


February 27, 2019
Can On-Prem S3 Compete with HDFS for Analytic Workloads?

(David Brimm/Shutterstock)
In the battle for big data storage supremacy, Hadoop is still in the running. It may no longer be the 800-lb gorilla, but the demonstrated scalability of the Hadoop Distributed File System (HDFS) makes it a potent contender, especially for storing petabytes on-prem. Now a new class of S3-compatible object storage systems threaten HDFS’s on-prem supremacy, but can they compute like Hadoop?
Ever since Amazon‘s Simple Storage Service (S3) emerged as the defacto standard for cloud storage, big data architects have been working to make the S3 protocol excel on-premise too. The Hadoop community still would like an S3 object store option for their on-prem Hadoop clusters, even after HDFS became more object-like with the addition of erasure coding and the beginning of the separation of compute and storage in Apache Hadoop 3.
But the marriage of Hadoop compute and object storage still has a ways to go. Last year, Cloudera founder and Chief Strategy Officer Mike Olson lamented the immaturity of the on-premise object store market. “S3 likely will be what everybody adopts,” he told Datanami, “but somebody needs to be the variant of S3 on-prem that takes over the market so we can just go to that one.”
Nearly two dozen object storage vendors are competing to win that business and become the dominant storage provider for data lakes that hold more than 1 petabyte of largely unstructured data. It’s a work in progress, and Cloudera is content to let the process play out without planting a stake in the ground. “You would not believe how expensive it is to support a new object storage system,” Olson said at last fall’s Strata Data Conference. “It touches every single component” of the Hadoop stack.
These object stores face a number of challenges to integrating with the Hadoop stack, and a failure to ensure the low-level integration is bullet-proof could have devastating consequences for security and performance, Olson warned.
Apache Hive was designed to process data stored in HDFS, and it opened up a new world of big data processing, even if it lacked performance for the toughest ad-hoc workloads. Some of Hive’s weaknesses in this department were rectified with the emergence Presto, which arguably is the highest performing SQL analytics engine for Hadoop today (and the fact that Presto works with other storage back-end makes its story that much sweeter).
Can an object storage system meet or exceed the performance of Presto on HDFS? Cloudian, the , the San Mateo, California-based developer of an S3-compatible distributed object storage system called HyperStore, thinks it can.
HDFS Vs. S3 Showdown
Cloudian recently shared with Datanami the results of a benchmark test that it claims proves it can run with the big yellow elephant. The document, which was prepared by Cloudian Software Engineer Tatsuya Kawano and Gary Ogasawara, its vice president of engineering, compared the performance of four different combinations of SQL query engine and storage system, including:
1. Hive and HDFS 2. Hive and S3 (Cloudian HyperStore) 3. Presto and HDFS 4. Presto and S3 (Cloudian HyperStore)
“We used HiBench’s SQL (Hive-QL) workloads with ~11 million records (~1.8GB) and TPC-H benchmark with ~866 million records (~100GB),” they write. “CDH5 (Cloudera Distribution Hadoop v5.14.4) was used for the Hadoop and HDFS implementation. For S3-compatible storage, we used Cloudian HyperStore v7.1 that implements the Amazon S3 API in a software package that can be deployed on Linux.”
HiBench is a big data benchmark suite
Source: Cloudian
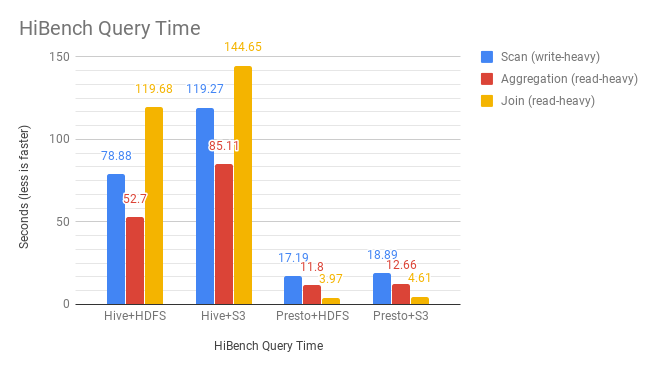
developed by Intel that helps to evaluate different big data products in terms of speed, according to Kawano and Ogasawara. It has three workloads – scan, aggregation, and join – that exercises the read and write capability of the computer program.
The results of the HiBench benchmark, which used data stored in SequenceFile format, showed that Presto outperformed Hive on both HDFS and S3 storage back-ends. For write-heavy query, the combination of Presto and S3 was over 4x faster than Hive and HDFS, Cloudian found, while for read-heavy queries, Presto and S3 was over 15x faster than Hive and HDFS.
The combination of Presto and HDFS still outperformed Presto running on S3, Cloudian found. But not by much.
The TPC-H benchmark, meanwhile, simulates a real-world OLAP (Online Analytical Processing) workloads in a data warehouse context. Presto can run unmodified TPC-H queries, which are ANSI SQL compliant, and has its own TPC-H connector to generate TPC-H datasets, Kawano and Ogasawara write. “Hive cannot directly run TPC-H queries,” the write, “but we found a couple of Hive-QL implementations of TPC-H on GitHub and we used one of them.”

Source: Cloudian
The test involved over 100GB of data that was composed of files stored in the ORC format with ZLIB compression, according to the researchers’ paper. They only measured Hive on HDFS, Presto on S3, and Presto on HDFS. “We did not measure Hive+S3 performance because from [the] HiBench results, we expected it will be slower than all other combinations and we might not be interested in the result.”
Presto and S3, on average, was 11.8 times faster than Hive+HDFS, according to the test results. However, in every TPC-H test category, Presto on HDFS was faster than Presto on S3.
Presto is so much faster than Hive because it runs in-memory, “so it does not write intermediate results to storage (S3),” Kawano and Ogasawara write. “Presto makes much fewer S3 requests than Hive does. In addition, unlike Hive M/R [MapReduce] jobs, Presto does not perform rename file operation after writes. Rename is very expensive operation in a S3 storage system as it is implemented by copy and delete file operations. Finally, Hive’s architecture requires it to wait between stages (M/R jobs), making it difficult to keep utilizing all CPU and disk resources.”
When looking at the results of both benchmark tests, Cloudian concluded that both Presto configurations “substantially outperformed” the two Hive configurations by roughly a factor of 10. When Kawano and Ogasawara ranked the program combinations from best performing to worse performing, it looks like this:
1. Presto and HDFS (best) 2. Presto and S3 3. Hive and HDFS 4. Hive and S3 (worst)
“The Presto+S3 combination showed very similar performance results to the best Presto+HDFS combination,” Kawano and Ogasawara write, “demonstrating that Hadoop users can achieve the flexibility and cost advantages of separating storage and compute with S3 software, without any significant tradeoff in performance.”
Related Items:
Mike Olson on Zoo Animals, Object Stores, and the Future of Cloudera
Data Lake Showdown: Object Store or HDFS?
Cloud In, Hadoop Out as Hot Repository for Big Data
Applications:
Enterprise Analytics
Sectors:
Financial Services
Tags:
benchmark, CDH, Cloudian, Hadoop, HDFS, HiBench, Hive, HyperStore, object store, on-premise, presto, s3, TPC-H
Leading Solution Providers

















