


October 12, 2017
The Serverless ETL Nextdoor
When Nextdoor set out to rebuild its data ingestion pipeline so it could better handle billions of files per day, it brought in all the usual suspects in the real-time racket: Spark, Kafka, Flume, etc. In the end, however, the company couldn’t find exactly what it was looking for, so it did what any enterprising data-driven company would do: It built its own.
Nextdoor is a private social network that connects residents living in a common neighborhood. The founders of the San Francisco-based company launched the service in 2010 with a plan to be a more engaging version of Craigslist, which is another SF treat. But the idea took off, and today there are about 156,000 neighborhoods across the country using the free service.
Over the years, the service has grown, and today Nextdoor touches millions of users across Web and mobile interfaces. But the company itself is relatively small, with just 180 employees, according to its website. Supporting such a mammoth operation would not be possible without leveraging cloud technologies – in Nextdoor’s case, Amazon Web Services, among others.
The company uses an array of technologies to create the final product: Web servers, relational databases, NoSQL databases, graphical information systems GIS, distributed file stores, search indexes, and real-time streaming data pipelines. It uses many of the big data technologies developed by Web giants and social media outfits, including Hadoop, Spark, and Elasticsearch, as well as RightScale‘s technology for dynamically scaling AWS resources to meet demands. Its hosted Hadoop service is managed by Qubole.

Nextdoor does a good job of hiding the behind-the-scenes complexity from the user, as every data-driven company should strive to do. When a user invites his neighbors over for a weekend barbeque or writes about possible porch thieves, it triggers a host of actions that trickle down through Nextdoor’s systems, including sending out email alerts and updating the index.
Today the company’s systems generate 2.5 billion daily syslog and tracking events. But it’s becoming a challenge to keep the data ingestion pipeline running as the company grows, according to Nextdoor engineer Slava Markeyev.
“We found that, as our data volumes grew, keeping the data ingestion pipeline stable became a full time endeavor that distracted us from our other responsibilities,” Markeyev wrote in a recent blog post on Nextdoor Engineering.
A New Pipeline
When he joined the Systems Infrastructure team, one of Markeyev’s first jobs was to rebuild the Apache Flume-based data ingestion pipeline. The company had been using Flume for years to stream logs into Elasticsearch and for writing batches of data into S3, which carried service level agreements (SLAs) of one minute and five minutes, respectively.
Markeyev assembled all the usual suspects from the streaming data field, including server-based Spark, Flink, Storm, Kafka Streams, and the old standby Flume. Also considered were newer “serverless” streaming data systems that are hosted by cloud providers, such as the combination of Amazon Kinesis and Lambda, Google‘s Cloud Dataflow, Microsoft Azure, and Ironworker from Iron.io.
It was Markeyev’s job to analyze the costs and benefits of the various architectural choices. They all had various advantages and disadvantages over the others, but the argument boiled down to whether Nextdoor wanted to be in the business of managing their own infrastructure, or whether it could ride atop a pre-built cloud service. That tipped the scales in favor of serverless cloud architectures for Nextdoor, which was already swinging above its weight class thanks to its reliance on cloud offerings.

With serverless ETL, Nextdoor engineers could write a piece of code describing the ETL function, and that code would be automatically called by AWS whenever a file is uploaded to S3, an event is streamed to Kinesis, or a file is written to DynamoDB.
“All you have to do is supply [the] code to process that data,” Markeyev writes. “You no longer need to worry about managing servers, services, and infrastructure. All of that is handled for you.”
But there are some hidden costs in this approach that also must be considered, above and beyond the extra monetary cost of essentially outsourcing this function to AWS. In particular, Markeyev was concerned that, while serverless marked a “powerful shift” in how ETL is performed, that the overall approach is “still young…and is missing some pieces.”
Specifically, there is no standardization of code for serverless ETL, he wrote. “Engineers are able to write lightweight functions to process data, but this often leads to fragmentation of approaches within teams, organizations, and the greater open source community,” he continued. The “boilerplate logic” for various functions, he writes, is just not there yet.
Instead of passing on serverless ETL, however, Markeyev aimed to solidify the approach by addressing its shortcomings. He and his colleagues at Nextdoor did this by developing a new product called Bender.
Building Bender
Bender is a Java framework for creating serverless ETL functions on AWS Lambda. The open source project, which is hosted on GitHub, has two parts, including a core component that handles the complex plumbing and provides interfaces necessary for ETL, and various Bender Modules that implement the most common use cases.
Bender lets engineers write their own input handlers, serializers, deserializers, operations, wrappers, transporters, or and reporters. “Out of the box, Bender includes modules to read, filter, and manipulate JSON data as well as semi-structured data parseable by regex from S3 files or Kinesis streams,” Markeyev writes. “Events can then be written to S3, Firehose, Elasticsearch, or even back to Kinesis.”
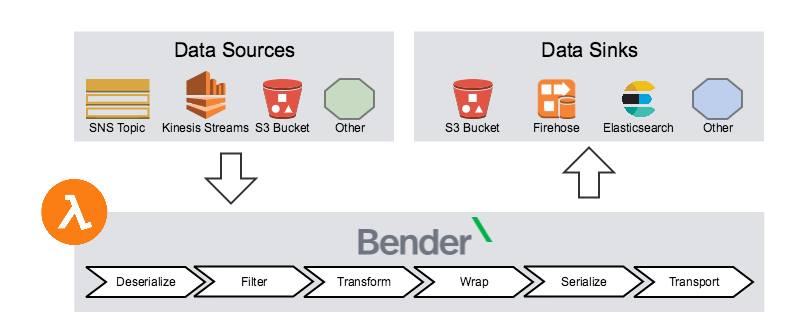
Bender provides a higher degree of ETL code reusability for Nextdoor
Bender can be adapted to support different log formats, and also configured to support different data sources and destinations, Markeyev writes. “When designing Bender, we wanted a function that we could easily reconfigure to handle different use cases while leveraging common boilerplate logic like error handling, statistical reporting, retrying, configuration, etc.” he writes.
While ETL has evolved from the days of centralized data warehouses, it hasn’t gone away. In fact, with so many specialized data management and analytic tools available today, the need for ETL tools that can efficiently move and transform huge amounts of streaming data is even greater today. As the folks at Nextdoor demonstrated, organizations don’t have to exchange cloud efficiency for control when selecting a next-gen ETL systems.
“Working with cloud based services doesn’t eliminate engineering effort — rather, it shifts it,” Markeyev writes. “My team, Systems Infrastructure, helps bridge the gaps between servers and services so that our engineers can focus on the main goal of Nextdoor: building a private social network for neighborhoods.”
Related Items:
The Real-Time Future of Data According to Jay Kreps
Leading Solution Providers

















