


June 14, 2017
8 Concrete Data Mining Techniques That Will Deliver the Best Results

(Paul Fleet/Shutterstock)
With the massive expansion of information technology, the demand for data mining also grew hugely. But data mining — or the process of wading through huge amounts of data and finding what you consider useful — is not at all easy. Here are eight concrete steps you can follow to make data mining better.
So you have gigabytes upon gigabytes of data at the ready. How are you going to find useful information out of it in the shortest time possible? And even if you have separated useful pieces of data, how are you going to analyze them and spot a pattern or trend?
There are three main steps involved in data mining:
Wading Through – Going through all the data that you’ve accumulated and converting them all into an understandable form. At this stage, the nature of data is also determined.
Checking for Patterns – Now that you have the some idea about the information that you are trying to extract, it’s possible to check for patterns that will be useful in making predictions.
Planning an outcome – Armed with the patterns, you can now plan for the desired outcome.
Once you have completed the data mining process, here are a few benefits you can enjoy with it:
A) Recommending New Products
When you discover patterns within a data, you can use this them to investigate a new demand for a new product. This product may be entirely different or a modification to an existing one. So with data mining, you can research and reach a conclusion on what to sell to your customers.
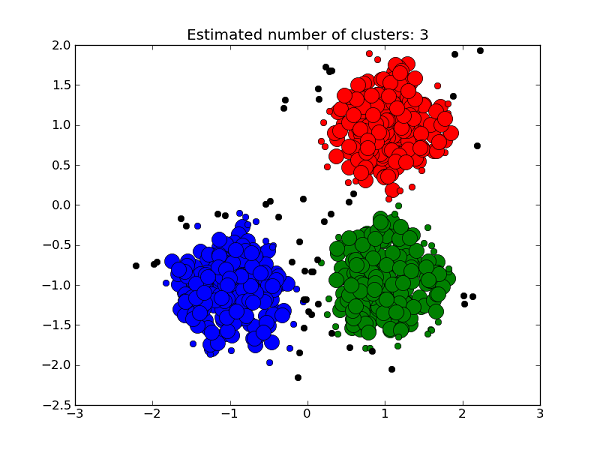
Clustering is an elemental component of data mining
For example Walmart, due to their data mining techniques, discovered that people stored strawberry pop tarts right before a hurricane. Keeping this in mind, the company started placing strawberry pop tarts at checkout counters before each hurricane.
B) Understanding Clusters
Data mining helps you identify certain buying behavior of customers and note the similarities and dissimilarities within the data. Hence, it is possible for companies to target certain products at certain stores and satisfy the urge of certain customers.
C) Classifying the Data
Once you have collected all the data, identified the patterns and decided what is what, the next step is to classify them. This way you can distinguish between data that’s useful to your purpose, and irrelevant data. An example of this would be your own email service, which can identify spam messages and important ones.
Using Web Crawlers to Perform Data Mining
Web crawlers like ants, bots, or spiders are used for collecting data from the Internet. This would help analytics companies and internet marketing experts find out what’s trendy outside. Some of the most popular open source web crawlers are Nutch, Scrapy, PHP-Crawler, WebLech, Spindle and Ebot.
Both Web crawlers and data mining work together. This is because all the data collected by the Web crawler would be rendered useless unless you can classify it, and draw useful insights from it. This is what we do in data mining.
![]() You may have assumed that data mining and big data are one and the same, but you would be wrong. While data mining gives you the close up view of all the data that’s been coming in, big data gives you the big picture. Big data is important to analyze the “why” that you see in data trends – Why certain categories of people buy the same thing? Why they eat the same thing? Why they wear a particular dress and so on. In big data, the trick is to find the who, why, and the what.
You may have assumed that data mining and big data are one and the same, but you would be wrong. While data mining gives you the close up view of all the data that’s been coming in, big data gives you the big picture. Big data is important to analyze the “why” that you see in data trends – Why certain categories of people buy the same thing? Why they eat the same thing? Why they wear a particular dress and so on. In big data, the trick is to find the who, why, and the what.
Finally, let’s have a look at the eight key data mining techniques that can help you achieve your business goals:
1. Recognizing and Handling Incomplete Data
Every effort to utilize data for data mining would be rendered useless if you have incomplete data. In order to avoid such a circumstance, it is important to determine the pattern of missing data:
(a) Is your data completely missed?
(b) Is it only a random piece missing?
(c)Is there a particular variable for missing data?
Imputation is a method by which you can replace the missing data with substituting values. There are various kinds of imputation like average imputation, regression substitution, multiple imputation and educated guesses to help you reach a decision.
2. Clustering Techniques
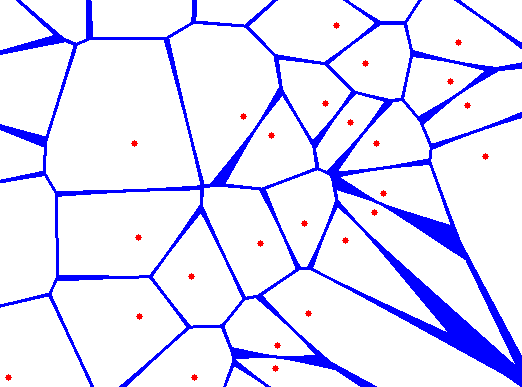
Nearest neighbor algorithms can help identify patterns in the data
This is a very old data mining technique, but is still relevant, and still very useful. Clustering data is the process by which you can analyze the data based on their behavior. Data possessing similar behavior would be analyzed together, because it helps the user to draw conclusions on customer behavior.
There are several ways to do this as well. And one popular method is by looking at the neighboring data. Checking the nearest neighbor would help you predict the values by looking at the values in the historical database. According to this technique, the objects that are close together have the tendency to exhibit the same prediction value.
3. Anomaly Detection
The best results from data mining can be enjoyed only when you remove the anomalies from it. Anomalies happen when you capture information that does not fit a pattern. Anomalies come under different names – exceptions, outliers, contaminants, etc.
They are usually noticed when the collected data deviates from how a particular dataset should look like or is totally different from what you would expect a combination of data should contain. As it is totally out of the ordinary, it would require additional analysis, to understand what this data would be leading to. It could be an infiltration, a hack or a fraudulent action that banking and financial sectors must be aware of.
Capgemini is an IT company that has used this technique successfully in analyzing unlawful log-in attempts and hacks. They combined anomaly detection with machine learning to step up their security.
For example, if a particular employee is traveling and accessing records at the same time, they can easily detect the distance between each log in-attempt. If the distance is impossibly large, it indicates a fraudulent log-in attempt.
4. Using OLAP for Complex Data Types
When there are large amounts of relational data types and complex data warehouses, the challenge would be to develop a system that would handle it well. This is where OLAP comes in.
OLAP or Online Analytical Processing is very useful for all the important steps in data mining functions, such as characterization, association, classification, predictions/analyses, and clustering.

OLAP can be an effective data mining technique
OLAP is thus a database technology that has evolved to be an important category that supports business intelligence and encompasses relational database and data mining. It is optimized for not just process transactions, but querying and reporting as well.
The data would be derived from historical databases and then compartmentalized into structures for detailed analysis. This could be very useful to businesses, especially when they need to check the performance of a particular website or the progress of sales in a particular country or region.
OLAP databases can save time too because it aids in quick retrieval of data, enabling companies to work with huge amounts of data in an organized manner.
5. Decision Trees Used for Exploration and Data Pre-Processing
Decision trees are considered the newest data mining technology that helps you to analyze which parts of the database are really useful or which part contained a solution to the problem you were trying to understand. Decision tree algorithms help analyze the data and validate them in an integrated manner
Decision trees are more useful for solving credit card attrition predictions and predictions related to international currencies. As they are extremely useful in data mining, decision trees are used for exploration and data preprocessing as well.
By looking at the predictors or values for each split of the tree, you can draw a number of insights or find answers to the questions you’ve been asking. The decision tree technology has been pretty useful for pre-processing data for checking other kinds of prediction algorithms as well.
6. Neural Network Method
Neural networks are thought of as non-linear statistical data modeling tools that can be used to find patterns in data or to decipher complex relationships between inputs and outputs. Neural networks are programmed to store, recognize and fetch patterns in database entries, to filter noise and to identify problems.

Neural networking is one form of data mining (all_is_magic/Shutterstock)
The data mining process based on neural networks would deliver robust results, with high degree of fault tolerance. With its distributed storage capabilities and self-organizing adaptive nature combined with parallel processing, neural network method of data mining has evolved to be a very important technique.
The four main processes in data mining based on neural networks are:
Data clustering – remove all the inconsistencies in the data and eliminate all noise data.
Data option – Select the data to be used for mining.
Data pre-processing – Pre-process the data that has been selected.
Data expression – Transform the data because you need to transform the sign data into numerical data.
Another reason for the popularity of neural networks is that the users can automate it, so even if they don’t have knowledge about databases, data mining becomes an easier task
7. Association Rule Technique
As the name suggests, this technique would help analyze the association between two or more items in large data sets. If you are looking for the relationship between the different variables in a database, then association rule technique would be ideal because it can discover the hidden patterns in various data sets. It can also point out the frequent occurrences of the variables successfully.
The association rule technique helps businesses by analyzing the relationship among huge sets of data aiding in catalog designs, loss leader analysis, cross marketing and in several other decision-making processes. This technique can even help find associations in the different items that customers place in their shopping baskets.
8. Classification
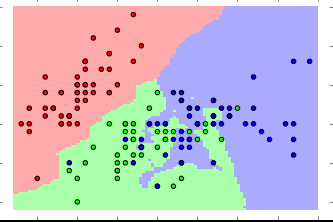
Don’t overlook classification algorithms
Though we mentioned it last, it is definitely not the least popular data mining technique. In fact, it is one of the most commonly used one when you need to classify large sets of data.
The classification method uses neural network and decision tree methods to derive actionable insights. Businesses use this approach to learn about their customers’ behavior and preferences. For example, a loan company can use this technique to learn about applicants relative risk levels, using their credit rating as a proxy for risk.
Apart from assessing credit card users, the classification method can also be used to observe home ownership details, employment history, investments and so on. It is possible to test the classification models by comparing known models with predicted values.
This is probably the reason why classification models are divided into two data sets – one for testing the model, and another for building the model.
Conclusion
The data mining techniques that we have explained above are some of the best in the industry. These would help you make smarter business decisions and draw actionable insights.
Don’t feel that you’re restricted to using a single technique. Most of the time, these techniques can be blended together to get the best results.

About the author: Sunu Philip is the Inbound Marketing Head of Cabot Technology Solutions, an IT consulting firm specialized in Web and mobile technology solutions. Cabot offers progressive end-to-end business solutions, blending a solid business domain experience, technical expertise and a quality-driven delivery model.
Related Items:
Machine Learning, Deep Learning, and AI: What’s the Difference?
It’s Time to Think Differently About Mining Big Data
New Techniques Turbo-Charge Data Mining
Technologies:
Middleware
Vendors:
Cabot Technology Solutions
Leading Solution Providers

















