


December 7, 2020
AWS Bolsters Its Lakehouse

Amazon Web Services wants you to create data silos to ensure you get the best performance when processing data. AWS also wants to help unify your data to ensure that insights don’t fall between the cracks. If you think these two belief systems are mutually exclusive, then perhaps you should learn more about AWS’s data lakehouse strategy.
It’s hard to pinpoint exactly when AWS began adopting the data lakehouse design paradigm, in which characteristics of a data warehouse are implemented atop a data lake (hence the merger of a “lake” with a “house”). Google Cloud and Databricks have been early practitioners of data lakehouses, which are designed to provide a force for centralization and to reduce the data integration challenges that crop up when one allows data silos to proliferate widely.
The company started talking about its lakehouse architecture about a year ago. One of the key elements of that lakehouse strategy is Amazon Athena, which is AWS’s version of the Presto SQL query engine. Athena Federated Query enables users to execute queries that touch on a wide range of data sources, including data sitting in S3 as well as relational and non-relational databases in AWS.
In late 2019, at its annual re:Invent conference, AWS launched Redshift Spectrum, a new service that enabled users to run Redshift queries directly on data residing in S3, thereby eliminating the need to move the data into the Redshift database and to store it in the optimized Redshift format. With Spectrum, users can leave the data in Parquet, the efficient column-oriented data format that was popularized in Hadoop (Avro, ORC, and JSON can also be used).
It also announced federated queries in Redshift, enabling users to point their Redshift SQL queries at data residing in other repositories, including PostgreSQL. Finally, it announced the capability to output the results of Redshift queries directly into S3 using Parquet. That enabled other AWS services, such as Amazon Athena, to get access to the data.
The lakehouse could help boost AWS’s fortunes as companies ramp up the migration of big data systems to the cloud. The $46-billion company is already a giant in the burgeoning market for cloud databases, and scored very highly in Gartner’s first-ever Magic Quadrant for Cloud Database Management Systems, which we told you about last week. AWS is number one in the customer-count and revenue departments, and it has a better service record than other hyperscalers, even if Oracle, Google, and IBM outscored AWS on the completeness of vision axis.
However, if there was one ding against AWS, in Gartner’s eyes, it was that the company offers a multitude of databases as part of its focus on “best-fit engineering.” While this ensures the highest level of performance, it puts an integration burden on customers, Gartner says.
Best of Breed DBs
Rahul Pathak, vice president of AWS Analytics, makes no bones about AWS’s best-of-breed approach.

Amazon advocates a best-of-breed approach to databases (Joe Techapanupreeda/Shutterstock)
“Anyone that says one tool is the answer to all of your problem is probably incorrect,” Pathak tells Datanami. “Things that are best-of-breed for a particular purpose allow customers to get away from having to compromise on performance or functionality or scale for that use case.”
S3 is the common object store that backstops data in AWS, but the company offers more than 15 databases for specific applications. AWS offers relational databases (Aurora, RDS), an MPP database (Redshift), a key-value store (DynamoDB), a document database (DocumentDB), in-memory databases (ElastiCaches for Memchached and Redis), a graph databases (Neptune), a time series database (Timestream), a wide column store (Keyspaces), and a ledger database (QLDB). All of these databases are discussed in AWS’s recent e-book “Enter the Purpose Built Database Era.”
As Pathak sees it, those databases–not to mention the hundreds of other managed databases that third-parties offer on the AWS Marketplace–aren’t going away any time soon.
“Our view is customers will have these architectures with data in different places,” he says. “Yes, they will bring data from purpose-built services into a data lake to do things like cross-service analytics or machine learning. But equally, they will still keep using things like data warehouses or log analytics services, because they’re great at their particular workloads, whether it’s real time telemetry and operational systems or complex queries on structured data to power platforms.”
For example, if an AWS customer is trying to a real-time dashboard of high scores in an online game, that probably would not work very well using S3 as the data store. Instead, something like ElastiCaches for Redis would probably be a better choice, Pathak says. “The challenge if you try and to put everything in one place is you’re inevitably going to run into a use case that doesn’t fit what the thing that you’re trying to do,” he says.
There will always be data integration challenges when you increase the number of places where the data is stored. But by incorporating the databases into the lakehouse architecture, AWS can start to mitigate some of the integration challenges that arise from having so many disparate silos of data.
“What we’re seeing customers do is adopting what we’re calling a lakehouse architecture that goes beyond the data lake and the data warehouse,” Pathak says. “It’s really about integrating data across the data lake, data warehouses, and any purpose-built data services that you might use.”
Glue Elastic Views
The company bolstered its lakehouse strategy last week with the release of Glue Elastic Views, which AWS CEO Andy Jassy unveiled last week in the first week of a three-week virtual re:Invent conference.
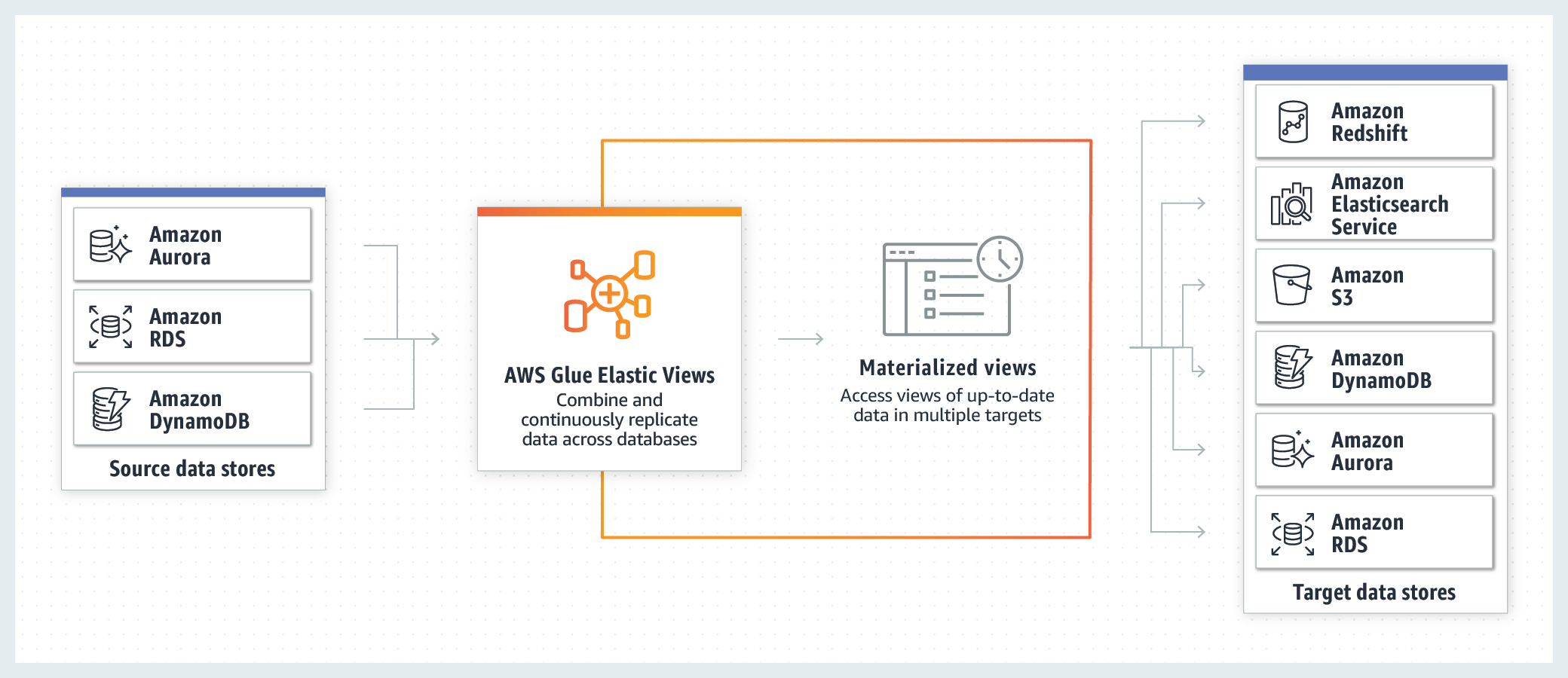
Glue Elastic Views can replace ETL/ELT scripts for data integration in AWS (Image courtesy AWS)
Glue Elastic Views automate the flow of data from one AWS location to another, thereby helping to eliminate the need for data engineers to write complex ETL or ELT scripts to facilitate data movement in the AWS cloud. And by utilizing change data capture (CDC) technology, customers can be assured that they’re getting the latest changes to the source databases.
“What Elastic Views makes it easy to do is to allow data to flow between these systems,” Pathak says. “So a developer can just create a view using SQL, which is familiar [to them]. You can pull data out of databases, like DynamoDB or Aurora, and then you can pick a target like Redshift or S3 or Elastic Search Service, and all changes will propagate through. We scale up and down automatically. We also monitor that flow of data for any change, so we take all the error handling and monitoring off the customers’ hands. It really simplifies that data movement across services.
The preview of Glue Elastic Views will support Dynamo and Aurora as sources, and Redshift and Elasticsearch as targets. The goal is for AWS to add more supported sources and destinations over time. It’s also welcoming customers and partners to use the Elastic Views API to add support for their databases and data stores, too.
While Pathak didn’t want to get into specifics of the roadmap, he allowed that streaming data services, such as AWS Kinesis or Kafka could also play roles in Elastic Views. “From our perspective, absolutely,” he says. “Streaming data is part of our customers’ data universe, and we want Elastic Views to support whatever customers end up using. That’s a big reason to keep the individual APIs for data sources and data target open and accessible, so whichever way customers want to expand them, we can support that.”
Glue Elastic Views builds on Athena’s federated query capability by making it easier for users to get access to the most up-to-date data while also enabling them to query data wherever it might reside–all using good old SQL.
“Federated query give you this ad-hoc view. So I want to see what I’ve got in multiple places. I can write a query, I can get a result right now. Then think of Elastic Views as being able to materialize that result on a continuous basis, and anywhere else,” Pathak says. “Part of thinking about data movement is not just getting data from A to B, but it’s also being able to query data wherever it might live and get a result back in one place.”
AWS re:Invent 2020 continues December 8 with an 8 a.m. PT keynote on machine learning by Swami Sivasubramanian, AWS VP of AI.
Related Items:
AWS Bolsters SageMaker with Data Prep, a Feature Store, and Pipelines
AWS Unveils Batch of Analytics, Database Tools
Re:Invent Begins, So What Will AWS Unveil?
Leading Solution Providers

















