


September 14, 2020
Stream Processing Is a Great Addition to Data Grid, Hazelcast Finds

(metamorworks/Shutterstock)
In-memory data grids (IMDGs) historically have exceled in applications that require the fastest processing times and the lowest latencies. By adding a stream processing engine, called Jet, to its IMDG, Hazelcast is finding customers exploring new use cases at the cutting edge of high-performance computing.
Hazelcast Jet is a stream processing framework designed for fast processing of big data sets. Originally released in 2017, the open source engine runs in a distributed manner atop the Hazelcast IMDG, which it leverages for high availability and redundancy, as well as a source and a sink for data. Developers use directed acyclic graph (DAG) development paradigm to develop real-time and batch applications with Jet, which also supports Apache Beam semantics.
Other providers of IMDGs and in-memory data stores may claim to support real-time stream processing, says David Brimley, Hazelcast chief product officer. But without support for critical temporal features, such as time windowing and exactly once processing, those other systems are more of a “poor man’s” streaming system, he says.
“You might get some IMDG vendors who don’t have a stream processing technologies that would try to convince their customer in the market that they really are a stream processing engine, but actually they’re not,” he says. “They lack some of the core features you need.”
The combination of Hazelcast Jet and the IMDG gives customers a unique capability to maintain statefulness and act upon fast-moving data in a very low-latency manner, Brimley says. For example, ecommerce companies are taking clickstreams and merging it with known data about customers to generate product recommendations, and banks are running machine learning models to predict whether transactions are fraudulent.
“Now generally what a lot of other stream processing engines do is they reach out to databases and other systems,” Brimley says. “And the combination of our IMDG and Jet, the fact that they can run in the same memory space, means that enrichment process is a lot faster. You’re not making any network hops.”
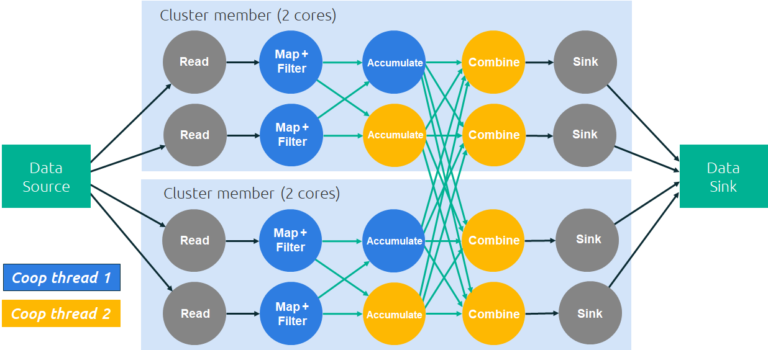
Execution plans in Jet are specified using a DAG (Image courtesy Hazelcast)
The world is awash in Web services and APIs, and Hazelcast will utilize APIs where it makes sense. In fact, the company added support for streaming data into Jet from external databases via APIs in the 4.2 release of Jet in July. But some applications cannot tolerate the extra latency introduced when an API request is sent across the Internet. These are the types of use cases that Hazelcast is gaining traction in, Brimley says.
“That’s where we see our most success, where we’re in situations up against other stream processing vendors, and they want the absolute maximum performance they can drive out of these systems,” he says.
Hazelcast is going up against the likes of other next-generation stream processing systems, such as Kafka Streams and Apache Flink, and winning with Jet, according to Hazelcast CEO Kelly Herrell.
“Word is slowly getting out that we’ve really created the next generation stream processing engine,” Herrell says. “We can work on Kafka. We can work on video files. We can work on stock tickers. We can work on log files. Throw data at Jet, and just watch it work, basically.”
While Jet can work with a Kafka message bus, the product does not require Kafka. “We’re completely homespun,” Brimley says. “We’ve had an R&D group working on that for four to five years. We’ve developed our own thing from scratch.”
As an open source project, Hazelcast has been used more than 70 million times, according to the “phone home” data that Hazelcast collects on its own source product. Hazelcast currently has about 200 paying customers for it proprietary offering, which adds enterprise features to the core IMDG. 
With names like JPMorgan Chase, Charter Communications, and Ellie Mae, these paying customers tend to be the largest enterprises in the world, Herrell says. “We’re solving hard valuable problems for large companies,” he says. “That’s really what our focus is. We clearly lead at the high end of the market.”
The company is accepting help from key business partners, such as Intel and IBM. Hazelcast was one of the first companies to support Intel’s Optane memory-class storage technology, and IBM sells Hazelcast as part of its solution for edge computing. The combination of IMDG and Jet only occupies a 10MB to 12MB footprint, so it can be deployed on small edge devices, such as a Raspberry Pi.
Stream processing on the edge is an emerging use case for Hazelcast, and the company is hoping to ride the wave of technological innovation and experimentation that’s expected as 5G rolls out and becomes more ubiquitous. However, because 5G only lowers latency between the device and the tower–and not the long backhaul from the tower to the Internet—there will be ample opportunities to build intelligence into devices installed in the field.
“Taking advantage of the data in the very moment in which it’s generated–that’s a brand new strategic advantage that’s to be had for the fastest movers,” Herrell says. “Time is money.”
Last week, the company announced a new release of its IMDG. Support for SQL has been added with the beta of version 4.1, giving customers the ability to query the data grid using a language they’re familiar with.![]()
“SQL is one of our most requested features that we’ve had for a long time,” Brimley says. “We are being trusted by more and more companies to store more and more of their critical data in their systems, so let’s give them SQL to query that data. It’s very important.”
Hazelcast currently is developing a “SQL-like” language that will work with Jet. This language, when it’s ready, will give customers another way to configure the three critical aspects of a stream processing job: specifying the source of the data to be processed, specifying the actual job to be performed, and specifying where to put the results.
“We’re hoping that will really broaden the number of people that can work with stream processing engines,” Brimley says.
Related Items:
Data Grid Embraces Emerging ‘Go’ Language
Leading Solution Providers

















