


April 20, 2018
The New Economics of the Separation of Compute and Storage

via Shutterstock
No one can predict the future analytical needs of their business. The right storage needs today might not be the right storage needs next year, or even next week. An organization’s workload requirements might grow five-fold by next year, or next quarter, or next month. With exploding data volumes, organizations are making significant investments in HDFS or S3 data lake infrastructure for storing “cold” data more cost-effectively. Given these volatile and rapidly changing scenarios, how do organizations ensure they can handle dynamic workloads and evolving data analytics requirements, as well as safe-guard their data lake investments?
Moving data in and out of various data stores is time consuming. Provisioning storage and compute resources for worst-case scenarios is costly. To avoid these hassles, organizations should ensure that their analytical platform provide freedom from underlying infrastructure, maximize investments in data lakes, and support their pursuit of cloud economics as well as on premise and hybrid deployments, while unifying the analytics that support them all.
Optimizing analytics for the cloud involves placing data on reliable and durable shared storage, separating storage from compute (along with the right amount of local cache), and matching the performance requirements of existing workloads. This allows organizations to tie data platform costs directly to business needs by provisioning just the right amount of compute resources for queries and just the right amount of storage resources for data. The ability to scale up and down the cluster elastically to accommodate analytic workload peaks and troughs results in lowered infrastructure cost and maximum business value. When separation of compute and storage is architected with cloud economics in mind, it results in greater operational simplicity and workload isolation to meet SLA and business stakeholder objectives – a win-win for any IT organization.
Separation of Compute and Storage in Action
Cloud economics and the separation of compute and storage bring even greater flexibility and financial viability to organizations looking to capitalize on the promise of big data and advanced analytics. Advanced analytics is changing the way companies across every industry operate, grow, and stay competitive. Let’s look at a few use cases that can benefit from this architecture.

(mmar/Shutterstock)
Consider a medical equipment manufacturer that is going to market with a smart medical device embedded with more sensors than ever before. Before formally launching, they need to run a trial at their key customer accounts. By separating compute and storage, the manufacturer can optimize its resources to analyze the early-release testing data so that they benefit from maximum reliability upon the mass release.
Retailers who separate compute and storage can also strengthen their abilities to analyze seasonal sales patterns. Though analytic workloads in retail settings vary based on volume, they still require maximum dashboard performance – regardless of the number of concurrent users – so that key members can gain access to important sales metrics.
Engagement analysis can be streamlined with the separation of compute and storage, too. For instance, think of a gaming company that is about to introduce a brand-new game. Prior to launch, they must increase their analytical capacity so that they can evaluate success based on customer insights. This architecture would enable them to deliver real-time analytics during critical stages of the product launch, such as a special event or tournament, so that they can swiftly make modifications that better appeal to their community.
Understanding the Financial Benefit
These real-world examples can really be applied to any organization that relies on analytics. To truly grasp the immense cost savings by leveraging the separation of compute and storage capabilities, let’s elaborate on the retail use case.
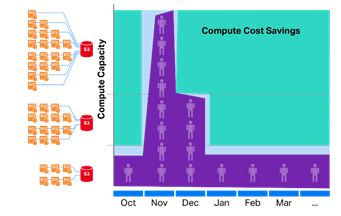
Retailers struggle to accommodate the busiest shopping season of the year in the U.S., which begins late on Thanksgiving Thursday, continues through Black Friday and into the weekend, and concludes on Cyber Monday. The retailer must increase their compute capacity just for this seasonal peak – maybe a partial peak after Cyber Monday until about ten days after New Years once the returns are all in. For the rest of the year, the retailer is operating within a nominal compute capacity. Let’s break it down:
Assuming that the retailer needs:
- 20-node cluster for the Thanksgiving weekend and Cyber Monday
- 12-node cluster until after New Year, and
- Six nodes for the other months of the year

Scaling capacity to workload (figure) offers significant cost savings. A traditional solution (provisioned for peak workload year-round) vs. separating compute and storage will deliver savings of approximately 66 percent just in compute costs.
Perhaps the workload is uniform, just periodic. For short-term projects, separating compute and storage enables “Hibernating.” Hibernating lets you shut down all compute nodes until you need them again. Come out of hibernation when your project starts up again by simply creating a new cluster and reviving your database.
Lastly, most organizations have use cases requiring consistent compute requirements, as well as use cases that have variable compute need. Businesses need to support the right use cases today, knowing with certainty that they may change in the future. To achieve that end, seek options to buy compute power only when needed and reduce storage costs based on use case requirements. But, deployments in the cloud are always likely part of a larger, more hybrid strategy that needs to be kept in mind.
Next Steps
With so many existing as well as emerging SQL and NoSQL databases, query engines, and data warehouses options coming to market, businesses are feeling the pressure to understand how their data analytics platform can maximize cloud economics, while, naturally, deriving timely insights. This is even more important as the key attributes driving cloud adoption are operational simplicity, just-in-time deployments, and elastic scaling of resources. The separation of compute from storage provide maximum flexibility and enables organizations to minimize resource burden and maximize business value.
As cloud vendors continue to lower the price of storage and compute services, organizations have even more incentive to move their data to the cloud, especially for variable workloads and use cases that require heavy compute for finite periods of time. This is particularly attractive for New Economy businesses that have not yet earmarked the capital outlays and built out data centers to handle peak compute and storage needs – however rare or infrequent these peaks happen. In contrast, cloud economics enable organizations to pay for only what they need, when they need it. If this scenario sounds familiar, then the question that your organization should ask itself is: “How do I take advantage of cloud economics without being penalized for fluctuating requirements and dynamic workloads?”
 About the author: Jeff Healey is the Senior Director of Vertica Product Marketing at Micro Focus. Jeff leads the product marketing team and digital property for the Vertica Advanced Analytics Platform. With more than 20 years of high-tech marketing experience and deep knowledge in messaging, positioning, and content development, Jeff has previously led product marketing for Axeda Corporation (now PTC). Prior to Axeda, Jeff held product marketing, customer success, and lead editorial roles at MathWorks, Macromedia (now Adobe), Sybase (now SAP), and The Boston Globe.
About the author: Jeff Healey is the Senior Director of Vertica Product Marketing at Micro Focus. Jeff leads the product marketing team and digital property for the Vertica Advanced Analytics Platform. With more than 20 years of high-tech marketing experience and deep knowledge in messaging, positioning, and content development, Jeff has previously led product marketing for Axeda Corporation (now PTC). Prior to Axeda, Jeff held product marketing, customer success, and lead editorial roles at MathWorks, Macromedia (now Adobe), Sybase (now SAP), and The Boston Globe.
Related Items:
How Erasure Coding Changes Hadoop Storage Economics
Leading Solution Providers

















