


November 9, 2017
How to Make Deep Learning Easy

(Zapp2Photo/Shutterstock)
Deep learning has emerged as a cutting-edge tool for training computers to automatically perform activities like identifying stop signs, detecting a person’s emotional state, and spotting fraud. However, the level of technological complexity inherent in deep learning is quite daunting. So how can one get started? Forrester analyst Mike Gualtieri provides a surprising answer.
“The easiest way to possibly do deep learning,” Gualtieri said during a session at Teradata‘s recent user conference, “is not to do it.”
No, Forrester’s principal analyst has not resorted to speaking in Confucian proverbs. Actually, Gaultieri was making a useful point about the need to keep oneself sufficiently abstracted away from the gory technical details that exist under deep learning’s shiny covers.
And that abstraction, Gualtieri says, is available via the cloud. Each of the public cloud providers, Amazon Web Services, Microsoft Azure, and Google Compute Engine, has invested considerable time and money into supporting various deep learning frameworks on their systems, including MXNet, Keras, and TensorFlow.
What’s more, they’ve built useful services based atop these deep learning frameworks – such as for image recognition, speech recognition, and language understanding — and exposed them through easy-to-use APIs.
“A lot of the cloud companies have pre-trained models. They’ve done the hard work and all you have to do is call an API,” Gualtieri said. “If you want to use deep learning, look for these APIs because it’s a very easy way to get started.”
Forrester recently published a report detailing the specific capabilities offered by these public cloud providers. The big three cloud providers are included, as are enterprise software giants like IBM and Hewlett-Packard Enterprise, which expose deep learning capabilities via their Watson and HavenOnDemand offerings, respectively.
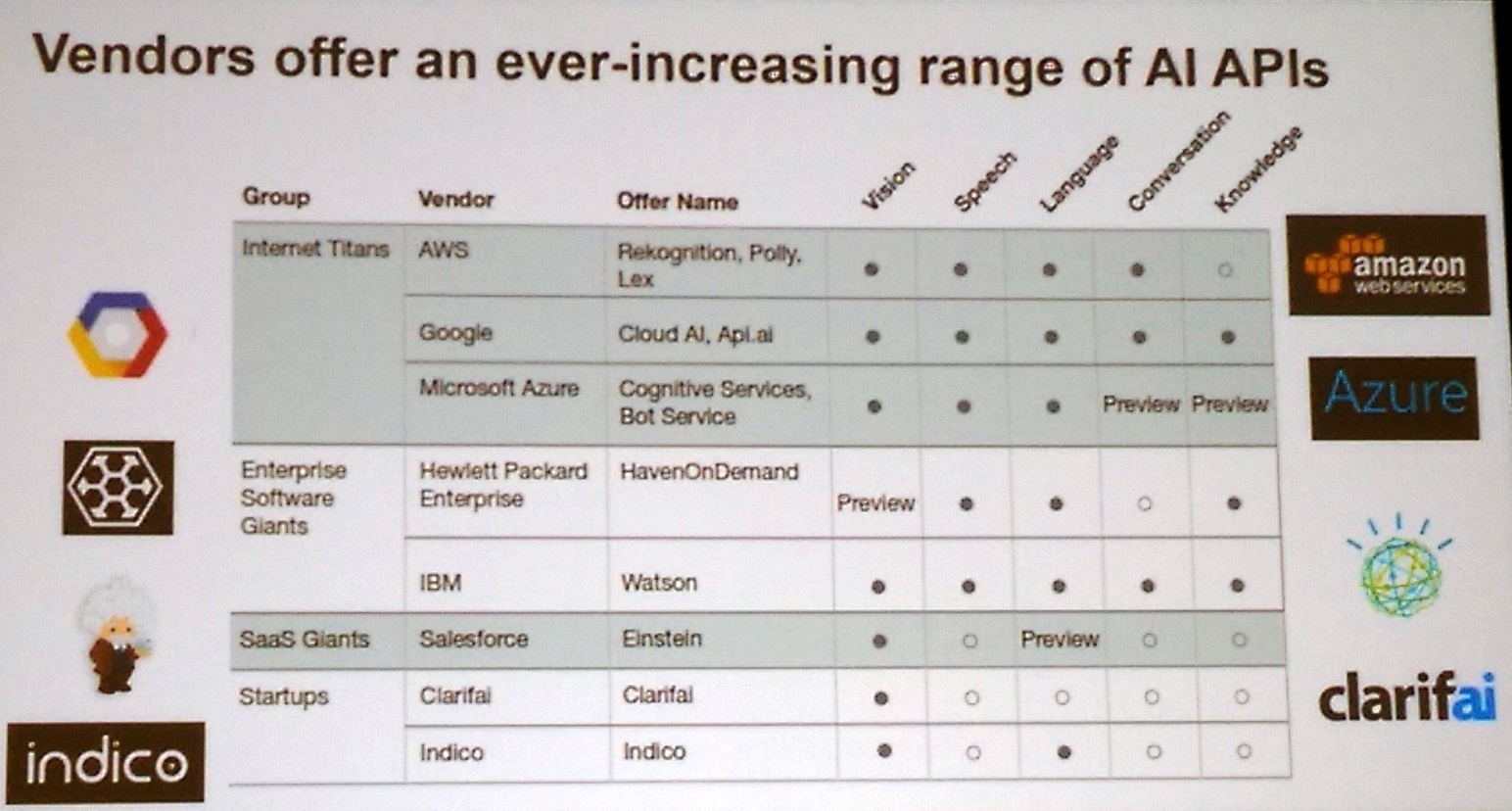
Source: Forrester
The analyst group also tracks the deep learning offerings from Salesforce, which offers computer vision capabilities via its Einstein offering. It also tracks two deep learning startups, Clarifai, which offers a computer vision system, as well as Indico, which offers computer vision and language understanding.
While these cloud-based deep learning offerings are useful, they may not be useful for a company’s specific challenge, nor easily used with the unique data that they own. That’s why many companies are diving into the deep learning lake themselves and developing their own expertise with the available libraries.
The open source nature of deep learning frameworks makes them very accessible, and lots of people are playing around with them, according to Gualtieri. They can download TensorFlow from GitHub, for example, and start training a model on some data over the course of a weekend, he said.
While it’s difficult to build a deep learning frameworks, it’s not terribly hard to actually use one, despite their reputation for complexity, according to Gualtieri.
“We say that these skill sets are rare,” he said. “The skillsets are very rare for people who can develop these algorithms. But let’s be clear: when you’re building a model, you’re not developing the algorithms. You’re using the algorithms developed in here.”
A data scientist doesn’t have to understand how an image recognition system built upon TensorFlow works under the covers, or how to a natural language processing (NLP) system built upon Theano actually works. “They just have to understand how to wire it right,” Gualtieri said.
![]()
That doesn’t mean it’s easy to get good results from deep learning approaches. Some of the same old challenges remain, including getting good data to train a model.
The garbage in, garbage out (GIGO) phenomenon remains a big obstacle to deep learning. Because of the large amount of data that deep learning requires, and the high costs racked up by manually labelling data to feed into the algorithms, it can be difficult to get enough data to get the models effectively trained.
“It doesn’t learn this stuff magically. It learns it from those labels,” Gualtieri said. “There’s no inherent feedback. You have to build it into the model.”
Choosing the right framework for particular needs can also be a challenge. “The problem with this market right now is there’s just too many frameworks. There’s too much innovation,” Gualtieri said. “There’s a little bit of a battle going on among these frameworks.”
TensorFlow seems to be on the rise, but it’s not clear if it will be the winner going forward. Gualtieri applauded Teradata’s decision to support TensorFlow next year as part of its new Teradata Analytics Platform initiative unveiled at the conference, while maintaining open connections to other frameworks, including Spark, Theano, and Gluon, the new machine learning library recently unveiled by Microsoft and AWS.
As we’ve seen with other big data technologies, hype has a tendency to lead decision-makers down paths they may not be prepared to travel. We saw that with the unreal assumptions about what Apache Hadoop could provide for an organization, and we’re seeing that with deep learning frameworks todayo.
Forrester has fielded inquiries from customers about deep learning, and several of them have put the proverbial cart before the horse. “We’ve seen companies buying the NVidia DGX-1, which is a $129,000 box, and then asking us, now what do we do?”
“There’s a lot of excitement about what companies can do with deep learning,” he continued. “We think it’s the ground floor. We see a lot of innovation and technology groups getting in on this. We think 2018 is the year of deep learning.”
Related Items:
Dealing with Deep Learning’s Big Black Box Problem
Keeping Your Models on the Straight and Narrow
Deep Learning Is About to Revolutionize Sports Analytics. Here’s How
Leading Solution Providers

















