


September 5, 2019
StreamSets Eases Spark-ETL Pipeline Development

Apache Spark gives developers a powerful tool for creating data pipelines for ETL workflows, but the framework is complex and can be difficult to troubleshoot. StreamSets is aiming to simplify Spark pipeline development with Transformer, the latest addition to its DataOps platform. The company also unveiled the beta of a new cloud offering.
StreamSets, which is hosting its annual user conference this week in San Francisco, is making a name for itself in the big data world with its DataOps platform. The suite’s main focus is to simplify the task of creating and managing the myriad data pipelines that organizations are building to move data to where they need it, with all the requisite security, governance, and automation features that users demand.
The new Transformer software unveiled today sits in the Data Plane portion of Streamsets DataOps platform, which is where the data pipelines are created and managed. The other portion of DataOps is Control Plane, which is basically a configurable GUI management console.
After creating a new data pipeline in its drag-and-drop GUI, Transformer instantiates the pipeline as a native Spark job that can execute in batch, micro-batch, or streaming modes (or switch among them; there’s no difference for the developer).
With Transformer, StreamSets aims to ease the ETL burden, which is considerable. “Our initial goal is to ease the burden of common ETL sets-based patterns,” the company tells Datanami. “ETL and related activities have to be done to produce results in the downstream analytics, but often new technology like Apache Spark is not easily adopted across every organization.”
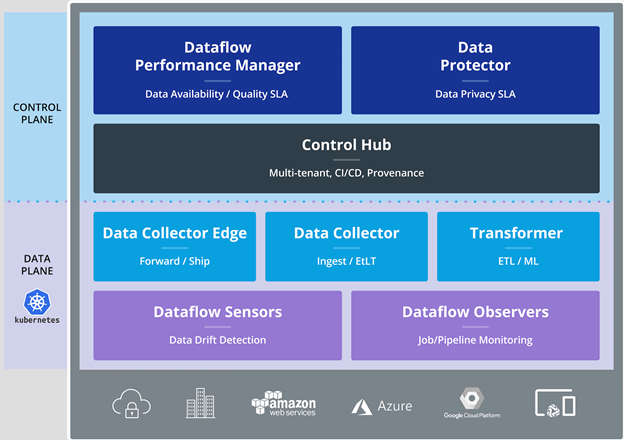
The StreamSets DataOps platform
The explosion of big data is changing the design patterns at organizations, StreamSets says. Gone are the days when the application design would dictate the type of data. It’s flipped around, and today organizations are looking to tailor their applications based on the available data. The whole DataOps platform – and Transformer specifically – simplify the creation of the pipelines that move data to the applications.
“Data pipelining is a necessary evil at any data-driven organization today, regardless of appetite,” StreamSets says. “The days where all insightful data lived within the walls of the EDW are far gone. Static connections to enterprise systems aren’t flexible enough to work with modern platforms.”
The new offering will leverage the power of Spark without exposing users to some of the burdensome intricacies of the distributed, in-memory framework, including monitoring Spark jobs and error handling. “In essence, StreamSets Transformer brings the power of Apache Spark to businesses, while eliminating its complexity and guesswork,” said StreamSets CTO Arvind Prabhakar.
Transformer works with other components of StreamSets Data Plane offerings, including Data Collector, which offers over a hundred connectors for source and destinations data repositories. Data Collector Edge, Dataflow Sensors, and Dataflow Observers tackle IoT, data drift, and pipeline monitoring, respectively; the whole DataPlane suite runs on Kubernetes.
ETL is a main focus, but it’s not the only use case for Transformer. The new offering will also support SparkSQL for utilizing the SQL processing capabilities of Spark. StreamSets says it contains custom Scala, Tensorflow and Pyspark processors, which allow users to design machine learning workloads “out of the box.” More machine learning and complex event processing functionality will be delivered later this year, the company says.
Meanwhile, the San Francisco company also announced the launch of its new cloud offering, StreamSets Cloud. While customers have already run one or more parts of the DataOps suite on the cloud, this is the first time that StreamSets has gotten into the software as a service (SaaS) business.
StreamSets is targeting a “cloud first” type of user with StreamSets Cloud.
“The existing StreamSets DataOps Platform (including StreamSets Data Collector, Control Hub, and Transformer among other products) is designed for enterprises that have a wide variety of data integration use cases and design patterns,” the company says. “On the other hand, StreamSets Cloud is a cloud-native SaaS that is optimized for the needs of cloud-first users who are redefining how data platforms are built and consumed.”
In the cloud, StreamSets users will get a point-and-click data pipeline building experience, without the need to install and maintain execution engines, the company says. The offering will also be tailored to common cloud use cases, such as ingesting data into cloud data warehouse and data lakes. And it will take full advantage of the scalability of cloud hosting environments, the company says.
The cloud is fast becoming where the majority of StreamSets customers are moving data to or from, the company says.
“More and more of our customers are adopting cloud data platforms such as Databricks, Snowflake and Azure, and we have seen that increase steadily in the last few years,” it says. “In particular, the adoption of cloud data warehouses and data lakes is taking off, and many of our customers are migrating from on-premises warehouses and lakes to cloud, or utilizing both for different use cases and synchronizing data across their hybrid environment.”
The beta for StreamSets Cloud will open in the coming weeks. Interested participants can pre-register here.
Related Items:
StreamSets Balances Streaming Data Demands for Security, Access
Applications:
Enterprise Analytics
Leading Solution Providers

















