


September 1, 2021
Data Fabrics Emerge to Soothe Cloud Data Management Nightmares

(Olly-Kava/Shutterstock)
Companies are ramping up their advanced analytics and AI projects in the cloud, which is helping them to make data-driven decisions in increasingly competitive markets. However, the march to the cloud is also exposing weaknesses in companies’ data management strategies. That’s driving some companies to adopt data fabrics, which can help to patch over gaps in hybrid and multi-cloud deployments.
One of the analysts who’s been observing the trials and tribulations of data management over the years is Forrester’s Noel Yuhanna. As Yuhanna sees it, the rise of the cloud is exacerbating existing challenges that companies have with data management.
“I speak with three to four customers every day, mostly Fortune 1000 companies, and they’re [saying] ‘Hey, we’ve got all kinds of issues running with data management, not only just data movement and silos, but also data security and governance and integration and transformation and preparation and quality,” Yuhanna tells Datanami. “It’s a nightmare.”
Yuhanna was at the forefront of the data fabric concept when it first emerged in the mid-2000s, and now he’s watching as booming cloud adoption is supercharging the need for data fabrics in the 2020s.
“We’ve been talking about this [data fabric] for 15 years,” Yuhanna says. “Fifteen years ago, we used to talk about data fabric mostly on premises. But today, it’s to do with the cloud and multi-cloud and hybrid cloud in the edges. So fabric becomes even more important.”
Fabric in the Cloud
As Yuhanna stated back in a 2017, a data fabric is essentially an abstraction layer that links a disparate collection of data tools that address key pain points in big data projects. A data fabric solution should deliver capabilities in the areas of data access, discovery, transformation, integration, security, governance, lineage, and orchestration. It should also provide self-service capabilities, as well as some graph capabilities to identify connected data.

One depiction of a data fabric, courtesy of analytics vendor AtScale
By providing a way to bring these data management capabilities to bear on data spanning all these silos, a data fabric can help alleviate core data management challenges holding companies back from higher-level data use cases, including advanced analytics and AI in the cloud.
One vendor that’s finding traction with its data fabric solution is Ataccama. The company–which is named after the Chilean desert but has its world headquarters in Toronto and its R&D office in Prague, Czech Republic–has experienced a surge in demand for its solutions since COVID began driving customers to the cloud in larger numbers, says Marek Ovcacek, Ataccama’s vice president of platform strategy.
“What I’m seeing from our customers and in the market, right now is not just one cloud. They usually are moving to multiple clouds,” Ovcacek tells Datanami. “One team is working on the solution in say Azure and another team is working on solution in Google cloud, and so on.”
Without a way to link their data management processes across multiple clouds and on-prem activities, companies risk having their data projects run off the rails, he says. “It starts to be obvious that it’s a bit of a mess if you have these kinds of setups,” he says.
Sum of Fabric’s Parts
Ovcacek says customers are coming to Ataccama with vague ideas of what they need. They may start asking about the company’s data catalog, which leads into their needs for better data quality. At some point, the conversation turns explicitly in the direction of a data fabric, including what it is and what it can do for the customer.

Clouds have emerged as prime repositories for data fabric (Phonlamai Photo/Shutterstock)
In Ovcacek view, the key ingredient that turns a group of disparate data management tools into a data fabric is the elimination of the need to manually manage the data. This automation is largely driven by the underlying metadata, which links the various data management tasks.
“Ideally for me, when the data fabric is complete, that manual human interaction is not there anymore, or it’s kind of a hidden behind the scenes, and it’s seamless where I’m getting what I need,” he says. “You can have all the parts of the data fabric….Gartner calls them the six pillars of data fabric. You can have all of them in the organization. If you don’t use it the correct way, you don’t have a data fabric.”
Under the old system, when an employee needed access to data, they had to go to the organization and ask somebody to provide them with access to the data. This was a largely manual process, and it slowed things down, Ovcacek says.
“Now the process uses data fabric,” he says. “When you have a use case…there’s bunch of automatic processes that gives you the data, and gives you actually exactly what you need. I’m not saying there can’t be any manual checks. But it doesn’t have to be I’m calling somebody from another organization to give me access to the data. It needs to be built into the solution.”
A data fabric should also be composable, he says. That is, customers should be able to replace one aspect of the data fabric–say the data catalog–and replace it with another solution.
“I would like to have a standard for data fabric vendors,” Ovacek says. “I don’t think that going to ever happen.”
APIs, however, can help, he says.
Cloud Fabrics Growing
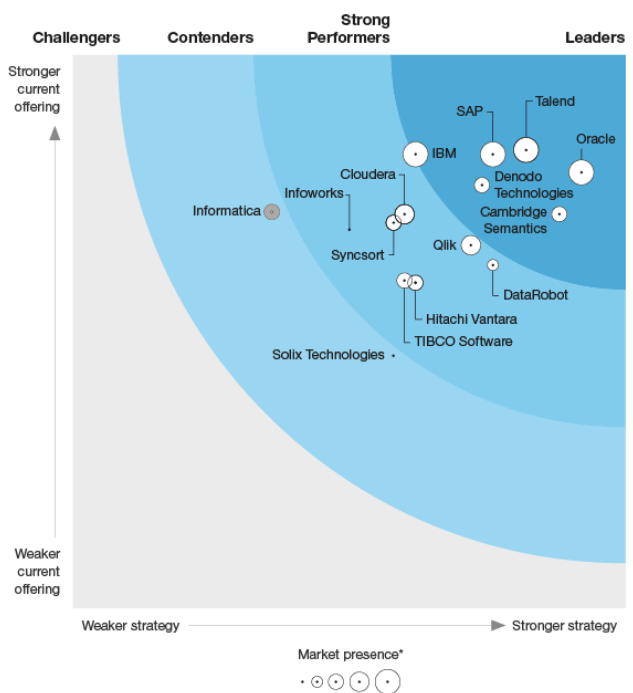
Yuhanna authored the Forrester Wave for Enterprise Data Fabrics, Q2 2020
The most pressing data management needs are occurring in the cloud, thanks to the flurry of innovation that’s happening there and the infrastructure savings that can be had there. Companies that are striving to be data-driven want to be able to give their data scientists and analysts quick and easy access to all sorts of data, while abiding by the necessary security, privacy, and governance restrictions. This is what data fabrics do.
In Yuhanna’s view, customers will run a data fabric instance in each cloud environment that a customer runs. So their AWS environment will have a data fabric instance, just like their Google Cloud and Microsoft Azure environments do. Companies can adopt data fabrics from third-party vendors that offer them, such as Talend, Informatica, Cambridge Semantics, Cloudera, Infoworks, and Ataccama, among others. They can also use data fabrics that the cloud providers are beginning to offer, such as Google Cloud’s DataPlex offering, which it launched in March.
“I think Microsoft is also starting to evolve into the fabric with their common data services, common data model they’ve been working on,” Yuhanna says. “But Google seems to be having a slight advantage here with the fabric. They’re not done yet. It’s still evolving on the platform.”
While each individual fabric will have its own proprietary processes and metadata, there will be some level of integration among them using APIs, as well as JSON data, Yuhanna says. “APIs and JSON are playing a big role in this level of standardization to some degree,” he says.
Forrester estimates that 20% of organizations have adopted multiple clouds today, and it expects that figure to double in the next three years. That raises real concerns, Yuhanna says–and also opportunities for data fabric solution providers.
“A lot of people are now starting to leverage fabric because data is spread across all these different clouds,” he says. “So yeah absolutely, fabric is playing a big role today in the industry across multi-cloud and hybrid cloud.”
Related Items:
Google Cloud Tackles Data Unification with New Offerings
Back to Basics: Big Data Management in the Hybrid, Multi-Cloud World
Cost Overruns and Misgovernance: Two Threats to Your Cloud Data Journey
Sectors:
Financial Services
Leading Solution Providers

















