


February 10, 2022
Cribl Seeks Control of Observability Data Run Amok

(Sur/Shutterstock)
If you’re struggling to keep a handle on the growing mounds of observability data in your shop, you’re not alone. Many companies today are straining to keep up with daily log data rates exceeding 10 to 100 terabytes or more, forcing them to increase their Splunk and Elastic allotments, or (gasp!) going without some data. Now a company called Cribl is giving customers another option to keep up with their observability data.
Former Gartner analyst Nick Heudecker, who joined Cribl last year as its senior director of market strategy, was shocked at the volume of observability data customers are dealing with these days.
“I had no idea how big data had gotten until I came here,” Heudecker says. “When I first started looking at big data, 10 terabytes a day was gigantic. No one could deal with that volume. And now 10 terabytes a day is incredibly addressable.”
In fact, many of the large companies that Heudecker works with in his new job are pushing hundreds of terabytes, even close to 1 petabyte per day, of observability data. “It’s mind boggling,” he says.
But managing data at those volumes requires one of two things: Careful planning, or an unlimited budget. If you have Bezos-level cash, you may want to stop reading and find something better to do. But for the rest of us, careful planning is the way, and Cribl has one answer.
Log Data on Steroids
At current data volumes, it’s not feasible to load raw observability data into the various AIops, application performance management (APM), and security information and event management (SIEM) environments that companies are using today. Many of these products, like Elasticsearch, Splunk, Grafana, Datadog, New Relic, and SumoLogic, charge by the volume of data.
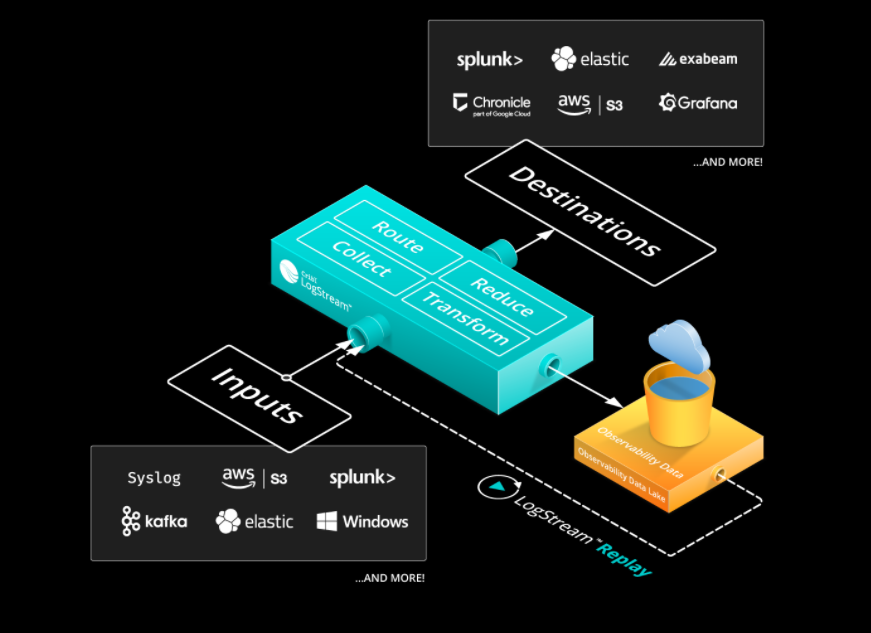
That’s where Cribl comes in. The company’s flagship product, called LogStream, works as a sort of filter for log data. The data pipelines created by Cribl can also redirect the data to where users want it to go.

Log data never stops (posteriori/Shutterstock)
Instead of pointing raw data straight from its source into the AIOps, APM, or SIEM tool for consumption, observability data is intercepted by LogStream, which transforms the data and optionally routes it to a cold store before sending it on its merry way.
The secret to Cribl’s success is understanding that much of the log data loaded into analytics tools isn’t wanted or needed, Heudecker says. Cribl simply provides an easy way to identify that data and strip it off the stream.
For example, a company may only want to analyze the data contained at the end of stream of log event, not at the beginning. “We let you drop that, and so instead of sending that onto your analytics platform and paying for it, you’re no longer paying for that,” Heudecker says.
Cribl can easily cull 20% to 30% of the volume from a log stream, he says. “As you really start to get more aggressive about what kind of reductions you’re making to your data, it’s very possible to see 50% to 60% reductions, depending obviously on the data type,” he adds.
Reducing data volumes directly cuts the cost for customers, since many of the analytics tools are priced based on daily data ingest rates. But it also gives them more flexibility to bring other data sets into the observability fold.
“Now instead of putting 5 TB a day in, I’m putting 2.5 TB a day in,” Heudecker says. “Now I can think about my DNS data. Now I can put my firewall data in. Now my analytics questions become much more interesting, because I’ve got more sources that I can actually ingest in these platforms, because we’re giving you that control over the data feeds going in in the first place.”
Data Enrichment
While it’s not to be confused with an ETL tool, LogStream does support some basic data transformations. That could be transforming raw log data into metrics, or even normalizing log files and doing some basic error correction. Machine data is typically free of fat-fingered mistakes, but a human will nevertheless leave a mark on it, Heudecker says.
“Some human has to program it,” he says. “So while syslog has been around as format forever, th
(Source: Cribl)
ere are many interpretations of the syslog standard, even when it comes to timestamping or what kind of fields are included.”
Cribl also gives customers the capability to route log data according to rules and the types of data it encounters. For example, it can keep a copy of all the raw log files on S3, but forward only the most interesting data to Splunk or Elastic for analysis.
“We allow you to route data to multiple destinations,” Heudecker says. “We let you filter data on the way in, so if you can remove things that you don’t need. We let you redact things like PII [personally identifiable information] over data in flight.”
Data enrichment is also supported in LogStream, which gives customers another way to get the most pertinent data in front of their administrators, operatrs, SREs, SecOps, and other technically included data consumers.
“So if you want to enrich data flowing into your SIEM with Geo IP information or whatever else, you can do that as data passes through,” Heudecker says. “The last thing is we let you replay that data. So we can put your raw data off to low cost object storage and then if you later on decide, hey I need all of that stuff or I need another subset of that data–you can run it back through LogStream, reprocess it, and deliver it to one or more different destinations.”
The decoupling of data provided by LogStream also helps customers complete upgrades of their analytic tools without losing data. It also lessens the vendor lock-in, especially for cloud analytic tools, since the customer has control over the data.
No Swiss Army Chainsaws
Heudecker acknowledges that open-source frameworks can also be used to get the type of data transformations that Cribl delivers. Apache Kafka comes to mind, as does Apache NiFi, two streaming data frameworks helping to drive digital transformation through real-time data.![]()
When Cribl completes a proof of concept with a company’s operations and security team, it’s not uncommon for the big data engineering team to chime in and say “We can do that with Kafka,” Heudecker says.
“And we’re like, okay, try,” he says. “It’s so much more work to do this with a Kafka, with a Ni-Fi. Those are Swiss Army chainsaws. You can do anything you want in them, but you have to do it. And that’s a huge barrier to entry for overworked infrastructure teams. And it’s just not realistic.”
The large companies that Cribl is working with simply want something that works, and that is supported by a commercial company, Heudecker says. They don’t want to have to build it and support it themselves.
Developing pipelines in LogStream isn’t difficult, Heudecker says. The company supports a Web-based interface that allows users to define their logic and data flows graphically. No YAML required.
The LogStream executable is a stateless processing engine developed in Node.js. It includes a master node that contains the logic, and worker nodes that execute the data transformations next to analytics engine.
Cribl offers two versions of LogStream, including a cloud version managed by Cribl and an enterprise version that customers can deploy on prem. The cloud producdt is free for the first 1 TB of raw data per day, while the enterprise version is free for the first 5 TB of raw data per day. Beyond that, the copay charges
Related Items:
Companies Drowning in Observability Data, Dynatrace Says
Who’s Winning In the $17B AIOps and Observability Market
Cribl Raises $200 Million in Series C Funding to Advance Data Observability
Applications:
Enterprise Analytics
Sectors:
Retail
Leading Solution Providers

















