


May 18, 2017
Committers Talk Hadoop 3 at Apache Big Data

The upcoming delivery of Apache Hadoop 3 later this year will bring big changes to how customers store and process data on clusters. Here at the annual Apache Big Data show in Miami, Florida, a pair of Hadoop project committers from Cloudera shared details on how the changes will impact YARN and HDFS.
The biggest change coming to HDFS with Hadoop 3 is the addition of erasure coding, says Cloudera engineer Andrew Wang, who is the Hadoop 3 release manager for the Apache Hadoop project at the Apache Software Foundation.
HDFS historically has replicated each piece of data three times to ensure reliability and durability. However, all those replicas come at a big cost to customers, Wang says.
“Many clusters are HDFS-capacity bound, which means that they’re always adding more nodes to clusters, not for CPU or more processing, but just to store more data,” he tells Datanami. “That means this 3x replication overhead is very substantial from a cost point-of-view.”
The Apache Hadoop community considered the problem, and decided to pursue erasure coding, a data-striping method similar to RAID 5 or 6 that has historically been used in object storage systems. It’s a technology we first told you was coming to Hadoop 3 exactly one year ago, during last year’s Apache Big Data shindig.
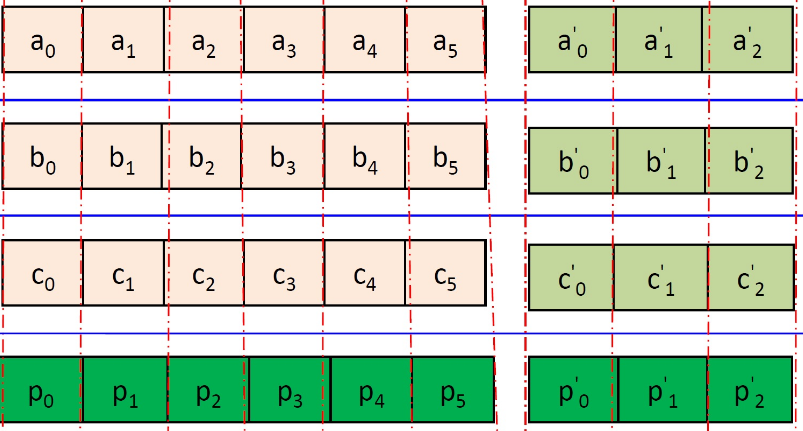
“The benefit of using a scheme like erasure coding is you can gain much better storage efficiency,” Wang says. “So instead of paying a 3x cost, you’re paying a 1.5x cost. So you’re saving 50% compared to the 3x replication, when you look at purely disk expenditure. Many of our Hadoop customers are storage bound, so being able to save them half their money in hard disk cost is pretty huge.”
What’s more, erasure coding can also boost the durability of any given piece of data, Wang says. “In 3x replication, you only have three copies. So if you lose those three copies of the block, the data is missing. It’s gone. But in erasure coding, depending on how you configure it, there are ways of tolerating three failures without losing data. So that’s pretty powerful.”
It’s been two years since the Apache Hadoop community started working on erasure coding, which Wang says is one of the biggest projects to be undertaken by the Hadoop community in terms of the number of developers involved. Upwards of 20 developers from Cloudera, Hortonworks, Intel, Huawei, and Yahoo Japan worked together to get the features built and working in two early alpha releases. The plan calls for one more alpha release this summer, then a beta release and ultimately general availability (GA) by the end of 2017, Wang says.
While Hadoop 3’s erasure coding will bring customers substantial cost savings on disk, there are some technical caveats to the implementation that Wang says will lead some customers to retaining the 3x data replication for some types of data.
Erasure encoding in Hadoop 3 will decrease storage requirement on cold data, while boosting data durability (image courtesy Nanyang Technological University)
The biggest challenge to implementing erasure coding in Hadoop 3 will be the network. Because the scheme is spreading bits of data to many disks in the cluster, it will consume more network bandwidth than traditional 3x replication, particularly for rack-to-rack communications.
That shouldn’t be a problem for bigger Hadoop customers running modern networks, where the bisection bandwidth is minimal and the network is relatively “flat.” But for customers running older networks, the extra network congestion introduced by erasure coding may not be worth it. Because of this limitation, Wang says that customers will want to use erasure coding only for cold data, while retaining the 3x data replication method for hot data that’s frequently accessed.
Hadoop 3 will give users the capability to turn erasure coding on and off for these different groups of data. “Right now, our way of doing erasure encoding is on a directory basis,” he says. “You can mix and match in a single cluster which data is erasure encoded and which data is stored in the 3x replication method.”
The core Apache Hadoop team is working with other Hadoop projects, such as HBase, Impala, and Spark, to make sure they’re ready to roll with erasure coding when it ships. The idea is to minimize the impact on customers, Wang says. “It’s supposed to be pretty transparent for the users,” he says. “We have multiple access methods — WebHDFS, the NFS gateway, REST API or Java client. All these work with erasure coding.”
What’s Coming In YARN
Hadoop 3 will also bring some notable enhancements to YARN, the resource scheduler that, together with HDFS, makes up the core of Apache Hadoop. Cloudera software engineer Daniel Templeton, who is a committer on the Apache Hadoop project, discussed some of the changes coming to YARN with Hadoop 3.
While it’s not set in stone yet, the hope is that, when Hadoop 3 finally ships, there will be some Docker on YARN capability that customers can begin to use, Templeton says.
The idea behind enabling Docker containers to be controlled by YARN is that it will help smooth the rollout and reduce some of the dependencies that sometimes exist when customers deploy services or engines on Hadoop.
One example is the simplification of PySpark deployments on Hadoop. While Spark gives the customer all kinds of great capabilities, the Python implementation lacks the code portability that exists when working with Spark through Java or Scala.
“Spark gives you all this wonderful goodness,” Templeton says. “But Python doesn’t have the code portability that Java does. If you need libraries, they have to be installed. You can kind of sort of hack your way around it with some Python tools, but none of it works really well. At some point you have to have your administrator involved in setting this stuff up, and administrators don’t like to be involving in setting this stuff up.”
By deploying PySpark in a Docker container under YARN, a developer can get the exact PySpark environment they want without requiring administrators to get involved with detailed configurations. It all gets bundled up in a Docker container, and YARN runs it like any other Hadoop job on the cluster.
“The win here is you can set up your environment exactly the way you want it — all your libraries, all your custom stuff, whatever — and you push that out and that’s what gets executed,” Templeton says. “So that makes your life a lot easier when you’re doing something like PySpark.”
Docker on YARN could also improve Hadoop’s services story. Traditionally, YARN is all about executing jobs as quickly as possible, and ending them. Container technology like Docker, on the other hand, is more concerned with ensuring the livelihood of long-running services. So Docker on YARN could also be a better way to ensure that Hadoop-resident services, such as HBase, Kafka, or Impala, keep running as always-on services.
“The catch with service deployment is that it isn’t there yet. That is also coming, but there’s no specified merge date yet for that work,” Templeton says. Basic support for deploying Docker containers with YARN, however, is slated to ship with the upcoming release. “We’ll get Docker on YARN with Hadoop 3.”

There is a lot of work going on to make Hadoop work with Docker
The Docker on YARN story is separate and distinct from Hadoop on Docker, which is also being worked on, and will bring bigger benefits when it eventually comes. But getting Hadoop on Docker will require some architectural decisions to be made, and is still a ways off, Templeton says.
YARN is up for some other changes with Hadoop 3. One of those involves the addition of resource types, which Templeton says will give users more control over how hardware resources, including new processor types like GPUs and FPGAs, are allocated and consumed.
“In Hadoop today your cluster is defined as CPU and memory, period. This is the only thing you can keep track of in your cluster. Not disk. Not I/O. Not GPU. Not nothing. With resource types, it allows administrators to define custom resources. They can say ‘This is disk, this is GPU, this is FPGA.’ And then YARN keeps track of them.”
Some of the large Hadoop users have expressed interest in using GPUs and FPGAs for scientific and deep learning workloads, and support for resource types in YARN will give those customers a better capability to tailor workloads to those resources.
“There were a couple of different folks who came to the table and said ‘Hey I’d like to add FPGAs or GPUs as first class citizens, right along with CPU and memory,'” Templeton says. “And we said, instead of doing one more custom add-on, how about we make it generic? So if you run a job on a node with a GPU, there’s now one less GPU available until that job is done. That will open up a bunch of new use cases as well.”
Another new YARN feature in Hadoop 3 is the addition of the application service timeline, or ATS, which is billed as a universal history server for Hadoop applications. Currently in Hadoop 2, users must start the history server for each engine they use. With Hadoop 3, any application will be able to look up the history without requiring individual history servers to be installed.
More optimizations of the YARN job scheduler are also in order with Hadoop 3, Templeton says. There currently two main types of schedulers used in Hadoop — the fair scheduler, which Cloudrera favors, and the capacity scheduler, which Hortonworks favors, he says. With the new pre-emption changes that are slotted for the fair scheduler, YARN will better allocate resources among groups of competing users.
There’s also a new opportunistic container capability coming in YARN in Hadoop 3 that essentially tries to fill in all the gaps in the schedule with low SLA workloads. The work has been driven largely by Microsoft, Templeton says. However, the code is not there yet for opportunistic containers. “It may not make it for Hadoop 3,” he says.
Related Items:
Why Hadoop Must Evolve Toward Greater Simplicity
Hadoop 3 Poised to Boost Storage Capacity, Resilience with Erasure Coding
Apache’s Wacky But Winning Recipe for Big Data Development
Applications:
Enterprise Analytics
Leading Solution Providers

















