


December 16, 2021
Databricks SQL Now GA, Bringing Traditional BI to the Lakehouse

Companies that want to run traditional enterprise BI workloads but don’t want to involve a traditional data warehouse may be interested in the new Databricks SQL service that became generally available yesterday.
The Databricks SQL service, which was first unveiled in November 2020, brings the ANSI SQL standard to bear on data that’s stored in data lakes. The offering allows customers to bring their favorite query, visualizations, and dashboards via established BI tools like Tableau, PowerBI, and Looker, and run them atop data stored in data lakes on Amazon Web Services and Microsoft Azure (the company’s support for Google Cloud, which only became available 10 months ago, trails the two larger clouds).
Databricks SQL is a key component in the company’s ambition to construct a data lakehouse architecture that blends the best of data lakes, which are based on object storage systems, and traditional warehouses, including MPP-style, column-oriented relational databases.
By storing the unstructured data that’s typically used for AI projects alongside the more structured and refined data that is traditionally queried with BI tools, Databricks hopes to centralize data management processes and simplify data governance and quality enrichment tasks that so often trip up big data endeavors.
“Historically, data teams had to resort to a bifurcated architecture to run traditional BI and analytics workloads, copying subsets of the data already stored in their data lake to a legacy data warehouse,” Databricks employees wrote in a blog post yesterday on the company’s website. “Unfortunately, this led to the lock-in, high costs and complex governance inherent in proprietary architectures.”
Spark SQL has been a popular open source query engine for BI workloads for many years, and it has certainly been used by Databricks in customer engagements. But Databricks SQL represents a path forward beyond Spark SQL’s roots into the world of industry standard ANSI SQL. Databricks aims to make the migration to the new query engine easy.
“We do this by switching out the default SQL dialect from Spark SQL to Standard SQL, augmenting it to add compatibility with existing data warehouses, and adding quality control for your SQL queries,” company employees wrote in a November 16 blog post announcing ANSI SQL as the default for the (then beta) Databricks SQL offering. “With the SQL standard, there are no surprises in behavior or unfamiliar syntax to look up and learn.”

Databricks is moving away from Spark SQL and embracing the ANSI SQL dialect (EvalCo/Shutterstock)
With the non-standard syntax out of the way, one of the only remaining BI dragons to slay was performance. While users have been running SQL queries on data stored in object storage and S3-compatible blob stores for some time, performance has always been an issue. For the most demanding ad-hoc workloads, the conventional wisdom says, the performance and storage optimizations built into traditional column-oriented MPP databases have always delivered better response times. Even backers of data lake analytics, such as Dremio, have conceded this fact.
With Databricks SQL, the San Francisco company is attempting to smash that conventional wisdom to smithereens. Databricks released a benchmark result last month that saw the Databricks SQL service delivering 2.7x faster performance than Snowflake, with a 12x advantage in price-performance on the 100TB TPD-DS test.
“This result proves beyond any doubt that this is possible and achievable by the lakehouse architecture,” the company crowed. “Databricks has been rapidly developing full blown data warehousing capabilities directly on data lakes, bringing the best of both worlds in one data architecture dubbed the data lakehouse.”
(Snowflake, by the way, did not take that TPC-DS benchmark lying down. In a November 12 blog post titled “Industry Benchmarks and Competing with Integrity,” the company says it has avoided “engaging in benchmarking wars and making competitive performance claims divorced from real-world experiences.” The company also ran its own TPC-DS 100TB benchmark atop AWS infrastructure and–surprise!–found that its system outperformed Databricks by a significant margin. However, the results were not audited. )
Databricks has built a full analytics experience around Databricks SQL. The service includes a Data Explorer that lets users dive into their data, including any changes to the data, which are tracked via Delta tables. It also features integration with ETL tools, such as those from Fivetran.
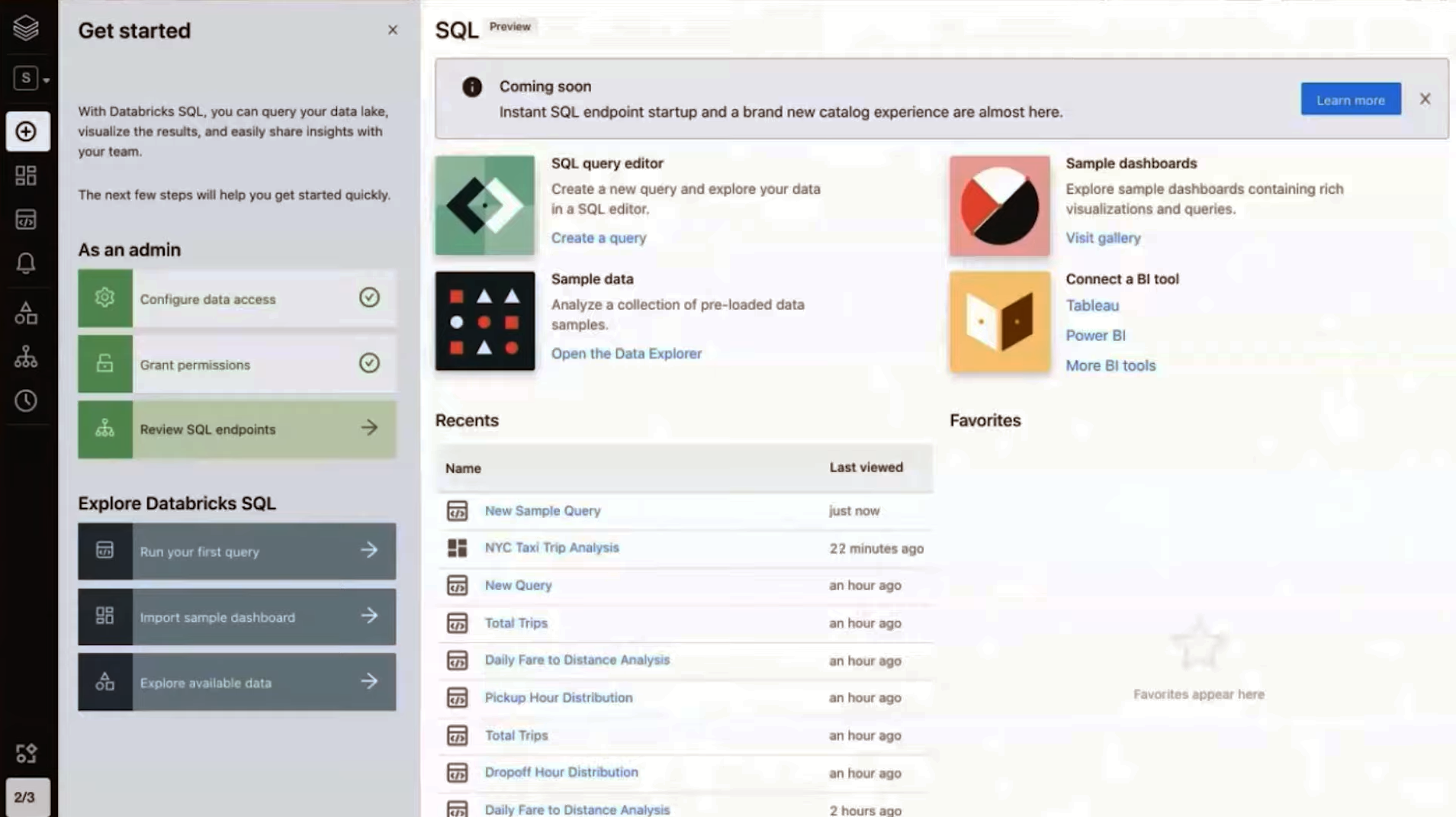
Users can interact with data directly through the Databricks SQL interface or use supported BI tools
Every Databricks SQL service features a SQL endpoint, which is where users can submit queries. Users are given “t-shirt” size instance choices; the workloads will also elastically scale (there is also a serverless option). Users can construct their SQL queries within the Databricks SQL interface, or work with one of Databricks’ BI partners, such as Tableau, Qlik, or TIBCO Spotfire, and have those BI tools send queries to the Databricks SQL endpoint. Users can create dashboards, visualizations, and even generate alerts based on data values specified in Databricks SQL.
While Databricks SQL has been in beta for a year, the company says it has more than 1,000 companies already using it. Among the current customers cited by Databricks are the Australian software company Atlassian, which is using Databricks SQL to deliver analytics to more than 190,000 external users; restaurant loyalty and engagement platform Punchh, which is sharing visualiations with its users via Tableau; and video game maker SEGA Europe, which migrated its traditional data warehouse to the Databricks Lakehouse.
Now that Databricks SQL is GA, the company says that “you can expect the highest level of stability, support, and enterprise-readiness from Databricks for mission-critical workloads.”
Related Items:
Databricks Unveils Data Sharing, ETL, and Governance Solutions
Will Databricks Build the First Enterprise AI Platform?
Databricks Now on Google Cloud
Leading Solution Providers

















