


June 30, 2021
The Data Mesh Emerges In Pursuit of Data Harmony

(Oleksii Lishchyshyn/Shutterstock)
The data mesh is a new concept that’s emerging in big data circles. Similar in some respects to data fabrics, the data mesh provides a way to reconcile and hopefully overcome the challenges posed by previous data architectures, including first-gen data warehouses, second-gen data lakes, and even the current generation of Kappa systems. A data mesh architecture combines the best of these approaches in a decentralized fashion, while maintaining domain-awareness, self-service user access, a data-as-a-product viewpoint, and governance.
Zhamak Dehghani, who is the director of emerging technologies at Thoughtworks North America, is credited with defining and describing the data mesh concept. She laid out many of the principles and concepts of the data mesh in her first piece from May 2019, titled “How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh.” She followed that up with an equally detailed and informative piece in December 2020, titled “Data Mesh Principles and Logical Architecture.”
The data mesh is not just a technological concept for a future data architecture, but provides a path for how people can organize themselves to get the most out of data. There is a technical piece to the data mesh idea, of course. It seeks to reconcile the natural tension between highly centralized and heavily controlled data systems on the one hand, and the naturally distributed state of modern data and analytics on the other.
But what’s unique and interesting about Dehghani’s approach is how she weaves people and their data access patterns and proclivities into the equation. Simply moving to the “next” big thing in information technology (Kubernetes! Kafka! Kappa!) would be a failure to learn from past mistakes.
What Is a Data Mesh?
Dehghani presents the data mesh as a next-gen architecture for federated data analytics and data science.
Data lakes segregate users by domain (Image courtesy Zhamak Dehghani)
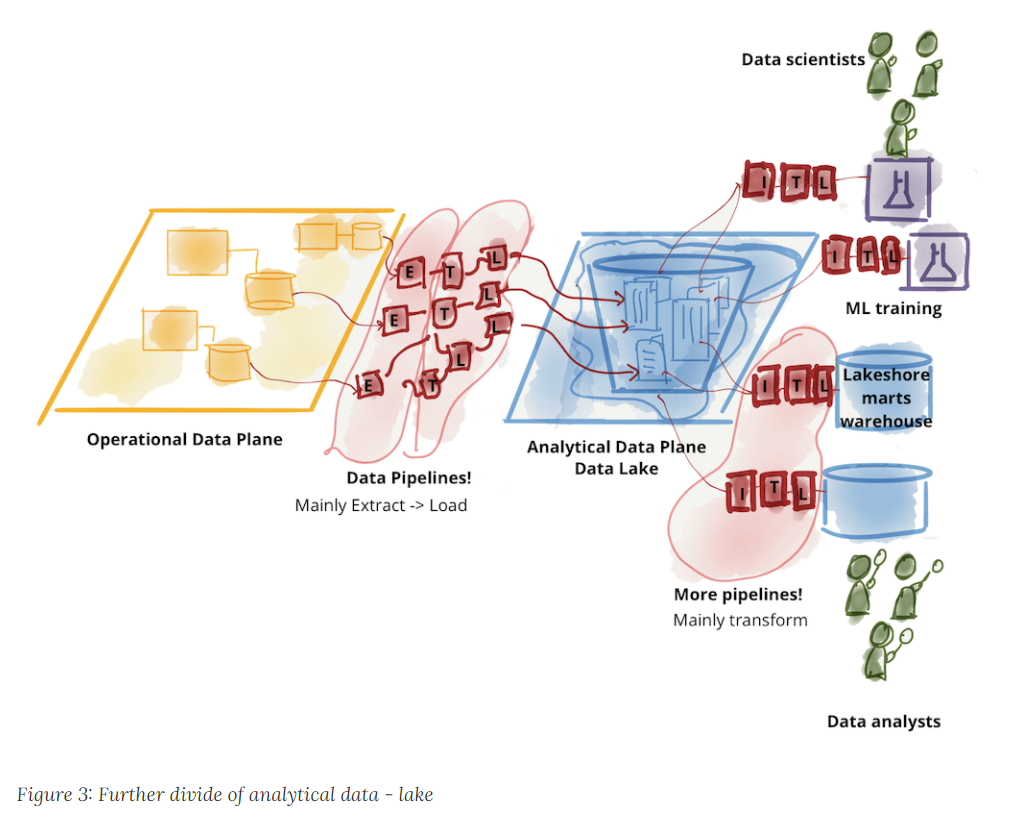
In overly simple terms, the proprietary, on-prem data warehouse is viewed as the epitome of heavy-handed control and governance. Through sheer force and will, companies piped data from operational system, hammering it on the way in through ETL, master data management, and other schema-on-write routines, until it filled the columns at the heart of most analytic databases.
The pushback from this centralized approach was real, and as a result, the data lake was built with opposite characteristics. Instead of interrogating and transforming the data first, all data was simply loaded into the data lake. The lake had a massive scalability advantage over data warehouses, which was partly due to the type of data it was holding, but also due to a relaxation of schema requirements.
While there are similarities, the use cases for data warehouses and data lakes ended up being quite different. As Dehghani points out, data warehouses were primarily used by analysts to answer business questions on structured data, while data lakes were used primarily by data scientists for building machine learning models based largely on unstructured data. This is an important consideration for understanding the domain aspects of data workers.
As time wore on, there ended up being quite a bit of overlap between the two approaches. Data scientists need data form the warehouse, and data analysts also found themselves interacting with the lake. Rectifying these different access paths while maintaining performance, governance, and self-service has proved to be a lot more difficult to achieve in practice, and as she points out in her follow-up piece, the divergence between operational data and analytical data has yet to be solved.
This need for cross-domain access to increasingly large and diverse data sets is the real problem that Dehahni’s data mesh concept sets out to address.
“As more data becomes ubiquitously available, the ability to consume it all and harmonize it in one place under the control of one platform diminishes,” she wrote in her first place. “The assumption that we need to ingest and store the data in one place to get value from diverse set of sources is going to constrain our ability to respond to proliferation of data source.”
The Everything Pipeline
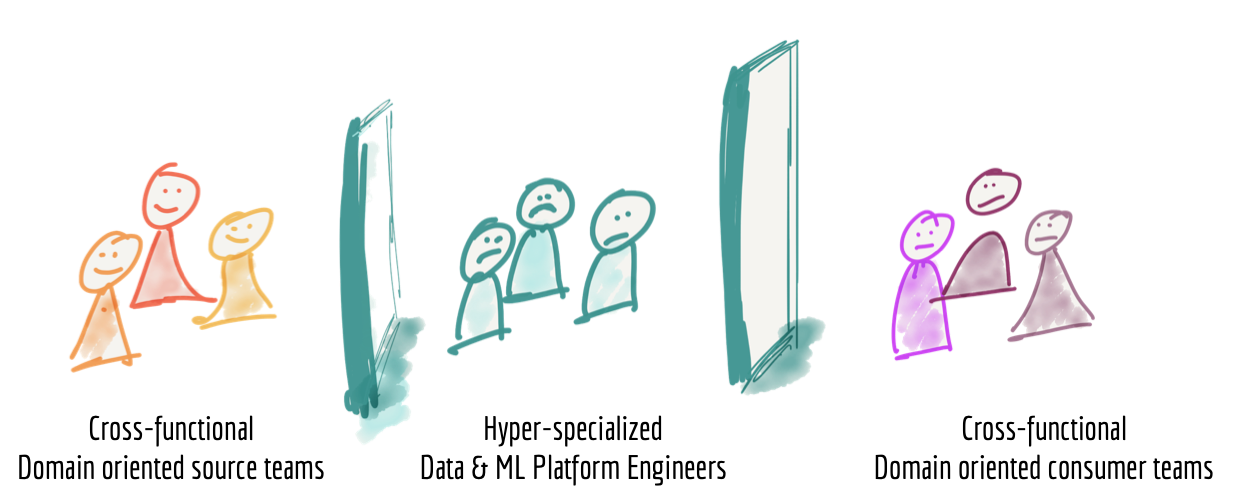
To address this distribution of data, companies have built data pipelines. In Dehghani’s view, companies have become overdependent on these pipelines to handle a wide range of tasks, from ingestion and preparation all the way to aggregation and serving.
Traditional data engineering approaches created disparate buckets and users (image courtesy Zhamak Dehghani)
“Continuously failing ETL….jobs and ever growing complexity of labyrinth of data pipelines, is a familiar sight to many who attempt to connect these two planes, flowing data from operational data plane to the analytical plane, and back to the operational plane,” she wrote in the second piece.
In addition to leaking data, the proliferation of pipelines is problematic because it constrains how the organization is built. By relying on data pipelines for so much, the architects are “decomposing orthogonally to the axis of change,” she wrote in the first piece. In other words, the abstraction level chosen by the pipe-laying architect works against the natural flow and evolution of data analytics and data science within the organization, while also giving rise to “hyper-specialized data engineers.”
The path forward, in Dehghani’s view, is a data mesh architecture that meshes (so to speak) three core concepts–distributed domain-driven architecture, a self-service platform design, and product thinking–with data. (In her second piece, Dehgahi added governance as a fourth principle.)
On distributed domain-driven architectures, Dehghahi wrote:
“In order to decentralize the monolithic data platform, we need to reverse how we think about data, it’s locality and ownership. Instead of flowing the data from domains into a centrally owned data lake or platform, domains need to host and serve their domain datasets in an easily consumable way” (from her first piece)
On self-service platform design, she wrote:
“The key to building the data infrastructure as a platform is (a) to not include any domain specific concepts or business logic, keeping it domain agnostic, and (b) make sure the platform hides all the underlying complexity and provides the data infrastructure components in a self-service manner” (from her first piece)

Thoughtworks’ Zhamak Dehghani first described the data mesh
On data-as-a product thinking, she wrote:
“Analytical data provided by the domains must be treated as a product, and the consumers of that data should be treated as customers – happy and delighted customers (from her second piece)
On federated governance, Dehgahni wrote:
“…[A] data mesh implementation requires a governance model that embraces decentralization and domain self-sovereignty, interoperability through global standardization, a dynamic topology and most importantly automated execution of decisions by the platform” (from her second piece).
There’s quite a bit more that goes into a data mesh implementation, and Dehghani covers it in detail in her two pieces. Needless to say, the data mesh concept appears at the very least to give us a fresh approach for framing thorny and long-standing issues around data access, management, and analysis, if not giving us a path to begin solving them.
Related Items:
Data Management Self Service is Key for Data Engineers–And Their Business
Why Event Meshes Should Be On Your IoT Radar
Leading Solution Providers

















