


May 10, 2017
Machine Learning, Deep Learning, and AI: What’s the Difference?
(BeeBright/Shutterstock)
You hear a lot of different terms bandied about these days when it comes to new data processing techniques. One person says they’re using machine learning, while another calls it artificial intelligence. Still others may claim to be doing deep learning, while “cognitive” is the favored phrase for some. What does it all mean?
While many of these terms are related and can overlap in some ways, there are key differences that can be important, and that could be a barrier to fully understanding what people mean when they use these words (assuming they’re using them correctly).
Here’s our quick primer on the origin and the meanings of these words and phrases:
Machine Learning
At its most basic level, machine learning refers to any type of computer program that can “learn” by itself without having to be explicitly programmed by a human. The phrase (and its underlying idea) has its origins decades ago – all the way to Alan Turing’s seminal 1950 paper “Computing Machinery and Intelligence,” which featured a section on his famous “Learning Machine” that could fool a human into believing that it’s real.
Today, machine learning is a widely used term that encompasses many types of programs that you’ll run across in big data analytics and data mining. At the end of the day, the “brains” actually powering most predictive programs – including spam filters, product recommenders, and fraud detectors — are machine learning algorithms.
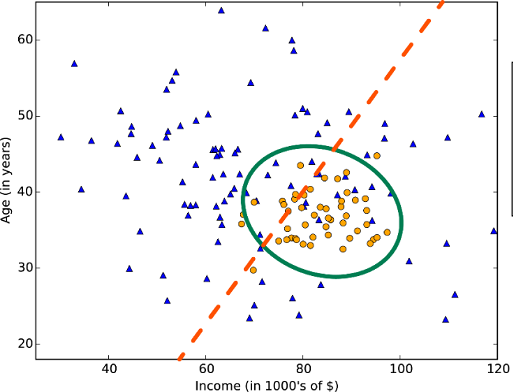
The plot of a linear classification algorithm (Courtesy: Microsoft Machine Learning Algorithm Cheat Sheet)
Data scientists are expected to be familiar with the differences between supervised machine learning and unsupervised machine learning — as well as ensemble modeling, which uses a combination of techniques, and semi-supervised learning, which combines supervised and unsupervised approaches.
In supervised learning, the user trains the program to generate an answer based on a known and labeled data set. Classification and regression algorithms, including random forests, decision trees, and support vector machines, are commonly used for supervised learning tasks.
In unsupervised machine learning, the algorithms generate answers on unknown and unlabeled data. Data scientists commonly use unsupervised techniques for discovering patterns in new data sets. Clustering algorithms, such as K-means, are often used in unsupervised machine learning.
Data scientists can program machine learning algorithms using a range of technologies and languages, including Java, Python, Scala, other others. They can also use pre-built machine learning frameworks to accelerate the process; Mahout is an example of a machine learning framework that was popular on Apache Hadoop, while Apache Spark’s MLlib library today has become a standard.
Deep Learning
Deep learning is a form of machine learning that can utilize either supervised or unsupervised algorithms, or both. While it’s not necessarily new, deep learning has recently seen a surge in popularity as a way to accelerate the solution of certain types of difficult computer problems, most notably in the computer vision and natural language processing (NLP) fields.

Neural networks can have many hidden layers (all_is_magic/Shutterstock)
Deep learning is based on the representation learning (or feature learning) branch of machine learning theory. By extracting high-level, complex abstractions as data representations through a hierarchical learning process, deep learning models yield results more quickly than standard machine learning approaches. In plain English, a deep learning model will learn the features that are important by itself, instead of requiring the data scientist to manually select the pertinent features, such as the pointiness of ears found in cat pictures (because it somehow always comes back to cat pictures in the end).
The “deep” in deep learning comes from the many layers that are built into the deep learning models, which are typically neural networks. A convolutional neural network (CNN) can be made up of many, many layers of models, where each layer takes input from the previous layer, processes it, and outputs it to the next layer, in a daisy-chain fashion. It was a CNN developed by Google‘s DeepMind team that famously beat the human world champion of the ancient Chinese game of Go, which many saw as a sign of deep learning’s ascendance.

Deep learning on cat pictures (Courtesy Google’s “Building High-level Features Using Large Scale Unsupervised Learning” paper)
Deep learning is so popular today due to two main reasons. First it was discovered that CNNs run much faster on GPUs, such as NVidia‘s Tesla K80 processor. Secondly, data scientists realized that the huge stockpiles of data we’ve been collecting can serve as a massive training corpus and thereby supercharge the CNNs into yielding substantial improvement in the accuracy of computer vision and NLP algorithms. Tensorflow is an example of a software development framework, created by Google, that is seeing a surge of interest; Caffe, Torch, and Theano are other examples.
Much of the progress in developing self-driving cars can be attributed to advances in deep learning using CNNs on GPUs, which has the reciprocal effect of helping to fuel further advances in deep learning and the broader artificial intelligence field.
Artificial Intelligence
Like machine learning and deep learning, artificial intelligence isn’t “new,” but it’s definitely experience a renaissance of sorts. And the way people use the word is also changing, much to the chagrin of traditionalists.
When Turing first devised his test, the phrase artificial intelligence was largely reserved for a technology that could broadly mimic the intelligence of humans. In that respect, it was a far-off, futuristic thing, like time travel seems to us today. (It took 60 years, but a computer finally passed the Turing Test back in 2014.)

Chatbots, such as Microsoft’s short-lived “Tay,” are the face of AI technology for many.
Today, the phrase artificial intelligence, or just AI, is becoming more broadly and generally used. In that respect, it’s beginning to supplant “big data” and its hangers-on, “advanced analytics” and “predictive analytics. For those that hate the term “big data,” this is probably a good thing.
But some people prefer to reserve the phrase AI for the narrowly defined thing that can replicate many aspects of human intelligence, and become an entity in its own right. We haven’t reached that stage, yet, and we may never reach it, although that may not be a bet you want to take. A year ago, Facebook CEO Mark Zuckerberg predicted we were 5 to 10 years away from developing an AI that could “actually understand what the content means.”
Going ‘Cognitive’
Machine learning, deep learning, and artificial intelligence all have relatively specific meanings, but are often broadly used to refer to any sort of modern, big-data related processing approach. In this respect, it’s subject to the inevitable hype that accompanies real breakthroughs in data processing, which the industry most certainly is enjoying at the moment.
But some in the industry eschew these phrases almost entirely and use their own set of words. IBM, for instance, refers to its work as cognitive computing. In fact, it went so far as to create a whole new division of the company called Cognitive Systems; its Power Systems division actually lives within Cognitive Systems (which invariably will irritate customers who want nothing but to run their ERP system in peace, thank you very much).

CONNIE is a Watson-powered concierge that Hilton tested
But if you look hard enough, you can find a fairly succinct definition of cognitive on the IBM website. Big Blue says cognitive systems are “a category of technologies that uses natural language processing and machine learning to enable people and machines to interact more naturally to extend and magnify human expertise and cognition.”
So there you go: In IBM’s view, cognitive is the combination of NLP and machine learning, which makes sense when you consider how IBM is using Watson to not only win at Jeopardy, but also “read” medical literature. In fact, IBM says Watson has been trained on six types of cancer so far, and will be trained on eight more this year.
Related Items:
Why Deep Learning, and Why Now
GPU-Powered Deep Learning Emerges to Carry Big Data Torch Forward
AI to Surpass Human Perception in 5 to 10 Years, Zuckerberg Says
Editor’s note: This story was corrected. AI is not “generally used to refer to any sort of machine learning program,” as the story previously stated. Datanami regrets the error.
Technologies:
Middleware
Leading Solution Providers

















