


January 31, 2022
In-Memory Tech at the Heart of Digital Integration Hub

(Dmitriy-Rybin/Shutterstock)
Customers today demand great online experiences, ones that are fast, personalized, and accurate. But delivering those experiences demands instant access to relevant data, which may be scattered about various systems of record. Increasingly, companies are extracting that critical data parking it data in a fast, in-memory layer called a digital integration hub.
The digital integration hub (DIH) is a relatively new data design pattern that’s starting to gain traction in certain industries impacted by digital transformation, including banking, financial services, and retail. First described by former Gartner analyst Massimo Pezzini in 2019, the DIH essentially is a fast data layer designed to serve the next-generation applications that companies are banking on to compete with digital natives.
The DIH is often implemented atop an in-memory database or in-memory data grid (IMDG), which gives it the speed and concurrency for demanding customer applications and websites, like customer 360 systems and even stock trading systems. These applications will often access data in the DIH via modern Web services methods, like REST, sometimes in conjunction with an API gateway.
A critical component of a DIH is the process of moving it from the systems of record–which could be mainframe-based ERP and CRM systems or even older applications running on the cloud–into the DIH data store. The most demanding use cases that need the freshest data will utilize real-time data integration methods, such as with event log-based change data capture (CDC) or real-time streaming systems like Apache Kafka or other message queues. Applications that don’t require such freshness can use traditional batch-based extract, transform, and load (ETL) tools.
IMDG vendors, such as Gigaspaces and GridGain, are seeing DIH moving the needle, as customers put the vendors’ in-memory technology at the heart of their new DIHs. But even industry giants, like Oracle, SAP, and IBM, are starting to see the value of DIH and promote it for digital transformation use cases.

A RAM layer provides fast data response times for a DIH (Gorodenkoff/Shutterstock)
According to Gigaspaces Director of Product Marketing Noam Herzenstein, the DIH concept is starting to take off.
“We see a lot of people starting to talk about DIH, either using the term or terms that are referring to the same thing,” he says. “Everybody is doing it now because digital transformation is so hot these days. It started maybe a decade ago, but it definitely accelerated during the pandemic.”
In the past, companies that faced the pressure to digitally transform would take it upon themselves to build their own DIH–a DIY DIH, if you will. Many companies successfully developed their own speedy DIH to act as a fast staging area for mainframe-resident data. But the appetite to take on those types of projects is waning, says Herzenstein.
“The pressure is on all of the traditional organizations to transform, and fast,” he tells Datanami. “If you talk to a bank, they don’t have 18 months to start and build a new architecture. They need to move fast. They have a backlog of digital services they want to see live, and they haven’t built it yet because it’s very, very complex.”
Gigaspaces hopes to short-circuit that complexity by delivering a pre-assembled DIH platform that gets companies most of the way there. By working with partners for the data integration and API gateway components if a DIH, Gigaspaces says customers can get up and running with a DIH in a fraction of the time compared to the DIY approach.
A small DIH may have less than 1TB of RAM in the in-memory layer, while the biggest DIHs will have dozens of TBs, Herzenstein says. Because the underlying Gigaspaces IMDG is distributed and scales linearly, there’s no physical limit on the size of the DIH. Instead, the size of the data grid is dictated by the particular data that’s being used, the requirements of the use case, and of course the cost of RAM.
GridGain, which competes with Gigaspaces in the IMDG area, is also embracing the DIH architecture to help its in-memory customers. In a 2020 Forbes article, GridGain founder and CTO Nikita Ivanov touted the benefits of DIHs.
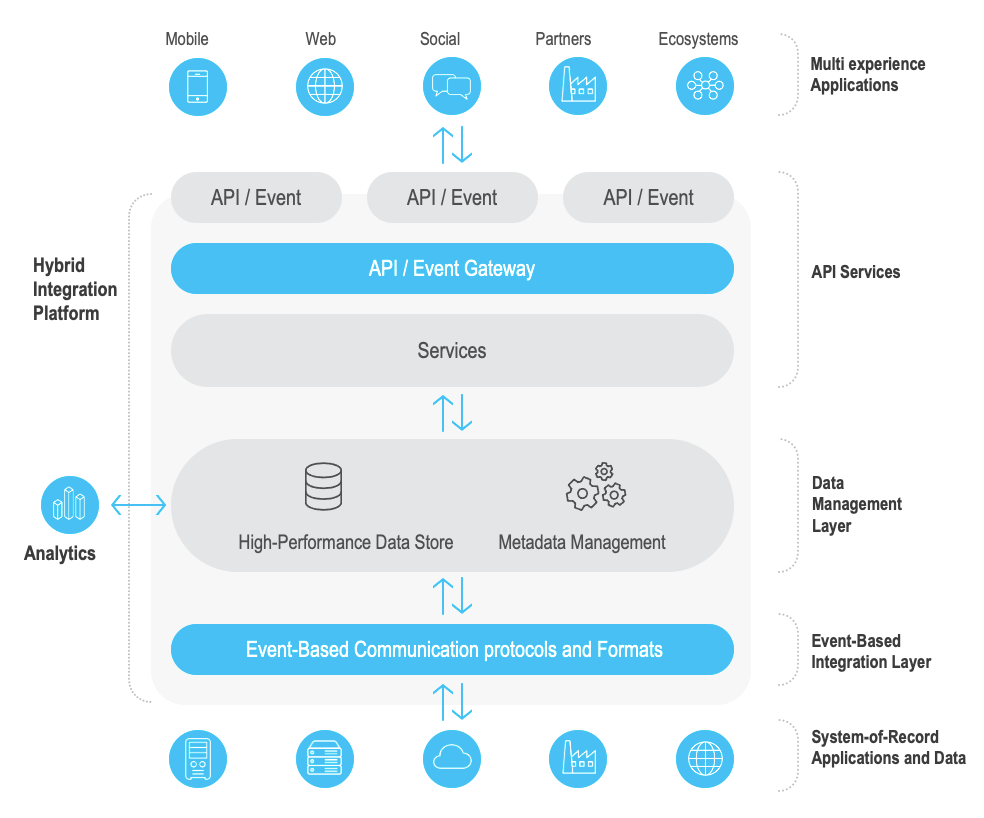
The DIH is compopsed of three layers, including an in-memory component, an ETL/CDC layer, and an API serving layer (Source: Gigaspaces)
“A DIH architecture creates a common data access layer that can aggregate data from multiple on-premise and cloud-based sources and enable multiple customer-facing business applications to access this aggregated data for real-time processing,” Ivanov wrote. “Utilizing a unified API, the in-memory data grid can cache data from many underlying data stores, including databases, SaaS applications and incoming data streams.”
One GridGain customer, 24 Hour Fitness, adopted a DIH to reduce the demands made on its core underlying business applications. According to Ivanov, data from the company’s SaaS billing system is cached in the DIH every 15 minutes, thereby enabling multiple downstream business applications to make simultaneous queries without touching the SaaS billing system.
“This ensures customers, employees and business analysts have fast access to the current information they need, from scheduled appointments to the status of membership fees,” Ivanov wrote. “Additional functions can be easily written for processing the data, and API calls to the SaaS system were dramatically reduced.”
One of Gigaspaces’ DIH customers is PSA Group, which recently merged with Fiat Chrysler Automobiles and is the second largest carmaker in Europe. PSA Group developed a website that allows customers to configure their vehicles. However, due to European regulations, the specific carbon emissions of each vehicle must be included in the data presented to the user.
The challenge for PDA was that the carbon emissions data was housed in the mainframe. However, the mainframe was maxed out and could only offer 200 queries per second for this application, when the demand was expected to hit 3,000 queries per second. The solution was to develop a DIH that would hit the mainframe the first time the emissions for a specific configuration was requested, but then cache it for each time thereafter, Herzenstein said.
There are many more mainframes and legacy applications living in the world, and they’re not going anywhere. The question, then, comes down to how do you extract the data from those systems, or integrate with their business logic, in the fastest and most affordable manner possible. For Gigaspaces, the DIH is the design pattern that meets those requirements.
“Obviously if you are a digital borne type of company, new fintech or insure techs, you don’t need [DIH],” he says. “You don’t have a lot of legacy systems of record. Your architecture is most likely already modern, because you are one of the new kids on the block. But the majority of organizations who are pre-dating this trend, like all the legacy banks, insurance companies, retailer, utilities, airlines…”
In other words, the DIH is designed for companies that have actual assets in the real world and don’t have the luxury of existing only in the digital realm. For these companies, the DIH has the potential to be the great equalizer.
Related Items:
The Past and Future of In-Memory Computing
NeuroBlade Tackles Memory, Bandwidth Bottlenecks with XRAM
In-Memory Database Goes ‘Translytical’
Applications:
Enterprise Analytics
Leading Solution Providers

















