


June 22, 2017
Hadoop Engines Compete in Comcast Query ‘Smackdown’

Who rules the ring when it comes to Hadoop SQL query engine performance? Can flashy newcomers like Presto and Spark take an established giant like MapReduce to the matt? Comcast recently held a competition to crown the best Hadoop engine, and the answer may surprise you.
Like most big media companies, Comcast has invested in Hadoop to store and process the petabytes of data it collects from its operations. A good portion of the Hadoop workload for the $80 billion conglomerate (it also owns NBCUniversal) involve the execution of SQL queries to drive BI reporting.
Instead of flying blind with SQL query performance, the company decided to pit the Hadoop engines against each other in a no-holds barred competition, or what Comcast Principal Architect Michael Fagan dubbed a good old fashion “smackdown.”
There were no tight spandex outfits, outrageous boasting, or head-splitting pile drivers during Comcast’s presentation last week at the Dataworks Summit in San Jose, California. But that didn’t prevent clear winners — and losers — from emerging from the ring – the closest thing to an apples-to-apples comparison you might see.
The Setup
The ring consisted of a test environment split into five physical masters (32 cores, 90GB of RAM, 48TB of storage, and a 10GbE network adapter) and 11 physical workers (32 cores, 128GB RAM, 48TB storage, and 10GbE network adapter) connected via 40GbE top-rack switches. It ran CentOS Linux ad Hortonworks HDP 2.6.
The contestants were MapReduce2, Hive/LLAP 1.2, Tez 0.7, Spark 2.1, and Presto 0.175. The data was a 1TB collection of sequence, text, Parquet, and ORC files. All told, Comcast ran 66 queries, which represented the same subset of the TPC-DS benchmark that Hortonworks used to benchmark Hive/LLAP.
Fagan and his Comcast colleague, big data architect Dushyanth Vaddi, described how they set up each test. Each SQL engine had full access to the cluster, and the same tests were run against each of them. Comcast ran each test three consecutive times. Care was taken to configure and tune each SQL engine in accordance with best practices.

MapReduce SQL query performance is “a dumpster fire,” according to Comcast’s principal big data architect (TFoxFoto/Shutterstock)
At runtime, the engineers timed how long it took each engine to complete each test. If a particular engine failed a test, it was given a penalty time of 10 minutes. Each engine failed at least one test, but some failed much more than others.
Winners and Losers
We’ll start with the big loser: MapReduce, which took 36 hours to run the 66 queries. “MapReduce was the worst performing of the engines,” Fagan told the audience. “It was so bad we call it a dumpster fire. This is definitely not a performant environment.”
Next worst was Spark with the Spark Thrift Server (STS). “The Spark STS in our environment proved to be very inconsistent,” Fagan said. “Getting retrievable results with STS proved to be very problematic, and the only way we could do this is we had to start cherry picking some of the results and so we had to scratch that.”
The problem is not related to Spark SQL, which Fagan said “is awesome. The challenge is STS is a new technology,” he added. “It’s still under construction. So stay tuned.”
Three engines made the final stage. Taking bronze was Tez, which completed all 66 queries in a respectable 105.2 seconds. Tez ran fastest six queries faster than the other engines, “which was a little bit of a surprise to us,” Fagan said.
The silver medal went to Presto, which clocked in just behind Tez with a total time of 103.6 seconds. Presto ran 16 of the TPC-DS queries faster than any other engine, according to Comcast’s results.
Taking the gold was Hive/LLAP, which won 44 of the TPC-DS queries and had a total query time of 78.6 seconds. That is 24% faster than Presto and 24% faster than Tez.
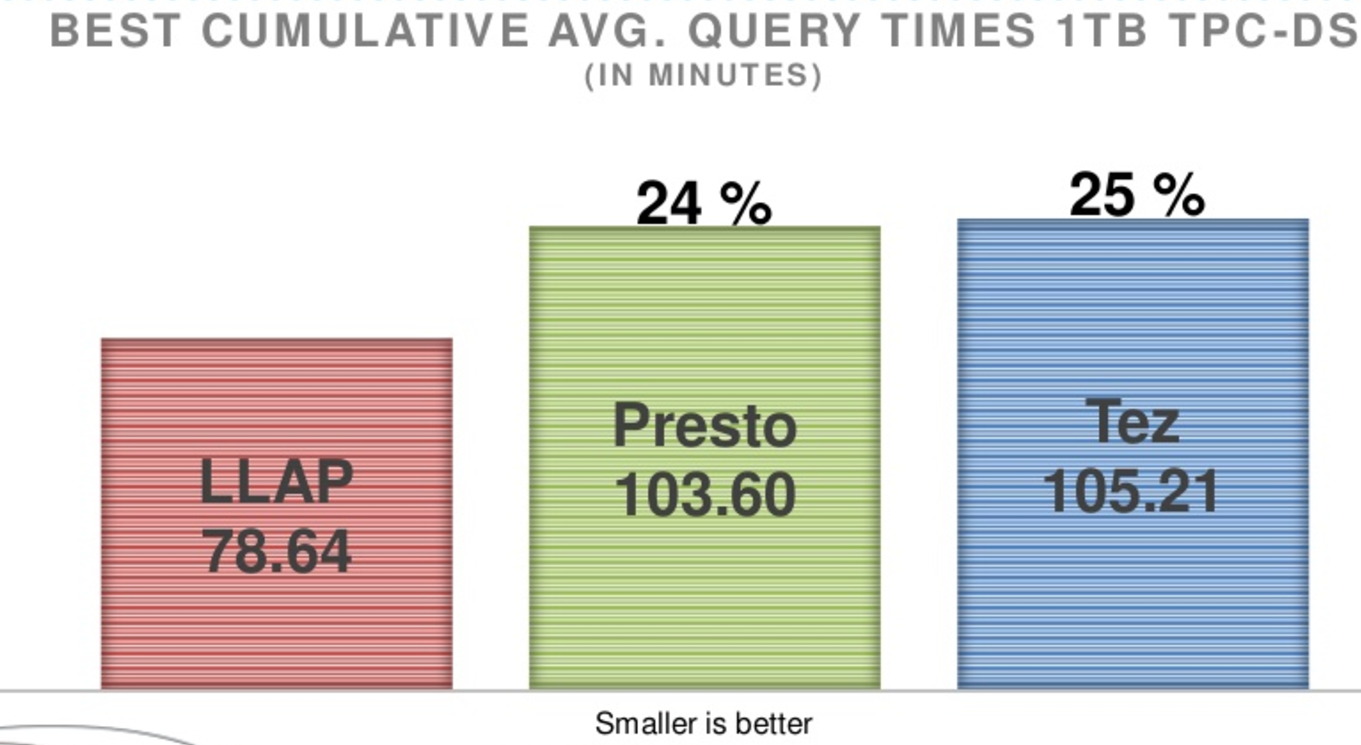
Hive/LLAP won Comcast’s Hadoop Query Smackdown
LLAP is “definitely a different beast than the other engines that are coming standard with Hadoop,” Fagan said. While LLAP is “totally optimized for ORC,” the testing showed that LLAP was able to outperform other SQL engines, he said. “It’s much faster than the other two engines….LLAP is clearly out in front.”
In the end analysis, Hive/LLAP and Presto emerged as the two biggest winners. “Running LLAP and Presto in our test environments….was rock solid,” Fagan said. “No issues, no restarts, no hiccups. Definitely very solid engines and they’re ready for production use.”
While LLAP was “hands down” the winner in Comcast’s smackdown, Presto came out looking pretty good. “If you don’t have to worry about a lot of date casting and semi joins it’s a really good engine too,” Fagan said. “You won’t get as good performance as LLAP but its’s a good second place.”
You can see the entire presentation on YouTube here.
Related Items:
Big Performance Gains Seen Across SQL-on-Hadoop Engines
Picking the Right SQL-on-Hadoop Tool for the Job
New TPC Benchmark Puts an End to Tall SQL-on-Hadoop Tales
Leading Solution Providers

















