


July 6, 2020
Data Prep Still Dominates Data Scientists’ Time, Survey Finds

(BEST-BACKGROUNDS/Shutterstock)
Data scientists spend about 45% of their time on data preparation tasks, including loading and cleaning data, according to a survey of data scientists conducted by Anaconda. The company also analyzed the gap between what data scientists learn as students, and what the enterprises demand.
Data cleansing – fixing or discarding anomalous or wrong numbers and otherwise ensuring the data is an accurate representation of the phenomenon it is meant to measure — accounts for more than a quarter of average day for data scientists, followed by 19% for data loading (the “L” in ETL), according to Anaconda’s annual survey.
Data visualization tasks occupied for about 21% of their time, while model selection, model training and scoring, and model deployment each consume 11% to 12% of the day, the survey found.
“We were disappointed, if not surprised, to see that data wrangling still takes the lion’s share of time in a typical data professional’s day,” Anaconda wrote in its report, “2020 State of Data Science: Moving From Hype Toward Maturity.” “Data preparation and cleansing takes valuable time away from real data science work and has a negative impact on overall job satisfaction.”
It could be worse. In some surveys in the past, data prep tasks have occupied upwards of 70% to 80% of a data scientist’s time. That is why so many people have questioned the wisdom of asking highly skilled and highly paid data scientists to do the equivalent of digital janitorial work.

How data scientists spend their time (Image courtesy Anaconda “2020 State of Data Science: Moving From Hype Toward Maturity.”)
So, the sticky situation around asking data scientists to spend the bulk of their time preparing data for analysis continues. “This efficiency gap presents an opportunity for the industry to work on solutions to this problem, as one has yet to emerge,” Anaconda laments.
The 2020 State of Data Science is based on online surveys of nearly 2,400 people from more than 100 countries (not all of whom are data scientists themselves, although they work in the field). In addition to asking about common data science tasks, Anaconda inquired into the languages data scientists use, their favored toolkits, as well as identifying barriers to deployment of machine learning models and adoption of open source technology by other members of the data science team: developers, administrators, and line of business managers.
To no one’s surprise, Python dominated the language question. According to Anaconda’s survey, 47% of data scientists say they “always” use Python, while another 28% say they use it “frequently.” By comparison, only 10% of respondents say they “always” use R, which was the second most-used language in the survey. JavaScript, Java, C, C++, and C# were all in the mix, but Python simply dwarfed (or suffocated?) them in usage.
When it came to data science, it should come as no surprise that Anaconda’s own data science platform—which combines many of the most commonly used tools in the Python and R ecosystems into one easy-to-use bundle–was cited as the most-used toolkit (the sample of users Anaconda used for the survey may have had something to do with that). Interestingly, Anaconda says 44% of its users also use RStudio, which develops a suite of open source tools for R (and Python too).
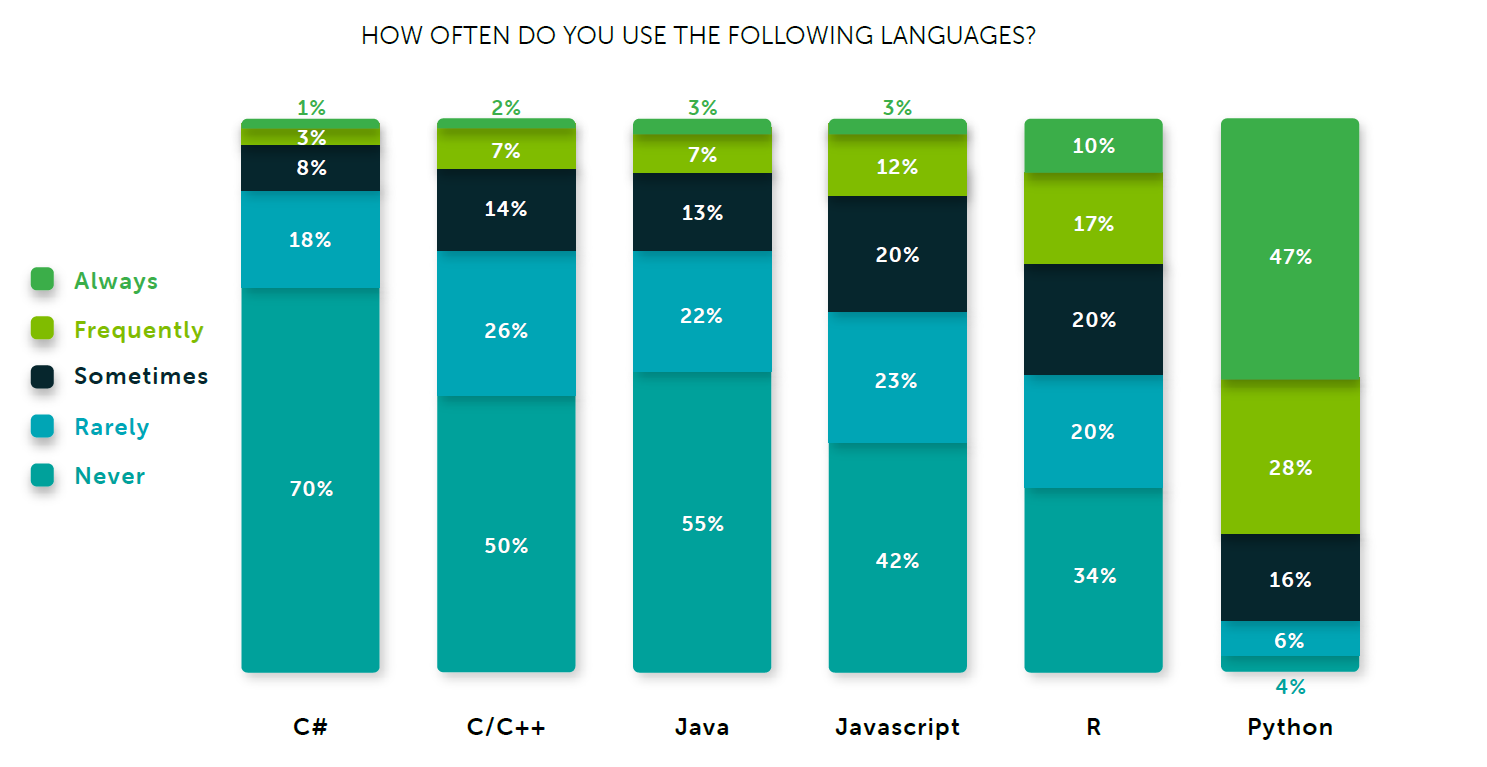
Few people surveyed report not using Python (image courtesy Anaconda’s “2020 State of Data Science: Moving From Hype Toward Maturity.”
“But enterprises are using a number of tools and platforms to deliver on their data strategy, including a mix of proprietary, open-source, and hybrid solutions,” the Austin, Texas, company states in its report. “We hope to see expanded collaboration among industry players to ensure interoperability and harmonization among different tools.”
Why do people use open source technology? According to 27% of the data scientists surveyed by Anaconda, the number one reason is its utility. But developers and business managers see things differently, with 42% of developers citing “speed of innovation” compared to 26% for managers. Systems administrators, ever the misers, cited the economical (i.e. “free”) aspect of open source software as their number one draw.
A similar dynamic appears during deployment. Data scientists cited managing dependencies and environments as the biggest hurdles for models to production (cited by 39%), followed closely by a skills gap with Kubernetes and Docker (38%). However, developers and sys admins were most concerned about security (31% and 37%, respectively). Meanwhile, 27% of developers, meanwhile cited recoding that is often necessary to push Python and R models into production as a major roadblock to deployment.
In terms of skills, Anaconda cited Python, machine learning, and data visualization as the top three skills that students are learning. That jibes somewhat with the list of the top three skills that universities are teaching: Python, probability and statistics, and machine learning.

A gap exists between what students are taught and what enterprises expect (image courtesy Anaconda“2020 State of Data Science: Moving From Hype Toward Maturity”)
However, there’s little resemblance between these two lists and the skills that enterprises say they lack: big data management, advanced mathematics, and deep learning.
“Our study indicates that there are gaps between what enterprises need and what institutions teach,” Anaconda states. “Two of the most frequently-cited skills gaps among respondents working in enterprise environments–big data management (38% of respondents) and engineering skills (26%)–do not rank in the top 10 skills offered in university programs.”
Anaconda also delved into the obstacles preventing younger data scientists from getting their idea job (experience, technical skills, and soft skills were the top three), as well as some of the ethical concerns that data scientists might face when it comes to bias, privacy, diversity, automation, and advanced information warfare.
“Data science has the ability to be transformational for businesses, but our 2020 survey shows that both organizations and professionals in the space are still in the process of maturing,” Anaconda CEO and Co-Founder Peter Wang states in a press release. “From broadening the data science educational curriculum to being more intentional with open-source security, there are clear learnings here for the industry at large to implement in order to improve. We’ve seen positive progress in many of these areas, but there is still work to be done.”
You can download your copy of the 39-page report here.
Related Items:
Anaconda: Data Science Exiting Hadoop for the Cloud
The ‘Big Bang’ of Data Science and ML Tools
Is Python Strangling R to Death?
Technologies:
Frameworks
Leading Solution Providers

















