


December 7, 2020
Nvidia Trains GANs With Fewer Images
Nvidia researchers report a new AI model that significantly reduces the amount of data required to train a machine learning framework called generative adversarial networks.
In a paper released during this week’s Neural Information Processing Systems meeting, the researchers said their GAN framework achieved the same level accuracy with an “order-of-magnitude” reduction in training data. The advance could be applied to medical and other applications where labeled training data is rare.
The technique, called adaptive discriminator augmentation, or ADA, is a training protocol that uses a fraction of the roughly 100,000 images usually required to train GANs. The image augmentation approach supplements available images by applying perturbations or distortions to training data to create new sets of images. Those distortions are similar to tools available with Photoshop, said David Luebke, Nvidia’s vice president of graphics research.
The results mean GANs could now be used “to tackle problems where vast quantities of data are too time-consuming or difficult to obtain,” Luebke added.
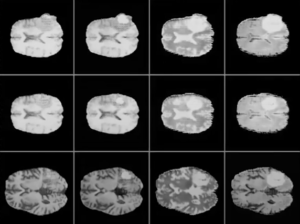
While the Internet is rife with images of cats and dogs, Nvidia’s augmentation approach was applied to rare artwork as well as even rarer medical images, including cancer histology images. The model generated by a GAN could in turn be used to train diagnosticians, Nvidia said.
Adaptive Discriminator Augmentation applied to medical imagery. (Source: Nvidia)
Industry experts note that scanning medical imagery is among the most promising applications for AI models, accounting for anomalies such as “confirmation bias.”
GANs consist of a pair of cooperating networks: one generates synthetic images while the other, a “discriminator,” uses training data to learn what realistic images should look like. The more training data, the better the model.
Among the problems tackled by the Nvidia researchers was the tendency of the discriminator to “overfit” when short on training data. Overfitting causes training in neural networks to diverge.
While the augmentation technique greatly reduces the amount of imagery needed to generate a model, Luebke acknowledged the framework does not reduce training time. It still takes “days” to train a high-quality, high-resolution GAN, he added. The longer the training time, the greater the odds the model will deteriorate.
Nvidia’s approach recognizes the paucity of training data for medical applications. As a substitute, researchers used images of rare art to demonstrate their augmentation approach (see video). In generating high quality models using a limited number of images, “We need to apply augmentation adaptively” in training GANs, Luebke noted during a briefing.
GANs iteratively refine rule-specified training functions so that, upon repeated runs, they automatically generate training data at least as accurate as what manual labeling might have produced.
Applied to GANs, ADA augments training data with random distortions so the network never sees the same image twice. Those perturbations include flipping or rotating an image or adjusting color. Applying those distortions adaptively, GANs learn not to synthesize distortions into an image. Instead, it uses the distortions to synthesize the original image.
“This let’s us reduce the number of training images by a factor of ten [even] a factor of 20 or more while still getting great results,” Luebke claimed.
Nvidia researchers noted in their NeurIPS paper that their training framework also “contributes to the deep technical question of how much data is enough for generative models to succeed in picking up the necessary commonalities and relationships in the data.”
The Github repository link for StyleGAN2-ADA is here.
Recent items:
Three Deadly Sins of Data Science
Training Your AI With As Little Manually Labeled Data As Possible
Technologies:
Frameworks
Vendors:
NVIDIA
Leading Solution Providers

















