


May 23, 2019
How Dark Data, DevOps, and IT Complexity Are Hurting Security

(Africa Studio/Shutterstock)
Despite the lip service paid to being “data-driven,” the average organization fails to collect or process more than half of the data it generates, according to a new report from Splunk. From an operational standpoint, this dark data represents a real security risk, particularly with today’s serverless architectures and fast-pace DevOps culture, Splunk’s CTO says.
Splunk published “The State of Dark Data” last month with the aim of helping business leaders to close the gap between AI’s potential and today’s data reality. The big takeaway from survey was this: 55% of organizations’ data is “dark,” which means they either don’t know it exists or it’s not being utilized.
The majority of the dark data is log data, according to Splunk. This log describes what customers, users, transactions, applications, servers, networks and mobile devices are doing in an organization’s IT infrastructure. It can also consist of configurations, message queues, output of diagnostic commands, call detail records, or sensor data from industrial systems, or even sentiment data from social media.

Splunk surveyed more than 1,300 people for its “The State of Dark Data” report
Companies are mostly capitalizing on the higher-order data that gets funneled into their transactional systems, says Splunk CTO Tim Tully. These are not big sources of dark data, he says.
“It’s not going to be your CRUD or relational databases,” Tully says. “Those are going to have a lot of rows, but typically those types of databases have narrow schemas. So it’s going to be log traffic and logs from all the devices on the network, for the most part.”
The 55% figure took Tully by surprise. “That number was a bit higher than what I honestly expected,” says Tully, who previously bore responsibility for hundreds of thousands of servers globally as Yahoo’s chief data architect. “I was thinking 25% or below, but 55% definitely blew me away.”
There are several repercussions for letting more than half of one’s log data slip through the digital net. For starters, it kind of renders the whole “we are data-driven” mantra moot. More than four out of 10 survey respondents admitted that “data driven is just a slogan at my organization.”
But more importantly, all this dark data can hurt security, Tully says. “You can imagine if you’re not looking at half the logs, you’re overlooking half the possible attacks that are coming against you,” he says. “It’s a lost opportunity to build a stronger security posture.”
Splunk, which develops one of the industry’s top-rated security information and event management (SIEM) solutions, is obviously looking to bolster its own case with the report on dark data. But just having Splunk or any one of a number of other SIEM tools installed won’t help unless the data is being actively collected, Tully says.
“If you’re not collecting half of your firewall log data beaus it’s dark for whatever reason, then you’re rendering your SIEM product useless,” he says. “They’re useless if they’re not using them.”
The report highlights several reasons why so much dark data exists. Maybe an organization thinks the data is too old, or it’s in a format that’s can’t be readily accessed. Or maybe the data is too dirty to be useful without extensive cleaning. Or maybe the organization just doesn’t have the time to deal with it, the study says.
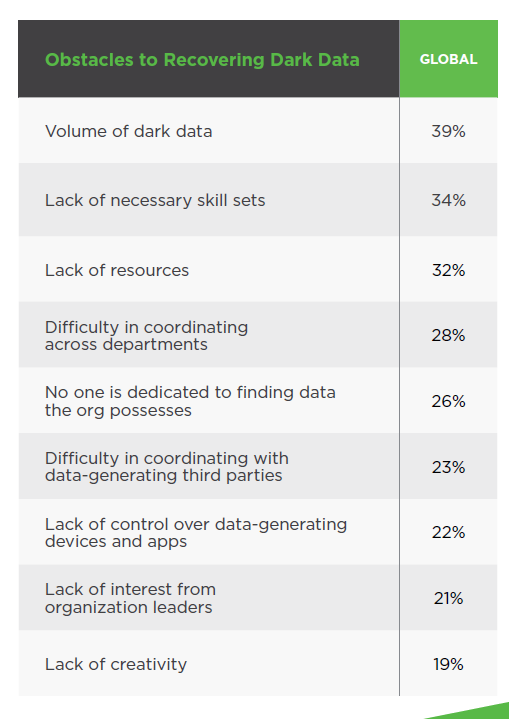
(Source: Splunk’s “The State of Dark Data”)
Those are all valid reasons why dark data exists. But Tully has another take on why there’s so much of it around: our IT infrastructures are growing increasingly distributed and complex, and our fast-pace DevOps culture doesn’t allow time for deep instrumentation.
“It’s also a function of how corporations and big companies are laying down their application architecture,” Tully tells Datanami. “We no longer have these full-stack applications servers anymore. Now everything is microservices running inside of Docker containers running inside of Kubernetes that are using Istio and Envoy for service mesh. There’s a lot of logs generated from all of that, so the infrastructure is getting more complex. And then the application is more distributed horizontally, so there’s more and more logs to collect.”
Another cause of dark data is the quickening pace of IT development, Tully says.
“People who build these application are shipping all the time,” he continues, “and when you’re shipping all the time, you can easily add bugs to the software where the logging gets deactivated for whatever reason because of a config file changed or a line of code was commented out. So it’s very easy to have this happen when the ground underneath you is shifting all the time.”
Human negligence is at the root of many problems in this world, and so it should come as no surprise that harried application developers — who are asked to adopt the latest technologies — is also contributing to an elevated risk of security breaches.
Don’t expect this problem to resolve itself anytime soon, Tully warns. “It’s hard to keep track of devices coming up and coming down, especially with the advent of serverless and container-based architecture,” he says. “It’s very easy for these ephemeral services to get lost in the shuffle.
“I actually think this problem is going to get worse over time,” he says.
You can access Splunk’s report, which involved more than 1,300 people from around the world, at Splunk’s website.
Related Items:
‘Dark Data’ Continues to Stymie Analytics Efforts
Beware the Dangers of Dark Data
Connecting the Dots on Dark Data
Applications:
Security
Sectors:
Financial Services
Vendors:
Splunk
Tags:
agile, config changes, dark data, DevOps, Docker, firewall, Kubernetes, logs, security, serverless, SIEM, splunk
Leading Solution Providers

















