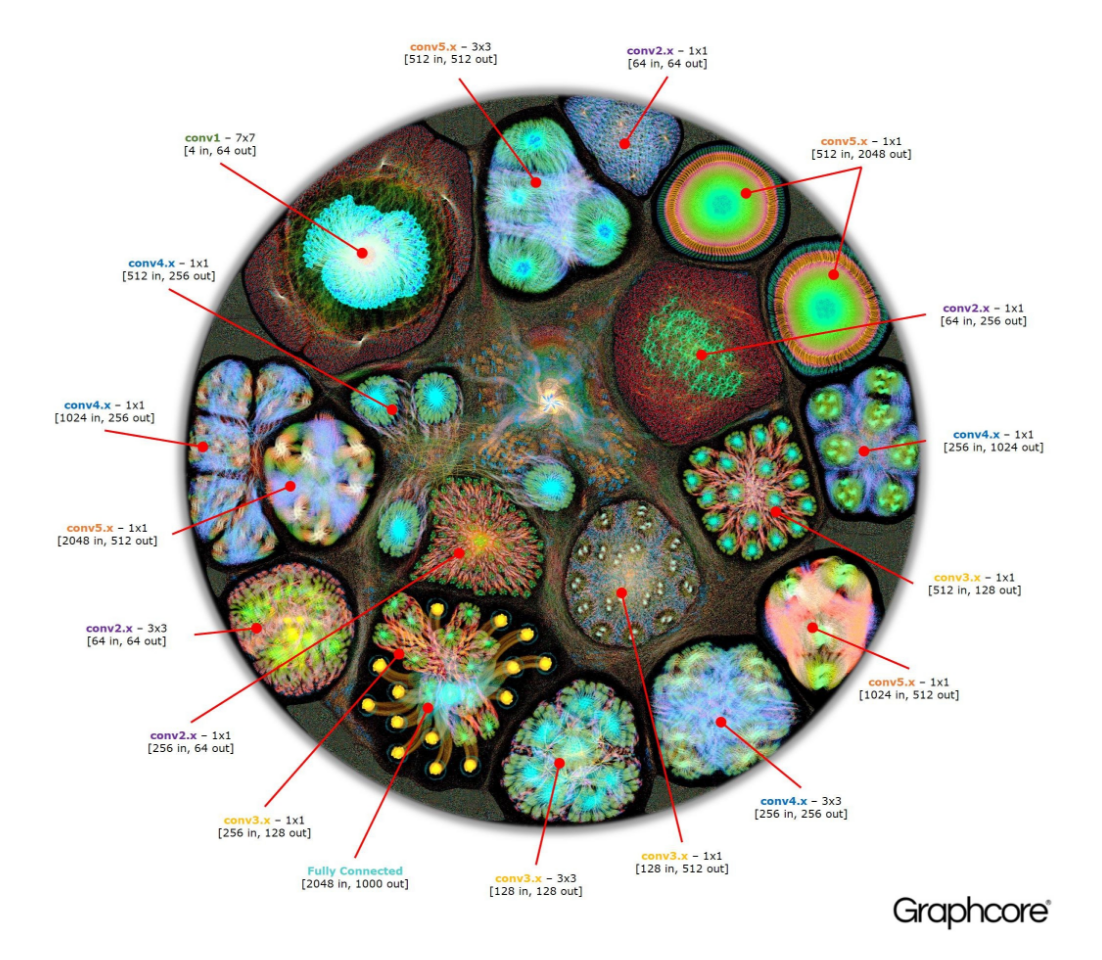
Resnet-50 graph execution plan (Image source: Graphcore)
This is where the images come from. The image at the top of the page shows a graph based on the AlexNet architecture, which is a powerful deep neural network used in image classification workloads among others.
“Our Poplar graph compiler has converted a description of the network into a computational graph of 18.7 million vertices and 115.8 million edges,” Fyles writes. “This graph represents AlexNet as a highly-parallel execution plan for the IPU. The vertices of the graph represent computation processes and the edges represent communication between processes. The layers in the graph are labelled with the corresponding layers from the high level description of the network. The clearly visible clustering is the result of intensive communication between processes in each layer of the network, with lighter communication between layers.”
Graphcore also generated images of the graph execution plan a deep neural network built on Resnet, which Microsoft Research released in 2015. Graphcore was used to compile a 50-layer deep neural network composed of a graph execution plan with 3.22 million vertices and 6.21 million edges.
One of the unique aspects of the ResNet architecture is that it allows deep networks to be assembled from repeated section. Graphcore says its IPU only needs to define these sections once, and then can call them repeatedly, using the same code but with different “network weight data.”

The graph computational execution plan for LIGO data (image source: Graphcore)
“Deep networks of this style are executed very efficiently as the whole model can be permanently hosted on an IPU, escaping the external memory bottleneck which limits GPU performance,” the company says.
Finally, Graphcore shared a computational graph execution plan that involved time-series data gathered from astrophysicists working at the University of Illinois. The researchers used the MXnet DNN framework to analyze data collected from the LIGO gravitational wave detector, which looks for gravitational abnormalities caused by the presence of black holes. The image that Graphcore shared is the “full forward and backward pass of the neural network trained on the LIGO data to be used for signal analysis,” the company says.
“These images are striking because they look so much like a human brain scan once the complexity of the connections is revealed,” Fyles writes, “and they are incredibly beautiful too.”
Graphcore emerged from stealth mode last October, when it announced a $30 million Series A round to help finance development of products. its machine learning (ML) and deep learning acceleration solutions, including a PCIe card that plugs directly into a server’s bus.
Related Items:
Will Hardware Drive Data Innovation Now?
Graphcore Touts 100x ML Speedup with PCIe Plug-In
AI Platforms Seen Emerging in 2017
Sectors:
Financial Services
Vendors:
Graphcore
Leading Solution Providers

















