


September 14, 2017
The Data Science Behind Dollar Shave Club
Dollar Shave Club burst onto the men’s hygiene scene in 2011 with a hilarious video and preposterous business plan: selling subscriptions for razor blades at a ridiculously low price. Six years later, the company keeps getting laughs with viral YouTube spots, while a sophisticated Apache Spark-based data mining operation running on Databricks’ cloud helps it optimize sales and gobble up market share.
Since it was bought by Unilever last year for a reported $1 billion in cash, Dollar Shave Club (DSC) can no longer lay claim to being an ambitious little startup from Venice Beach, California. But the company continues to stoke a David-versus-Goliath storyline as it capitalizes on men’s general unhappiness with paying large sums for razor blades.
Today, DSC offers a range of men’s grooming products, all available via subscriptions managed on its website and delivered free of charge to more than 3 million members. DSC has even branched out into the editorial business by launching Mel Magazine, an online publication that replicates DSC’s unique masculine style.
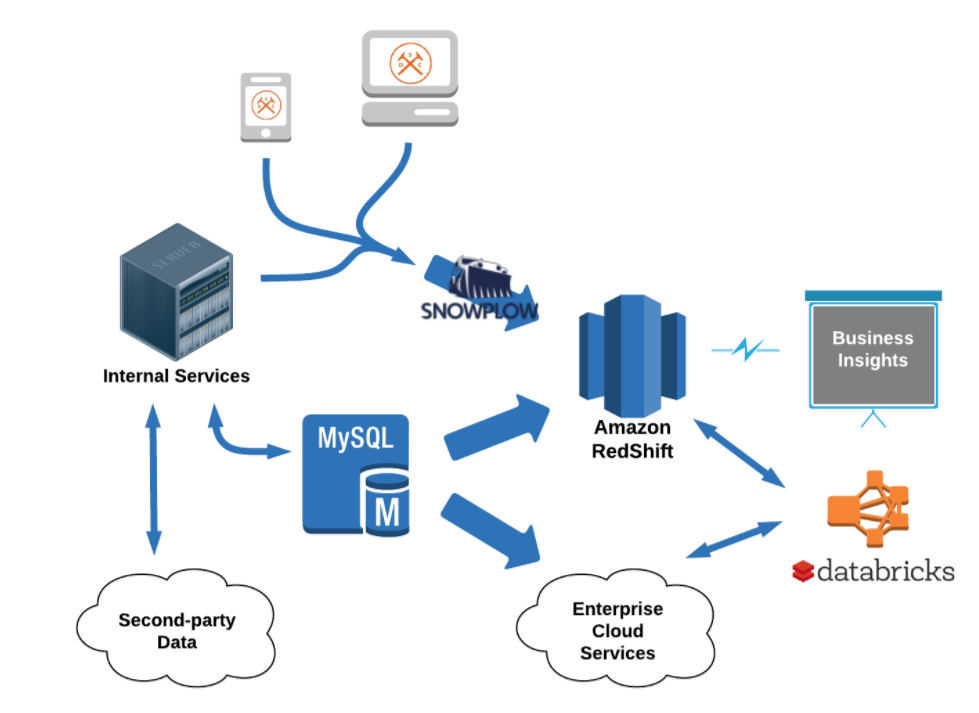
With so many users navigating the site and clicking on weekly emails, DSC has a rich collection of data to pull from, including page views, link clicks, browsing activity, and other data that’s all centrally stored on the AWS cloud. To make maximal use of this data, DSC set out to build a series of data services pipelines, including a recommendation engine based on Apache Spark and running on Databricks cloud environment that uses machine learning to anticipate what DSC products customers are likely to buy.
“Our goal was to produce, for a given member, a ranking of products that prescribes which products to promote in their monthly email and with what priority,” writes the company’s manager of data science and engineering, Brett M. Bevers in a blog post on the Databricks website.
Exhaustive Features
Adoption of Databricks at DSC started organically in the 2015 timeframe, and grew from there. “I had been experimenting with Spark on my own and I saw Databricks as a great resource as well as a way to bootstrap new capabilities at DSC,” Bevers tells Datanami via email. “Databricks is a nearly seamless addition to our other AWS-hosted data infrastructure; namely, Redshift, S3, and services like Kafka and Airflow deployed on EC2.…There was minimal up-front cost getting started, and our confidence in Databricks has grown over time.”
DSC had a tall order for Databricks and its suite of data science tooling: finding the best features to base a recommendation system upon out of more than 10,000 features per user. That exhaustive search would require some careful planning on the part of Bevers and the DSC team.
DSC analyzed the various options for large-scale data mining. “Stepwise selection methods, involving exhaustive forward and backward passes over the features, would take much too much time,” Bevers tells Datanami. “On the other hand, training a model on all features at once comes up against the curse of dimensionality. Regularization is not much help against overfitting when training on such high-dimensional and sparse data. Ensemble methods might perform a bit better, but they would not provide the sort of interpretability that we were hoping for in our exploration. There was no way around using some sort of selection to eliminate most of the features from consideration.”
In the end, the company settled on a simple genetic algorithm as a feature selection method. Bevers describes the approach: “We would extract a variety of metrics in about a dozen segments of member data; pivot that data by hundreds of categories, actions, and tags; and index event-related metrics by discretized time,” Bevers writes on the blog. “In all, we included nearly 10,000 features, for a large cohort of members, in the scope of our exploration.”
Because the dataset was large, sparse, and high-dimensional, the DSC data science team needed to automate the steps required to winnow down the huge number of features. Spark Core, Spark SQL, and finally SparkML would all play a role in creating the recommender. “The final product,” Bevers writes, “would be a collection of linear models, trained and tuned on production data, that could be combined to produce product rankings.”
Data Prep & ETL
But before DSC could get to the machine learning part of the project, the data needed to be pulled out of DSC’s relational datasets and prepared for analysis. This was a challenge unto itself. DSC started by looking at various segments of data in its relational databases, or “groupings of records that needed to be stitched together to describe a domain of events and relationships,” Bevers writes.
 Databricks’s data science notebook interface for Spark shell came in particularly handy for these tasks. “Spark notebooks proved to be ideal for trying out ideas and quickly sharing the results or keeping a chronicle of your work for reference later,” Bevers writes.
Databricks’s data science notebook interface for Spark shell came in particularly handy for these tasks. “Spark notebooks proved to be ideal for trying out ideas and quickly sharing the results or keeping a chronicle of your work for reference later,” Bevers writes.
Once the relational datasets were extracted and cleansed in Databricks’ environment, DSC needed to create aggregates that allowed them to get the time intervals that were important to them. “Comparing specific event types second by second is not fruitful,” Bevers writes. “At that level of granularity, the data is much too sparse to be good fodder for machine learning.”
ML Training
After rolling up, or “pivoting,” the data sets, DSC then had the features most conducive for training the machine learning models. It used a sparse vector format to represent the pivoted data set using Spark’s resilient distributed data (RDD). “Representing member behavior as a sparse vector shrinks the size of the dataset in memory and also makes it easy to generate training sets for use with MLlib in the next stage of the pipeline,” Bevers writes.
The final step of the process involves data mining. The fact that DSC wanted to use thousands of variables in its model, as opposed to, say, a few dozen, presented a “particularly hard problem,” Bevers writes.
Instead of trying to brute-force a solution for each and every customer, DSC took random samples of its data, and then iterated on them several hundred times using a model based on the stochastic genetic algorithm. Over time, it was gradually able to find the best set of features that make up a high-performing model, without succumbing to problems that affect other approaches, including overfitting, Bevers writes.
DSC would generate different models for each product, and run the models separately. For each product, DSC provisioned a separate Spark cluster with eight nodes and a total of 32 CPUs. The cluster would run continuously for one to two days, generating one high-performing model for each given product in the end.
“Training a model and calculating the evaluation statistic for each feature in that model is computationally expensive,” he writes. “But we had no trouble provisioning large Spark clusters to do the work for each of our products and then terminating them when the job was done.”
DSC has plans to expand its Spark service in the future, including Spark ETL jobs and stream processing applications. It also plans to leverage the integration that Databricks has built for Apache Airflow, a pipeline orchestration platform, which will allow the company to build more complex services.
It looks like Databricks plays heavily in DSC’s future data science plans. “Databricks…provides full-featured job management, REST APIs, and a notebook interface with real-time collaboration and interactive visualizations,” Bevers tells us. “It’s hard to find a set of alternatives bringing together all of that functionality with comparable usability.”
Related Items:
Containerized Spark Deployment Pays Dividends
Spark’s New Deep Learning Tricks
Technologies:
Middleware
Sectors:
Retail
Leading Solution Providers

















