


May 30, 2018
Opening Up Black Boxes with Explainable AI

(amasterphotographer/Shutterstock)
One of the biggest challenges with deep learning is explaining to customers and regulators how the models get their answers. In many cases, we simply don’t know how the models generated their answers, even if we’re very confident in the answers themselves. However, in the age of GDPR, this black box-style of predictive computing will not suffice, which is driving a push by FICO and others to develop explainable AI.
Describing deep learning as a black box is not meant to denigrate the practice. In many instances, in fact, the black box aspect of a deep learning model isn’t a bug – it’s a feature. After, all, we’re thrilled that, when we build a convolutional neural network with hundreds of input variables and more than a thousand hidden layers (as the biggest CNNs are), it just works. We don’t exactly know how it works, but we’re grateful that it does work. If we had we been required to explicitly code a program to do the same thing as the CNN does, it likely would be a complete disaster. We simply could not build the decision-making systems we’re building today without the benefit of self-learning machines.
But as good as deep learning has gotten over the past five years, it’s still not good enough. There simply isn’t enough free goodwill floating about our current world for a hundred-billion-dollar corporation or a trillion-dollar government to tell its consumers or citizens to “trust us” when making life-changing decisions. It’s not just a wary public, but also skeptical regulators buoyed by the GDPR’s new requirements for greater transparency in data processing, that’s driving for greater clarity in how today’s AI-based systems are making the decisions they make.
One of the companies on the cutting edge of helping to make AI more explainable is FICO. The San Jose, California-based company is well-known for developing a patented credit scoring methodology (the “FICO score”) that many banks use to determine the credit risk of consumers. It also uses machine learning tech in its Decision Management Suite (DMS), which companies use to automate a range of decision-making process.

Neural networks leverage complex connections to find correlations hidden in data (all_is_magic/Shutterstock)
Before joining FICO two years ago, FICO Vice President of Product and Technology Jari Koister worked at Salesforce.com and Twitter, where the use of cutting edge machine learning technologies and techniques was widely accepted – perhaps expected – as a means of doing business. But FICO’s clients are more conservative in their adoption. “A lot of our customers cannot really deploy machine learning algorithms in a lot of contexts,” Koister says.
Koister relayed the story of a big European bank he had contact with that was considering using a deep neural network to help it detect fraud. However, even though there wasn’t a specific regulation preventing its use for fraud detection, the bank elected not to use the deep learning approach because of a general lack of explainability, Koister says.
“They felt internally the need to be able to explain that if something is classified a fraud, they need to understand why,” he tells Datanami. “It doesn’t just have to do with regulation. It also has to do with just the confidence that when deployed, you can understand why the system is doing what it’s doing.”
That experience helped convince Koister that something needed to be done about the explainability problem. Over the past two years, he and his AI team of have worked to address the problem. The team initially worked with the University of California at Irvine on the LIME project, but Koister says LIME wasn’t precise enough, and just wasn’t up to snuff.
“It’s definitely not the best solution,” Koister says of LIME. “But it got a lot of attention because it was the first ones to really try and publicize a general technique for any machine learning model. We’re actually sponsoring their research to take the next step.”
So Koister’s FICO team started developing its own technique for making AI explainable. At the FICO World conference in April, the company rolled out the first release of what Koister’s team has been working on. They call it, fittingly enough, Explainable AI.
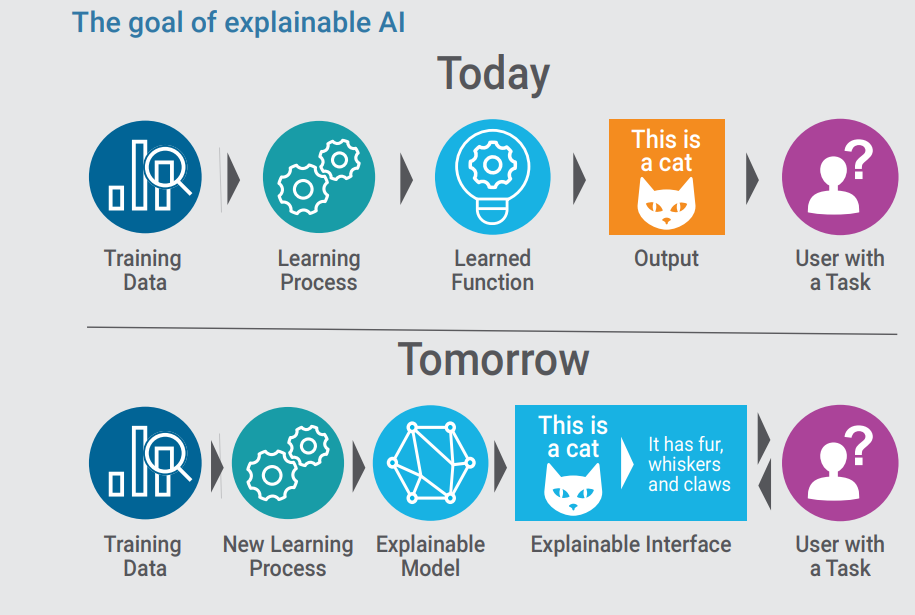
According to Koister, Explainable AI has several components, but the key one is a mechanism for “exercising” the model and showing customers how different inputs directly lead to different outputs.
“We actually have machinery that exercises the model and extracts out a whole range of different characteristics [so customers] can see for different inputs, what kind of outputs they’re generating,” he says. “We’re essentially opening up the black box and saying ‘This is how the model behaves on all the data.'”
For example, say a customer is seeking car insurance. There are a range of factors that the insurance company would consider before generating a quote, including age, gender, accident history, address, car type, and annual mileage, among other factors. If the customer does not like the terms of the initial insurance offer, they may ask what they can do to lower the premium.
If the company used a black box decision-making engine, it would be pointless to try to explain how it works to the prospective insurance customer. (A data scientist would probably be challenged to explain it to another data scientist, too.) Instead, FICO is taking a brute-force approach and literally running the model over and over again, with different inputs, to show the customer what actual knobs and levers they can twist and pull to influence the model’s outcome.
“Do they need to move or change cars? Or drive another year without any accidents?” Koister says. “There’s no way, since it’s a black box, to understand it. We present that back. We tell you exactly ‘This is what would get you into another range of cost and these are the things you would need to change.’ In our mind, this is a very important piece for explainabiltiy. It’s not only to show what it is, but also to show how can you influence the model.”![]()
The company has received positive feedback on its approach to Explainable AI, including from the Defense Advanced Research Projects Agency (DARPA), which last year launched its Explainable Artificial Intelligence (XAI) program. When DARPA representatives got wind of FICO’s work, they reached out to the company to learn more. In fact, Koister recently attended a DARPA workshop to share more details of FICO’s approach.
Explainable AI is now part of the Data Science Workbench in FICO’s DMS. The software works with three types of machine learning models, including XGboost, Random Forest, and neural networks. Organizations that adopt Explainable AI will be able to generate “certificates of explanation” (either in the form of an actual document or a UI widget) that give customers or prospects greater insight into why their automated decision-making systems generated the offer or charged the price that they did.
“We’re clearly at the cutting edge with respect to helping people really understand and open up to what is a black box, to make it a white box,” Koister says. “With that said, we’re not done here. We’re going to continue working on this. It’s a very active area and we have more visionary goals for what we want to do with explainabilty. But we feel that we already have something that really helps people understand what’s going on and get the confidence and trust in the models.”
To push the state of explainable AI even further, FICO is running its Explainable Machine Learning Challenge. The goal of the challenge is to identify new approaches to creating machine learning models with both high accuracy and explainability. The challenge, which was launched in December and uses sample mortgage application data supplied by FICO, is sponsored by UCI, Cal Berkeley, Oxford University, MIT, Google, and Imperial College London. The deadline for submission was recently extended to August 31.
Related Items:
Ensuring Iron-Clad Algorithmic Accountability in the GDPR Era
Keeping Your Models on the Straight and Narrow
Scrutinizing the Inscrutability of Deep Learning
Editor’s note: This article has been corrected. The big European bank referenced by Koister was considering building its own deep learning models, not using FICO’s deep learning capability. Datanami regrets the error.
Leading Solution Providers

















