


October 12, 2020
Running Sideline to Sideline with Big Data

(jesadaphorn/shutterstock)
What can you do with big data? A better question might be what can’t you do. From a big data point of view, we are living in extremely resource-rich times, with a huge assortment of tools, framework, and platforms to choose from. So what possibly could be holding you back?
Whether you’re talking about open source software, proprietary platforms, or on-demand Web services, there is no shortage of data processing opportunities today. From search engines and distributed MPP databases to stream processing and machine learning, we have an abundance of advanced data analysis capabilities available, practically at the touch of a button.
Despite the wealth of software and services, organizations today are struggling to piece it all together. One of the biggest culprits is the ever-growing amount of raw data and the need to move it into the systems and application where it can be processed.
Organizations today are increasingly reliant on data engineers to construct the data pipelines needed to move the data from where it’s created into the system where it can be processed. Commonly referred to as a extract, transform, and load (ETL)–or ELT when the data is transformed after it’s loaded, which is often the case in cloud data warehouses–this part of data analytics hasn’t changed much over the past 20 years. That’s the main reason why we may never stop doing ETL.
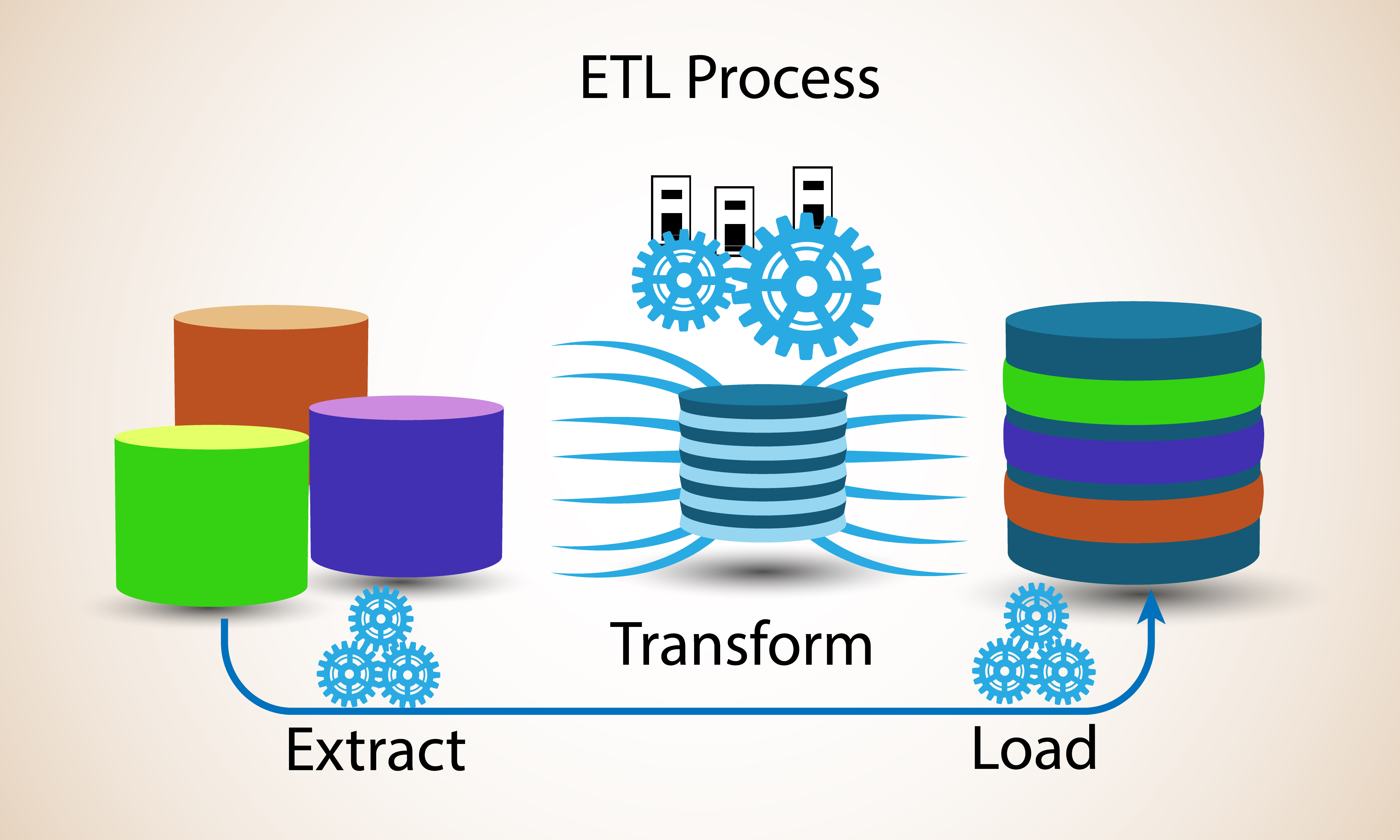
For many, ETL processes are the bane of big data
One way to attack the problem is to improve the ETL (or ELT) tools and make the experience better. We recently wrote how Fivetran is gaining traction with its offering, which aims to reduce the complexity involved in ETL and essentially make it stupidly simple. The company has built a collection of 150 connectors to all sorts of databases, frameworks, and SaaS applications. Just log in, select your source and destination, and let Fivetran do the dirty work of keeping the connection working when things change.
Then there is Data Build Tool, or dbt. Developed by the company Fishtown Analytics, dbt handles the “T” in ETL (it doesn’t do extraction or loading). It basically enables reusable data transformation workflows to be created using SQL. In the hands of an engineer, it lets them build more solid data connections with less work. In the hands of a data analyst, dbt can cut the oversubscribed data engineer out of the loop.
While these offerings may offer iterative improvement on ETL, they doesn’t address the root of the problem, which Zaloni CEO Susan Cook recently dubbed “the fragmentation of the data supply chain.”
In many companies, the data supply chain involves a variety of point tools, including ETL systems but also other tools, such as data catalogs, security tools, data prep tools, data warehouses, and BI tools. According to Cook, getting all these systems to play well together is too hard, and that creates cracks in the data supply chain.

(Semisatch/Shutterstock)
“I think there’s an awakening that we have got to be able to look at the entirety of the data supply chain, and not in pieces,” Cook says. “[Customers] don’t want to do all these integrations.”
According to Ravi Mayuram, the CTO and senior vice president of products and engineering at Couchbase, the proliferation of data connectors is increasing complexity while slowing progress.
“You’re doing this connector to that connector, and that connector’s compatibility changed, or this API changed, or that protocol changed,” he says. “The complexity increases while the solution velocity decreases.”
A side effect of the big data boom is the proliferation of “data sprawl,” where customers continuously download their data and load it into a new system. Managing that data sprawl keeps engineers busy with ETL scripts, data connectors, and adapters. But there’s a difference between “busy work” and getting ahead in this world.
The steps leading to data sprawl may sound familiar. “You start with the operational database, and then you want to do some search, so move this data to a search system. Oh there’s a connector for this,” Mayuram says. “Then it doesn’t scale enough, so let me put a cache. Now you have to again copy the data. Then let’s say you want to do analytics, so you want to query the data for something, let’s start the querying, and now you have to move the data again.
“So every time you do any of this stuff, the data starts in one place, and it is sort of copied, and there’s a connector. That is the world we have lived in now,” he continues. “In the name of agility, there is a lot of sideline to sideline running, as opposed to forward progress.”
One potential solution to this dilemma, Mayuram says, is consolidating operations in the database. Couchbase Server is a NoSQL database that has its roots as a fast key-value store. But over the years it has been bolstered with additional capabilities, including a SQL-like query language (N1QL), an index for a search engine, and MPP capabilities for distributed analytics—all atop its core JSON data management capabilities.

Data growth is accelerating (spainter_vfx/Shutterstock)
Mayuram–who will discuss this topic in his keynote address on Wednesday morning during the Couchbase Connect conference–isn’t saying that Couchbase is suitable for all data requirements, or that data silos won’t continue to proliferate in the cloud and on-prem. But as organizations look to the future and the huge data volumes they will be facing, he is saying that organizations should strongly consider consolidating the number of data management systems they are using.
“There’s going to be a proliferation of this data. That is bound to happen,” he says. “And some silos are bound to be created out of this. But if you want to manage that thing…you have to consolidate some of this stuff. Otherwise it is going to be unmanageable.”
Where is the right places to converge? There will be debate on that, of course, but Mayuram clearly believes that the multi-modal database approach makes sense. Just as today’s smart phones have displaced other classes of consumer electronics, Mayuram is betting that database management systems will be the best place to eliminate duplication of effort, thereby boosting productivity and improving data quality to boot.
“Every time you copy the data, you lose consistency,” he says. “There will come a time when you want to move the data for other discrete purposes, which makes sense, in which case you can move it to different storage or your data lake. That’s a valid scenario. But right now, the proliferation occurs simply because you don’t have a choice where you can do this stuff in one place.”
In the ebb and flow of big data, there are times when data tends to glom together and become centralized and times when it tends to spread apart and become decentralized. Despite the rapid growth of cloud repositories in recent years, the decentralization force has been quite strong, thanks to a flowering of new services. Unfortunately, cracks are starting to appear in the ETL and data supply chains that organizations must build and maintain in order to keep data fresh as it flows into disparate silos.
Whether it’s improving the state of DataOps, as Zaloni is doing; making ETL less painful, as Fivetran is doing; or enabling hybrid transactional-analytic (HTAP) data management, as Couchbase is doing, you can expect to see more efforts to rationalize and streamline big data management in the future.
Related Items:
Fivetran Launches Pay-As-You-Go Option for ETL
Applications:
Enterprise Analytics
Tags:
big data, data management, data sprawl, data supply chain, dataops, ETL, HTAP, Ravi Mayuram, Susan Cook
Leading Solution Providers

















