


November 20, 2019
Confluent Reveals ksqlDB, a Streaming Database Built on Kafka

Confluent narrowed the distance separating Kafka-esque stream data processing and traditional database technology with today’s unveiling of ksqlDB, a new database built atop Kafka that the company intends to be the future of stream processing.
We got an early glimpse of ksqlDB at Kafka Summit last month, when CEO Jay Kreps talked about making Kafka function more like a database. This came as a bit of a shock to some Kafka types, as Kreps and other Kafka leaders have traditionally talked about the shortcomings of traditional databases when developing cutting edge applications. In fact, Confluent co-founder Jun Rao had just talked about those shortcomings the day before Kreps’ keynote.
But it turns out that the database mentality is hard to break. And in fact, the database is actually pretty good at certain things — like maintaining state and serving queries based on that state – that stream processing systems have a hard time with.
So rather than trying to force a square peg into a round hole, so to speak, the folks at Confluent decided to make a database a first-class citizen in the Kafka scheme of things. (A better cliché might be “If you can’t beat ‘em, join ‘em.”)
ksqlDB is all about reducing the complexity for developers looking to build real-world stream processing applications, says Confluent’s product manager for ksqlDB, Michael Drogalis.
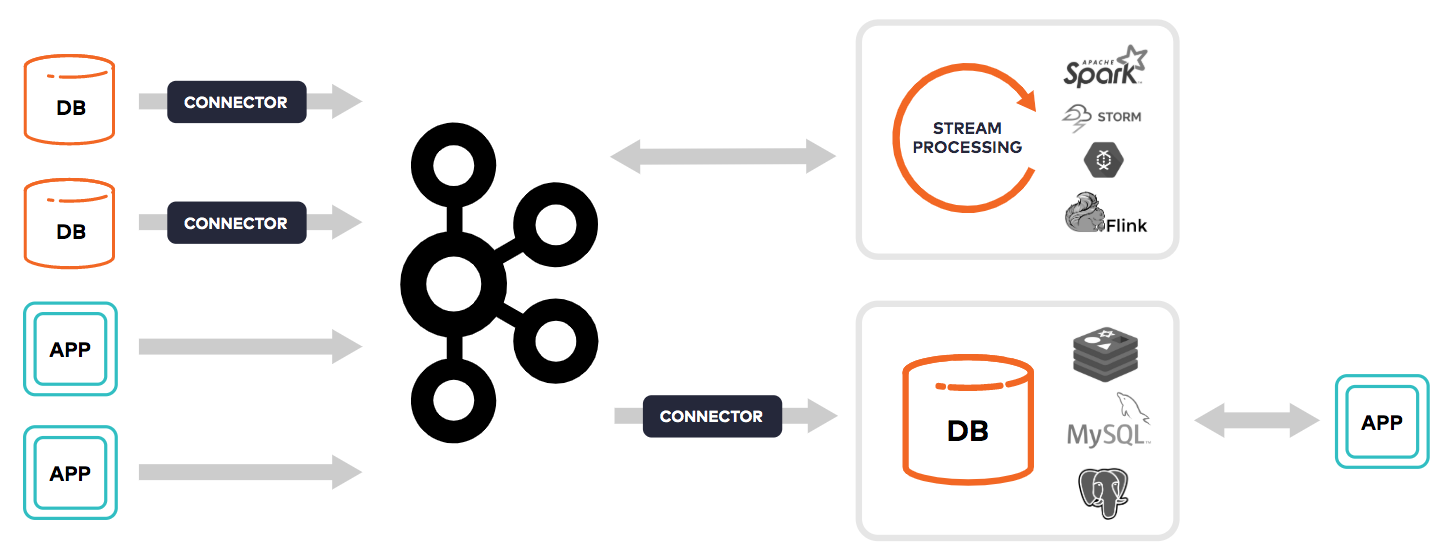
The current state of stream processing requires a complex mix of databases and connectors (image courtesy Confluent)
“When you embark on building one these stream processing systems, you have a bunch of different things in all these architectures,” he tells Datanami. “You have some kind of connector or agent to harvest data from outside systems. You have somewhere to store these events durably. You have some way to process these events. And then you have some sort of data storage to serve queries to applications.
“These are really necessary parts of building a stream processing application,” Drogalis continues. “But it is the case that they tend to all be different, and in the real world, you tend to use different vendors for different parts. They don’t really fit together very well. They have different mental models for scaling and securing and monitoring. And so when you go to make a change, you have to think in these three to five different ways to pull it off. That’s just an incredible amount of complexity that makes people not able to use these kinds of systems for really good ideas. We want to make it easier. I think this is a good way to pull it off.”
There are two key new features that ksqlDB exposes to Kafka developers.
The first is the ability to perform a “pull query,” which is differentiated from the “push queries” that Kafka clusters traditionally have been constantly streaming out. This is critical when developers need to query the state of something. ksqlDB uses RocksDB, a fast key-value store developed by Rockset.
Confluent has always used RocksDB in Kafka Streams, its stream processing engine. The change is that Confluent has developed and exposed an API that allows Kafka users to actually query data stored in the database.
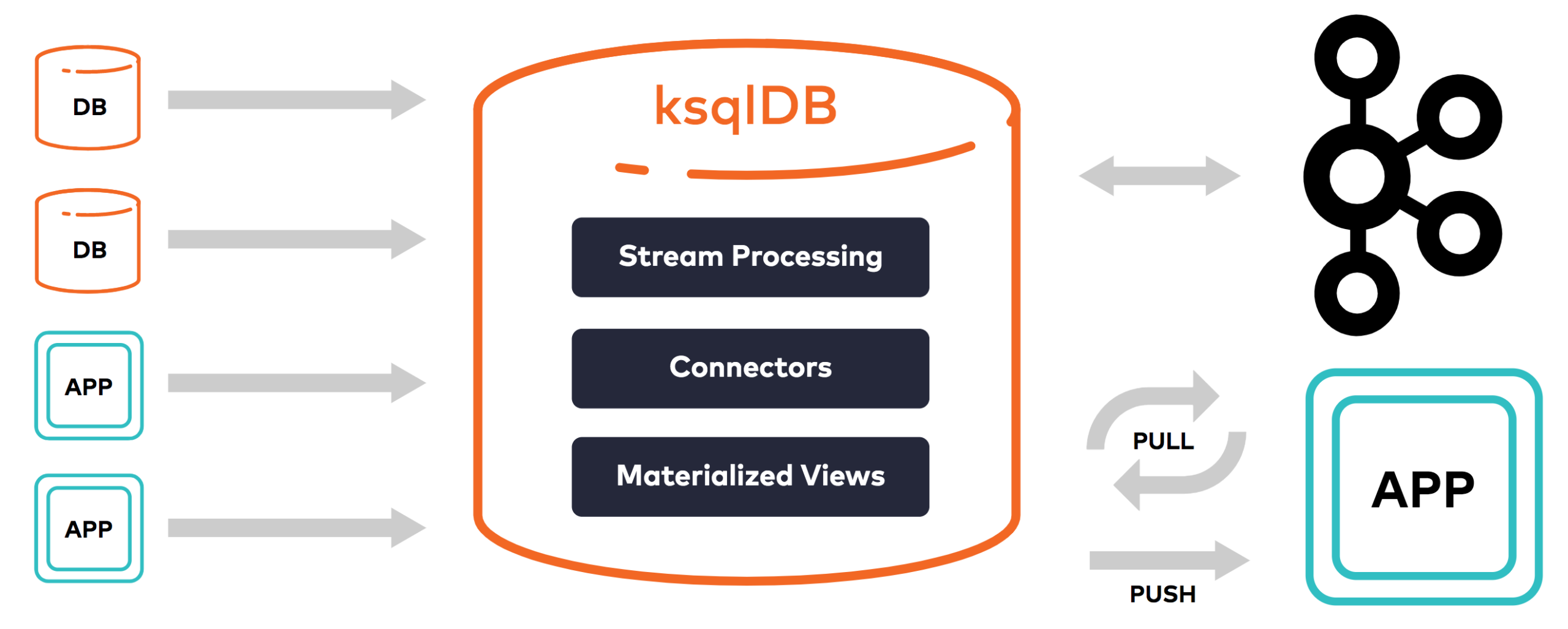
With ksqlDB in the mix, the stack is reduced and complexity minimized (image courtesy Confluent)
The second key feature that ksqlDB brings is the ability to reach out to other databases and storage systems to access data. This was done by enabling Kafka Connect connectors to work with the new RocksDB-based query engine that Confluent is exposing.
“Often the data you want to work with isn’t in Kafka yet,” Kreps writes in a blog post published today. “Perhaps it is in one or more traditional databases, SaaS application APIs, or other systems. Kafka Connect has a great ecosystem of prebuilt connectors that can help you to continuously ingest the streams of data you want into Kafka as well as to continuously export the data out of Kafka again. In the past, you’d have to work across multiple systems: Kafka, Connect, and KSQL, each of which is a bit different in its interface. Now, ksqlDB allows you to directly control and execute connectors built to work with Kafka Connect.”
As Drogalis explains, it’s about eliminating the need to maintain multiple mental models.
“Data tends not be born in Kafka. It exists in data sets that were there before or more suited to have landed the data into,” he says. “You need to set up a Kafka Connect cluster to really manage the movement of data to and from Kafka. So, much like database architecture, this is another moving piece with a different mental model. It’s quite easy for people to simply be able to write a SQL statement in KSQL that launches a connector straight inside the server. No extra infrastructure to manage. No second mental model. No second way to secure it. That’s the idea.”![]()
ksqlDB is the successor to KSQL, according to Confluent. The company is making no bones about the fact that it’s embracing database concepts with its Confluent software, which is based on open source Apache Kafka but licensed in a different manner. Despite the embrace of databases, Confluent leaders say their strategy has not changed. In fact, with ksqlDB, Confluent is making the argument that it’s re-assembling the various pieces of database architecture that had previously been broken up. Call it a refocus on ease-of-use for developing distributed computing systems, with a modern monolithic sentiment.
“No, the strategy hasn’t changed,” Drogalis says. “Kafka certainly represents one of the most fundamental part of a database, which is a distributed commit log. The number of pieces to build something that looks like a database been growing over time. You not only have the commit logs. You have state stores. You have replication. You have data extraction and loading. And you have them in all these different components. And KSQL DB really represents the consolidation of many of these components into something that’s actually quite a bit easier to use to build these stream processing applications.”
ksqlDB may be Confluent’s new approach for building streaming applications, including real-time systems like the one that powers Lyft’s ride-sharing application and other similar applications. Building these types of systems typically requires cobbling together many disparate systems, and Confluent is betting it will garner support in the developer community by alleviating some of the technical burden by consolidating these functions into its tools.
But not all Kafka workloads will benefit from ksqlDB. In addition to full-blown stream processing applications built atop libraries like Kafka Streams, lots of companies use core Kafka to assemble the basic data pipelines to move data among different systems. For these use cases, which Drogalis estimates is the second major use case for Kafka (behind streaming), an integrated database will bring no benefit.
ksqlDB is a “source-available” product, which means the source code can be viewed by clients who obtain the software from Confluent under the Confluent Community License. Bits are available for download on its GitHub page and more information can be found at www.ksqldb.io.
Related Items:
Kafka Transforming Into ‘Event Streaming Database’
When Not to Use a Database, As Told by Jun Rao
Higher Abstractions, Lower Complexity in Kafka’s Future
Editor’s note: This article was corrected. ksqlDB is not an open source product. It is a “source available” product. Datanami regrets the error.
Applications:
Complex Event Processing
Technologies:
Middleware
Leading Solution Providers

















