


December 8, 2020
Cloudera CEO: Enterprise Data Cloud Vision Nearly Complete

(jijomathaidesigners/Shutterstock)
The hard work may be paying off for Cloudera, the embattled former Hadoop distributor that’s been pivoting to an enterprise data cloud strategy for the past year-and-a-half. With the delivery of an on-prem version of its Cloudera Data Platform last quarter and support for Google Cloud expected in early 2021, the company is close to fulfilling its vision for an enterprise data cloud, CEO Rob Bearden said.
For the third quarter of fiscal 2021, Cloudera delivered total revenue of $218 million, a 10% increase from the third quarter of 2020. Subscription revenue was $197 million, which was up 18%. Its customer for CDP Public Cloud, which runs on AWS and Microsoft Azure, was up by 40%, signifying strong adoption. It recorded a net loss of $12.3 million, compared to an $82.5 million loss a year ago.
Cloudera is currently delivering annualized recurring revenue (ARR) at a $759 million rate, an 18% increase from the same point in fiscal 2020, the company says. That is impressive, especially considering the headwinds of a global viral pandemic, Bearden told analysts during a conference call last Friday.
“It’s especially encouraging that, even while we wait for the CDP product cycle to be reflected in the financials, growth in subscription revenues and ARR has been consistent for several quarters,” Bearden said.
Cloudera has been working to re-think how it develops and delivers software following the collapse of the Hadoop market in 2019, which led to the ouster of top executives at Cloudera and a fire sale of MapR to HPE. The public clouds, with inexpensive storage and scalable compute offerings, have been the primary beneficiaries of this big data market shift, and that dynamic has accelerated this year during COVID-19.

Cloudera CEO Rob Bearden
While old Hadoop is virtually dead, the Hadoop family of products (Spark, Hive, Impala, Flink, etc.) lives on. Cloudera has responded to the shift by emulating the public clouds, which means shifting away from core Hadoop components for storage and compute for its cloud offering. Instead of using HDFS and YARN as a file system and resource scheduler, it built its new CDP Public Cloud offerings on cloud object stores, using AWS S3 and ADLS for storage, and using Kubernetes to manage the compute.
This shift started when Cloudera and Hortonworks merged in early 2019, culminating with the launch of Cloudera Data Platform (CDP) in September 2019. The company has been working to iron out the kinks ever since, said Cloudera’s VP of Product Management, Fred Koopmans.
“When we came out with the public lunch at Strata Data 2019, it looked good. It wasn’t demo-ware by any stretch, but there were a lot of rough edges,” Koopmans said. “We’ve spent the last 13, 14 months one at a time sanding those down and smoothing them out and adding more and more services to it. I’ve particularly been impressed with how much stick-to-it-ivness we’ve been able to demonstrate.”
Focus on Enterprises
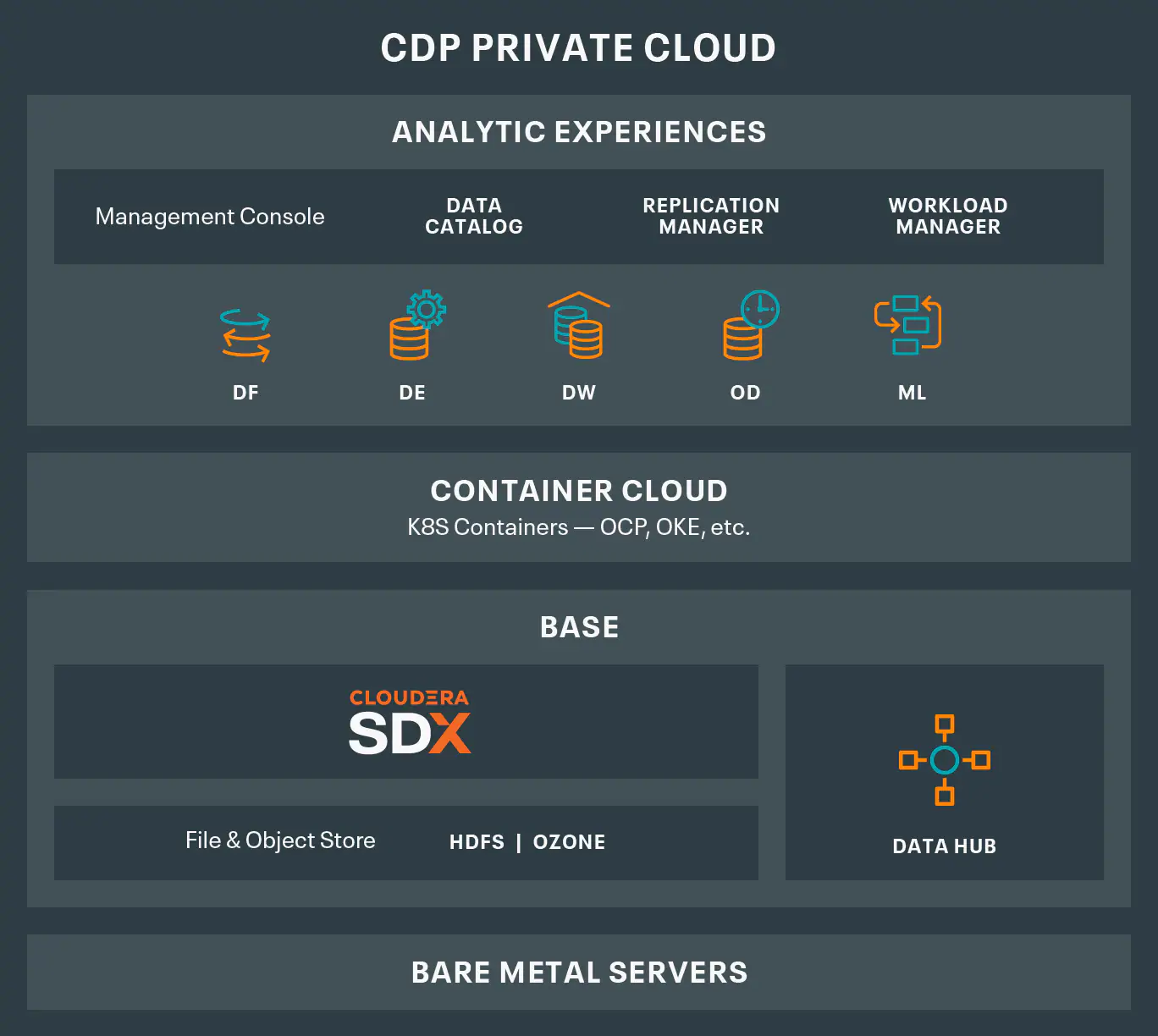
With the launch of CDP Private Cloud this summer, Cloudera now gives customers the ability to run this platform on their own servers or in a private cloud. Cloudera selected Red Hat Open Shift as its preferred Kubernetes distribution for CDP Private Cloud. For storage, HDFS is still present, but it’s been augmented with the launch of Apache Ozone, which is an object store extension for HDFS that provides an S3 API.
Ozone gives on-prem customers the storage headroom they need as they approach the limits of HDFS, Koopmans said.
“There’s untold number of exabytes of data written in HDFS and that will remain true for a while,” Koopmans told Datanami. “Having said that, HFDS has its limits and we’re pretty close to them in some of our accounts, if we’re not already there.”
Specifically, some of Cloudera’s largest enterprise customers are approaching HDFS limitations, such as files per name space, terabytes per node, and related cost-density limits, Koopmans said. “Think of it effectively as next generation of HDFS, but it also has an S3 API,” he said.
Currently, Cloudera only offers two application services atop its private cloud offerings, including data warehousing and machine learning. For its public cloud offering, it offers those two services, plus data engineering. But that will soon change, Koopmans said.
(Image courtesy Cloudera)
“We have a couple of services that are on the cusp of being launched,” he said. “The Cloudera Operational Database [i.e. HBase] is launching early next year. And the DataFlow experience is launching soon after that. That’ll come out in the public cloud, and later it will go to all the different public clouds, as well as on prem.”
Underlying CDP in both use cases—public cloud and on-prem/private cloud–is Cloudera’s Shared Data Experience. The SDX layer includes a range of integrated tools for managing data wherever it may reside, as well as tracking its governance, lineage, and providing security.
The SDX is a key component of Cloudera’s strategy, as it gives customers a way to manage their data as it sits on public clouds, on premise servers, and any combination thereof, Koopmans said.
“We’ve given a single interface for customer to be able to see, manage and monitor all of their infrastructure, be that on prem, private cloud capabilities, even including CDH and HDP,” he said. “It gives them a single pane of glass for their global footprint and helps them mange things like data sovereignty, not only from on prem to cloud, but from one country to another.”
While the public clouds are beginning to offer hybrid big data storage and computing solutions that span cloud and on-prem, they aren’t moving as quickly to provide multi-cloud capabilities, for obvious competitive reasons. That presents a golden opportunity for a third-party to step in and provide a big data solution that runs equally well, no matter where it resides.
This is particularly true for large enterprises that are looking for a single data lake environment that can host data used for a wide variety of use cases by many teams, Koopmans said. Customers may be able to get started quickly with the data services offered by the public clouds, but they lack the capability to take enterprises deep into their data journeys, he said.![]()
“The cloud native services, they’ve been built and tailored for single applications and single teams, for the most part. [The vast majority] of the applications running in cloud native tend to be single tenant,” Koopmans said. “You don’t need [multi-tenant] when you’re building your first cloud service, one application. But when you’re going to build a lot–when you’re going to go big into the cloud–you need all of these capabilities. And they just don’t exist in the native platform.”
Due to that lack of integration, AWS, Azure, and GCP excel for lower end, less-regulated uses, Koopmans said. “When you go to top 10 banks and telcos and insurance companies and healthcare agencies, a lot of those services are just kind of non-starters for the multi-tenant use cases,” he added. “Our strategy is to create a better integrated platform.”
Related Items:
Cloudera Prefers Red Hat for Kubernetes, But YARN Not Going Away
Cloudera Delivers Private Cloud Amid Public Speculation of Sale
Cloudera Begins New Cloud Era with CDP Launch
Leading Solution Providers

















