


April 15, 2021
Bigeye Spawns Automated Data Quality Monitoring from Uber Roots

Having high quality data is essential to having high quality analytics and accurate machine learning algorithms. But as data volumes grow, it becomes increasingly difficult to keep tabs on data quality using traditional rules-based approaches. That’s why a startup founded by former Uber engineers called Bigeye is relying on ML and statistics to automatically monitor data quality.
When he was in charge of Uber’s metadata team, Kyle Kirwan oversaw the development of a rules-based approach to testing the quality of the company’s data.
“Someone would come into that tool, define a set of rules about data, and then we’d run the rules on a schedule. And they’d get an alert if the rules are violated,” says Kirwan, who is Bigeye’s co-founder and CEO. “Think of unit tests or integration tests for software.”
The folks at Uber liked the data quality test harness, namely because it was a proactive response to what was previously a problem that people could only react to, Kirwan says. However, because the rules were written manually, it required a lot of human intervention to keep Uber’s massive data warehouse filled with fresh, clean data.
That difficulty gave rise to a new approach at Uber that added automation to the mix. By using anomaly detection techniques, Uber’s Data Quality Monitor (DQM) tool can automatically flag problems as they pop up in its multi-petabyte warehouse.
This is roughly the same approach that Kirwan and his Bigeye co-founder, Egor Gryaznov, have taken with Bigeye, which today announced a $17 million Series A round of funding led by Sequoia Partners. Gryaznov, who is Bigeye’s CTO, is one of several former Uber engineers at the San Francisco company. The lead developer of Uber’s DQM, Henry Li, is Bigeye’s senior data scientist.
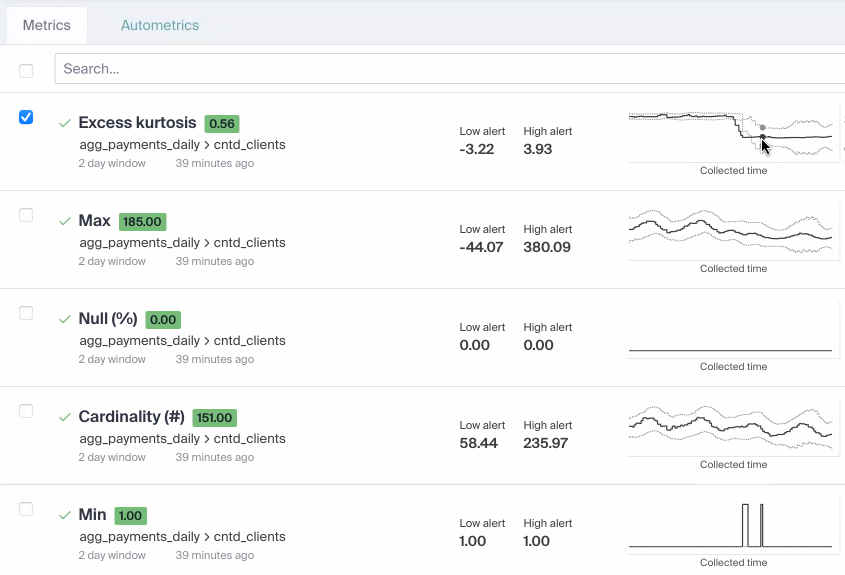
Bigeye’s software tracks data quality statistics against automated thresholds
Given the growth of today’s big data volumes, automation is absolutely critical to maintaining data quality, Kirwan says.
“Bigeye does support custom rule building, but a lot of it is based on…trying to detect those anomalies automatically,” he tells Datanami. “The folks we’re working with, the data engineering team, might be five or 10 people. A big customer might be 20 people. You’re talking about hundreds of tables that they’re responsible for, in some cases thousands–at Uber, tens of thousands of tables. So you just can’t monitor all that with manual rules. It’s just not possible.”
Bigeye’s software sits outside of the ETL or ELT data pipeline, unlike other approaches to data quality that are part of data pipelines. The software integrates directly with the cloud data warehouse (or a data lake via Presto), and uses SQL to gather statistics about each table that’s monitored. These statistics are then run through a machine learning system to flag anomalies.
“What we do is we collect a whole bunch of different statistics about each table, and then we track movements in those statistics,” Kirwan says. “So we would tell an engineering team for example, you used to have 0.1% null value in user IDs, and suddenly that’s 2 percent. That’s a huge jump, and somebody on the data engineering team probably needs to do something about that.”
Such a change could be serious enough that a company should completely shut down the pipeline and prevent the problem from polluting the data warehouse. Or it could be something that is not serious now, but that the data engineer wants to keep an eye on.
“That’s where human judgment comes in,” Kirwan says. “But the difference is that we can always collect statistics about the data and we don’t need a human to come and manually create a rule to do that.”
Rule-based approaches are still preferred in some situations. For example, a company may want to have a rule that says there can never be duplicate user IDs, and if a duplicate user ID is detected, then the pipeline should be shut down immediately, Kirwan says.![]()
“They probably will co-exist in the long term,” he says. “At Uber, we started out with the unit testing approach and then hit a wall. This unit test approach works for detecting certain types of issues, and then there’s a really long tail of other things that can go wrong with data and they’re hard to write unit tests for. We still want to know about all that stuff and it’s just not feasible to write unit tests for all of it, so that was where we came up with the anomaly detection system.”
Bigeye’s software is offered as a service running in AWS and Google Cloud. Alternatively, customers can deploy it in their own virtual private cloud (VPC) environment. The software can also be deployed on-prem. When a problem is detected, it can send an alert via email, Slack, PagerDuty, or Datadog (Bigeye has two Datadog executives on its advisory board).
Bigeye is designed to be a set-it-and-forget-it type of system. The heuristics, or “autometrics,” that Bigeye creates can automatically adjust to changing data, without the need for human engineers to go in and adjust them to the new data reality. The idea is for the software to run in the background, without user intervention.
“People come into the interrace to look at the charts to do a bunch root cause analysis and use the tool to diagnose what’s going wrong,” Kirwan says. “But as long as nothing is going wrong, we want them to stay out and focus on value added stuff.”
In a way, Bigeye is helping to bring modern DevOps techniques that software engineers have been using for years to the field of data engineering. These techniques are well-defined and have been used for years. Now it’s time for data engineers to use them, Kirwan says.
“A lot of it becomes this question about, hey in SRE, you use SLAs,” he says. “It turns out, you can also use those for data quality. This is how you do that.”
Related Items:
Room for Improvement in Data Quality, Report Says
Do You Have Customer Data You Can Trust?
How the Lack of Good Data Is Hampering the COVID-19 Response
Leading Solution Providers

















