


November 12, 2020
Data Lake or Warehouse? Databricks Offers a Third Way

(Sergey Nivens/Shutterstock)
In the ongoing debate about where companies ought to store data they want to analyze – in a data warehouses or in data lake — Databricks today unveiled a third way. With SQL Analytics, Databricks is building upon its Delta Lake architecture in an attempt to fuse the performance and concurrency of data warehouses with the affordability of data lakes.
The big data community currently is divided about the best way to store and analyze structured business data. Some, like Dremio co-founder Tomer Shiran, say the reasons for using data warehouses have shrunk thanks to advances in data virtualization and the ability to remotely query object stores in almost the same manner as a data warehouse. Others, like Fivetran CEO George Fraser, have gone on record saying data lakes are legacy tech thanks to the ability of modern cloud data warehouses to separate compute and storage.
Which side is right? If you ask the folks at Databricks, the answer lies somewhere in the middle of its lakehouse architecture, which combines elements of data lakes and data warehouses in a single cloud-based repository. Databricks brought its lakehouse architecture to market earlier this year, with its Delta Lake at the center. Now it says it’s completing the journey with the launch of SQL Analytics.
With SQL Analytics, customers can get the type of SQL query performance usually associated with data warehouses, but with the cost and scalability associated with data lakes, says Databricks Vice President of Marketing Joel Minnick.
“A lot of enterprise out there today have two architectures,” he says. “They’ve got their data warehouse and they’ve got their data lake, and they’re moving data between them every day, at quite high frequency. And the feedback we’re getting on this is, it’s very complicated, it’s slow, it’s expensive, and it’s not actually facilitating the collaboration and the convergence” that a lot of the companies desire.
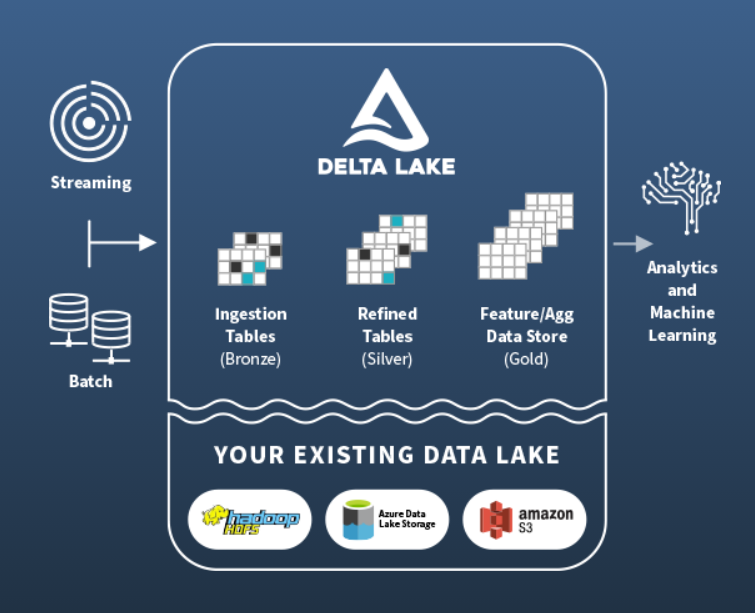
Delta Lake presents a data warehouse-like repository for working with data atop a cloud data lake (image courtesy Databricks)
“We agree, which is why we’ve been on this journey,” he continues. “There is a third way as customers have moved to the cloud. That is the lakehouse. We can bring data warehousing-like capabilities to a data lake.”
With its new SQL Analytics offering, Databricks is introducing new SQL Analytics Endpoints into its lakehouse cloud architecture. Based on the Delta Engine that it launched earlier this year, the new SQL Analytics Endpoints power SQL queries against the lakehouse with the type of high-concurrency and low-latency performance that enterprises demand of analytic databases. Delta Engine, which is based upon Spark SQL, also introduced other data warehouse requirements, like cost-based query optimizers, schema enforcement, ACID support, adaptive query execution, runtime filters.
Additionally, Databricks is also introducing a new SQL Analytics Workspace of its own for employees who are comfortable coding directly in SQL. The new SQL Analytics Workspace gives Databricks customers another option for how they want to experience the company’s cloud offering, Minnick says.
“For a long time, if you were going to use the GUI of Databricks, it was a data science user interface, working in notebooks, writing in Python and Rm,” he tells Datanami. “That is not an environment that data analysts work in. So there is a wholly new SQL-only workspace now inside of Databrick where you can do SQL natality, SQL ETL, in a language that you’re familiar with as a data analysts: ANSI SQL. [You can work with] tables and schemas just like you would with your traditional BI tool.”
Customers that have already purchased BI tools will be happy to know that Databricks is also launching a slew of connectors to enable use familiar BI tools with SQL Analytics, such as Tableau, Looker, and Microsoft Power BI, among others.
While Databricks is offering two ways to view and work with data that is stored in its lakehouse, there is still only one version of the truth. That’s an important element of this architecture, Minnick says.
“One of the key value propositions of this Lakehouse approach is that all your data teams now have one single source of the data, rather than pushing that data out into data lakes or multiple data warehouses where you end up standing up these silos where everybody’s got a bit of a different view.”
This approach builds on the idea that data lakes are inherently good for storing and processing certain types of data, such as streaming data and unstructured data, which column-oriented MPP data bases (i.e. data warehouses) historically have struggled with. This also happens to be the data that data scientists want to use to build machine learning models that can help automate decision-making for business, which is not a role that data warehouse have traditionally been good at (although data warehouse companies like Snowflake are moving in that direction).

Databricks’ new SQL Analytics Workspace provides place for analysts to develop and view queries
Bringing these two worlds together – traditional SQL-based BI workloads for highly structured data and emerging machine learning workloads for less-structured data – is the key to solving the dilemma, according to Minnick.
“If we can bring the transactional nature of data warehouses to a data lake and get the reliability and quality that you need on top of your data to do traditional analytics, then we really end up with a new architecture that’s best of breed for both traditional analytics workloads as well as machine learning and data science workloads, where companies are trying to go now.”
This can also be viewed as a shot across the bow of Snowflake, which raised $3.4 billion in a highly publicized IPO in September. Executives at Databricks have talked about the possibility of an IPO for years, and if rumors are correct, then it appears likely to happen in early 2021.
Like Snowflake, Databricks is building a cloud-based platform that businesses can use to analyze their data. But the two companies are tackling the challenge from opposite sides of the spectrum, with Snowflake’s strength being high-scale SQL analytic workloads and Databricks’ strength being its tools for data scientists and, to a lesser extend, data engineers. The two companies increasingly are moving into each other’s territories, which makes for interesting watching.
From a practical perspective, SQL Analytics also brings a new product that Databricks can bill customers for. Previously, SQL queries were billed as general compute in the Apache Spark-based cloud environment that Databricks runs on public clouds. But now, the company will charge SQL Analytics at a rate of $.15 per DBU (Databricks Unit).
Minnick says that price will be steal compared to typical cloud data warehouse pricing due to the 9x performance advantage that SQL Analytics holds over the average cloud data warehouse. The 9x figure comes from preliminary benchmarks that the company is running at the Barcelona Supercomputer Center, Minnick says. The final benchmark results are expected soon.
The launch of SQL Analytics also marks a milestone for Delta Engine, which the company launched in a private preview earlier this year. The new SQL analytics endpoints route queries through Delta Engine, which is now officially in a public preview.
Delta Engine, by the way, is a C++ rewrite of Apache Spark. The company rewrote it to get better performance than can be gotten out of a JVM, Minnick says. Apache Spark isn’t going away, however, and the core component of that C++ rewrite, a project called Photon, won’t be available as open source anytime soon.
“Photon remains a Databricks-specific enhancement,” Minnick says. In other words, if you want this kind of performance, you will need to sign up for Databricks’ cloud offering.
SQL Analytics becomes available in public preview on November 18. It will be available on AWS and Microsoft Azure.
Related Items:
Data Lakes Are Legacy Tech, Fivetran CEO Says
Did Dremio Just Make Data Warehouses Obsolete?
Databricks Cranks Delta Lake Performance, Nabs Redash for SQL Viz
Sectors:
Retail
Leading Solution Providers

















