


March 25, 2022
How Data-Centric AI Bolsters Deep Learning for the Small-Data Masses

(Valery Brozhinsky/Shutterstock)
It’s no coincidence that deep learning became popular in the AI community following the rise of big data, since neural networks require huge amounts of data to train. But organizations with much smaller data sets can benefit from pre-trained neural networks, especially if they follow the premise of data-centric AI, Andrew Ng said this week at the Nvidia GPU Technology Conference.
Ng, a prominent AI researcher and a Datanami 2022 Person to Watch, is at the forefront of the data-centric AI movement, which is aimed at helping millions of smaller organizations leverage the promise of AI.
“We know that in consumer software companies, you may have a billion users [in] a giant data set. But when you go to other industries, the sizes are often much smaller,” Ng said during his Nvidia GTC session, titled “The Data-centric AI Movement.” “From where I’m sitting, I think AI — machine learning, deep learning — has transformed the consumer software Internet. But in many other industries, I think it’s frankly not yet there.”
The lack of huge data sets is one impediment to leveraging the latest in machine learning technology, Ng said.

Andrew Ng is the founder and CEO of Landing AI and a 2022 Datanami Person to Watch
“I have previously built models using hundreds of millions of images, but the technology or algorithms and architecture we’ve built using hundreds of millions of images… doesn’t work that well when you’re only 50 images,” Ng said. “And for some of these applications, you’ve either got to make it work with 50 images, or else it’s just not going to work because that’s all the data that exists…”
The second big impediment to AI adoption is the “long-tail” problem, said Ng, whose long resume also includes being the founder and CEO of Landing AI, his latest startup. Many of the most valuable problems to solve have already been solved, such as ad targeting and product recommendation. But that leaves many more problems waiting for AI solutions to be built.
“Let’s call them $1 million to $5 million projects sitting around where each of them needs a customized AI system, because a neural network trained to inspect pills won’t work for inspecting semiconductor wafers. So each of these projects needs a custom AI system.”
Of course, there aren’t enough machine learning engineers in the world to take the same approach to building custom AI solutions at the far end of the long tail. The only way for the AI community to build this large number of custom systems is to build vertical platforms that aggregate the use cases, Ng said.
The good news is that a lot of the core AI work has already been done, and they’re available free of charge in the form of pre-trained neural networks.

Most AI problems suffer from a lack of data (Image courtesy Andrew Ng)
“Thanks to this paradigm of development, I find that for a lot of applications, the code of that neural network architecture you want to use is basically a solved problem,” Ng said. “Not for all, but for many applications. You can download something off GitHub that works just fine.”
But the pre-trained neural networks don’t work well out of the box for each specific use case. Each one needs to be tuned to address the specific requirements set by the organization adopting AI. The key to developing those vertical AI platforms, he said, is having the right set of tools — and above all, having the right data.
Instead of spending a lot of time tuning the neural network and tweaking hyperparameters to get good results, Ng encouraged viewers to spend more time tuning the data.
“The manufacturer-labeled data expresses the domain knowledge about what is a good pill, what is a good sheet of steel, and what is not, and expresses the domain knowledge by entering the data,” Ng said. “And I think that is a better recipe for enabling all of the people and all of these different industries to build the custom AI models that they need — and hence the focus on data-centric AI.”
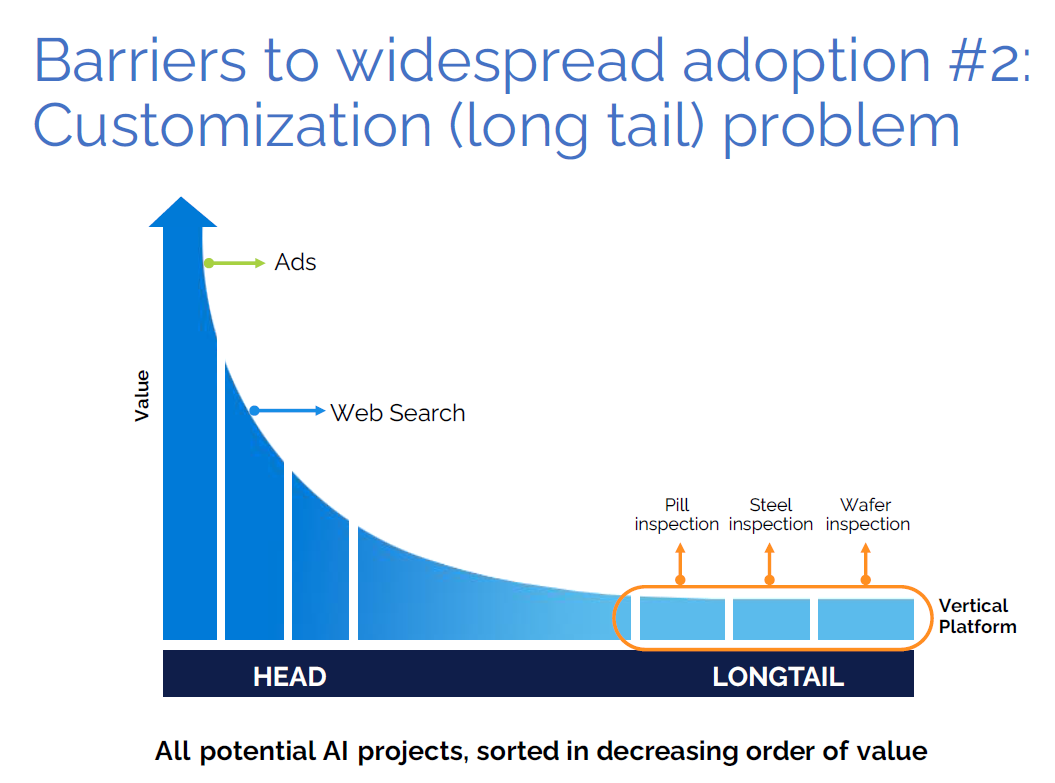
Many AI solutions have yet to be built for the long-tail of problems
Ng demoed how Landing AI’s software can help users to label data more effectively. Having a high-quality set of human-curated data is very important before embarking upon the final bit of training that will turn a generic neural network into a customized AI system. But as it turns out, there are differences in how humans label data, and that is a considerable source of error (or at least variance) that can negatively impact the final AI result.
“It turns out that one of the features that…maybe seems a little bit basic [but] is one of the more useful ones is the defect book, or the label book, which is a very clear articulation of what is a defect and how to label it,” Ng said, referring to a computer vision system designed to detect flaws in pill manufacturing. “This is a document with detailed illustrations that tells labelers and helps labelers align on, if you see two chips, how do you label them? With one bounding box or two boundary boxes?”
What’s the difference between a “scratch” and a “chip”? It may sound like one is arguing semantics here, and in a way it is. But Ng stressed the importance of being consistent during the labeling process.
“When you have a data set with errors in them, inconsistencies or inaccuracies, time spent fixing these errors can be time very well spent for a machine learning team,” he said. “And tools to help you find and fix these errors can be especially productive in terms of improving system performance.”
Data engineering and data science are often considered separate specialties, with different personnel. But Ng encouraged machine learning developers to view data quality as falling well within their domain, especially if they’re following the tenets of data-centric AI.
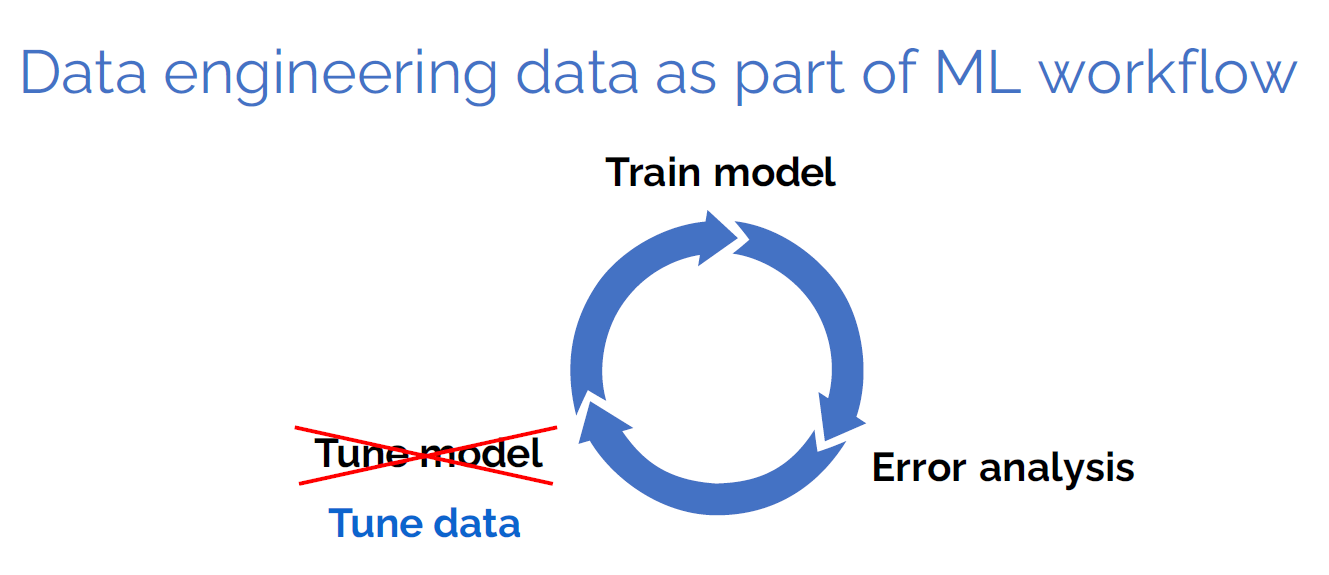
Data-centric AI requires a heavier focus on tuning data rather than tuning models (image courtesy Andrew Ng)
“I hope that we all think of data cleaning no longer as a preprocessing step that you do once before you get to the real machine learning work,” Ng said. “Instead, data cleaning, data preparation, or data improving should be a core part and a core to in how you iteratively improve a machine learning system.”
Ng recalled another session he gave at GTC seven years ago, in which he presented an iterative recipe for improving machine learning performance. It starts with the initial training of the model. If the model performs well on the test data, then you’re done. But if it doesn’t do well on the test set, then Ng encouraged them to go get more data and retrain the model. Eventually, with enough data, you should end up with a system that satisfies the requirements.
“For companies with a lot of data, this recipe works and still continues to work, so don’t stop doing this if you have the resources,” Ng said. “What interests me….is can we also figure out what to do in small data settings?”
According to Ng, it turns out that if you have small data set, and you run through his deep learning recipe, the model will almost always succeed with just a small amount of training data. Why is that?
“Because when your data is small, a modern neural network will often — not always, but often — do well on the training data,” he said, “because a modern [neural] network is…typically a low-bias, high-variance machine, especially when the data set is small.
“So the next question then becomes: Does it do well on the test data?” Ng continued. “And if it doesn’t, well, it’s hard to get more data for certain applications, and I think the shift therefore has to be to get better data, rather than just more data. And tools to help you get better data is exactly the focus of data-centric AI.”
Related Items:
Is Data-First AI the Next Big Thing?
Computer Vision Platform Datagen Raises $50M Series B
Leading Solution Providers

















