


May 23, 2022
Inside the Modern Data Stack

(optimarc/Shutterstock)
If you’ve heard about something called “the modern data stack,” then you’re not alone. Google returns 489 million results for that search, if that’s a measure of anything anymore. While the modern data stack doesn’t seem to be as well-defined as computing stacks of yore, the persistence of the phraseology caused us to do some digging.
In the past, if you said “oh, we run the LAMP stack,” then you could quickly communicate the fact that your company ran its applications on the Linux operating system, the Apache HTTP server, the MySQL database, and the PHP (or Python or Perl) programming language.
The idea behind a modern data stack is similar, but there are a lot more pieces involved. There are tools for data engineers (ETL tools, transformation tools, and pub/sub systems), data analysts (BI tools, data warehouses) and data scientists (AI workbenches, etc.) You could easily add a host of other categories–databases, data catalogs, governance tools, data orchestration, real-time data flow, etc. depending on the audience and the need.
The list can quickly get out of hand. And yet the core idea of the existence of a modern data stack remains wedded to our synapses. We’re forced to admit that data tools of a feather do, indeed, flock together. That seems to be the consensus of the data insiders contacted by Datanami.
“I think for certain companies of a certain size and for certain teams, there are repeatable patterns,” says Satyan Sangani, CEO and co-founder of data catalog and governance provider Alation. “This thing called the modern data stack, where there is a certain set of tools–we’re certainly one of them, where you have repeatability for a use case and you have repeatability around the products that we tend to be used with.”
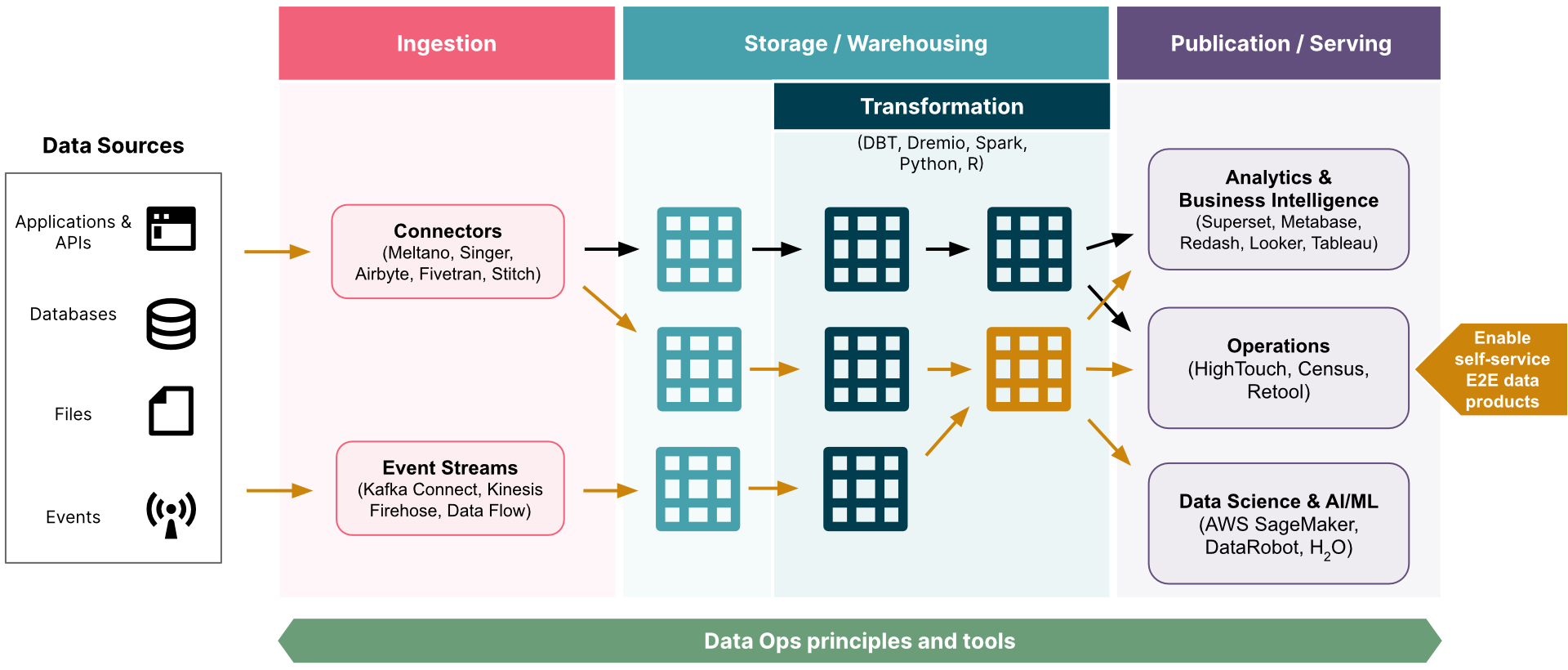
Thoughtworks’ take on the modern data stack
Alation tends to be used with several other products, Sangani says, including Snowflake for the data warehouse, Tableau for the BI tool, and Fivetran for data transformation, or sometimes Informatica.
“There tends to be these patterns for buying analytical tools,” he says. “Companies that have business analysts, the stack that I just mentioned tends to be quite prevalent. In the world of data engineering, you might, for example have a product like a Matillion or you might have a product like Looker.”
There isn’t one modern data stack that’s an end-all, be-all stack for all companies, Sangani says. There are different stacks with different tools for different organizations. If there was just one way to do things, then why do are there five to 10 times more analytical tool companies today than there were 10 years ago? he asks.
“It’s not because everybody is doing the same thing exactly,” he says. “It’s because analytics is basically systematizing human thought, and that’s really hard to do and there’s lots of different ways to do that.”
Jesse Anderson of the Big Data Institute had a front-row seat to the Hadoop battles at Cloudera while it was building one of the first big data stacks. While Hadoop is no longer the elephant in the big data room that it once was, Anderson definitely sees a defined stack emerging that is partly composed of projects that were once included in Hadoop distributions (i.e. “stacks”).
“We’ve got Spark, we’ve got S3 or S3-style buckets for data storage. Very commonly used for pub/sub are technologies like Kafka, Pulsar. We have some relatively standardized things for real-time processing like Flink. And then as we start to go out into the database world, then it really explodes. We have this Cambrian explosion of things. “

Here is an open source modern data stack diagram published by Datafold
One of the defining characteristics of the modern data stack that’s emerging now is the ability to quickly replace old stuff with newer stuff. “Leaders should know that we’re not going to get 20-year lifetimes out of our technology stacks anymore,” Anderson says. “The fact that Hadoop got a 20-year lease on life–we’re not going to see that with other technologies, and I think that’s really key.”
The various components of the modern data stack will have shorter lifetimes before they’re replaced. Figuring out the best way to manage that change will be a big focus of engineers and product developers. “If you have 100 different technologies, and everybody is all using it–it’s an issue for data mesh, quite frankly,” he says.
Maarten Masschelein, CEO and founder of data observability tool provider Soda, sees the modern data stack being held together with a new slate principles.
“How we did things 10 years ago with data was very different,” he says. “For example, modern data stack to me is multi-stakeholder, from very technical to very business-savvy stakeholders, and it works for everyone.”
The ability to govern change, especially in a fast-paced environment, is an important aspect of the tools that make up the modern data stack, Masschelein says. “It has influences from software engineering built into it, so more resilient, faster, and more agile,” he says. “It’s a combination of things that constitutes modern data stack. But I also think that’s a term that in a year from now, we’re going say, ‘Oh yeah, did we say that? Did we use that?’”
Rule number one from ThoughtSpot co-founder and Executive Chairman Ajeet Singh’s list of six new rules for data is to use a best-of-breed product at every layer of the stack. The folks at ThoughtSpot, of course, think their product is the top choice for the data experience layer, where they compete with the likes of PowerBI, Looker, and Tableau.
“We are working with pretty much every best of breed vendor in that modern data stack,” Singh said. “So our strategy is to partner with other best-of-breed partners and make it easier for customer to get the full stack seamlessly.”
Many ThoughtSpot customers at the recent Beyond 2022 show say they’re using ThoughtSpot along with Snowflake or AWS data warehouses or data lakes and Matillion or dbt for ETL or data transformation.
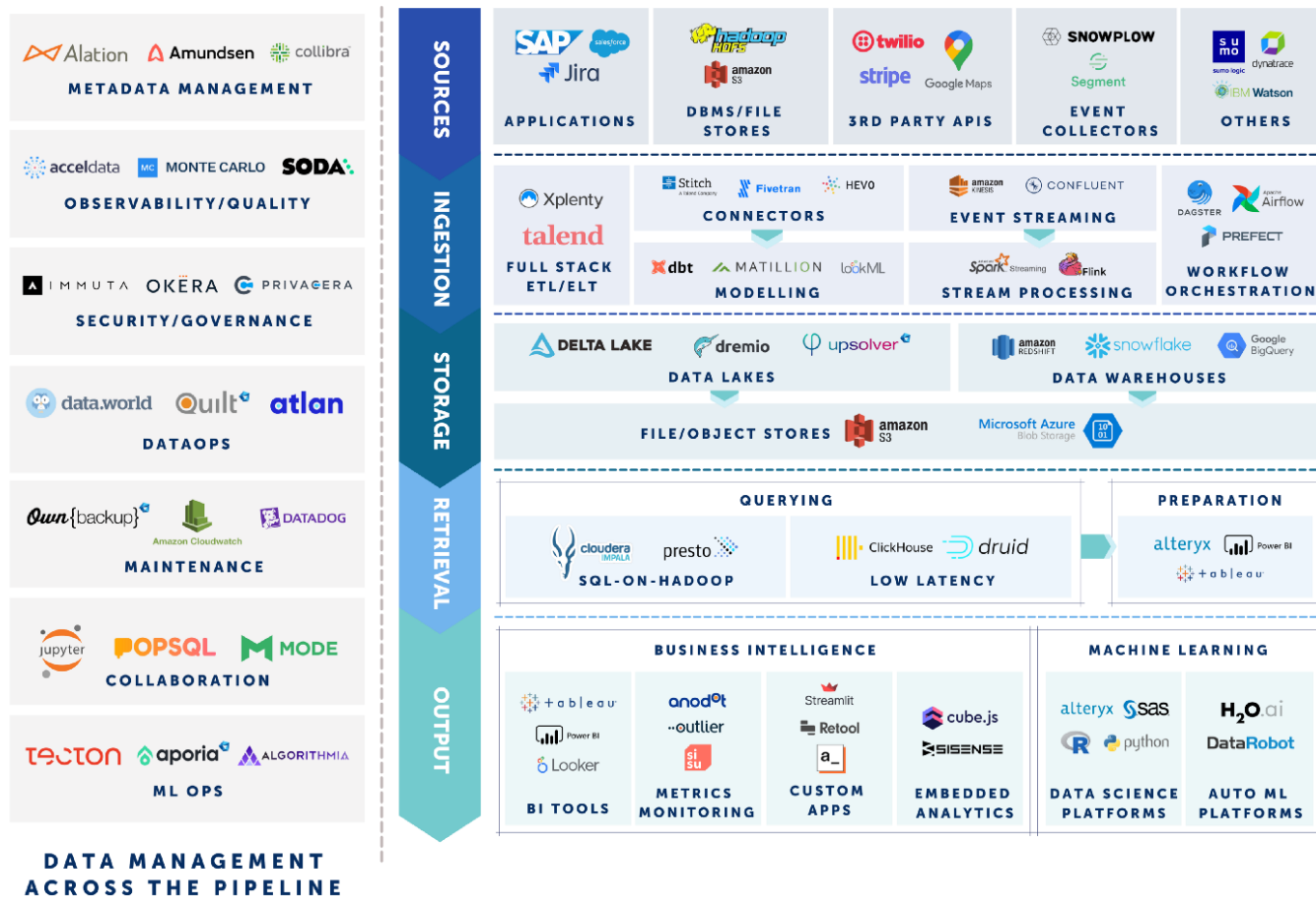
This modern data stack, as depicted by Vertex Ventures, resembles an eye chart
ThoughtSpot follows three core principles when building products to co-exist with others in the modern data stack and the modern data ecosystem, CEO Sudheesh Nair says. The first is the machine-to-machine API experience has to be seamless.
“When Sean [Zinsmeister ThoughtSpot’s SVP of marketing] showed the demo, he clicks once and dbt comes in and search happens,” Nair said at the recent Beyond 2022 conference. “We’re putting in the effort, dbt is putting in the effort to make sure it’s seamless.”
The second principle is that customers must not fall into the integration abyss between two vendors. If there’s a problem, the vendor must communicate to ensure customer concerns are met. Lastly, allowing customers to spend their public cloud credits on your product makes it more likely they’ll buy it, he says.
Lenley Hensarling, chief strategy officer with NoSQL database vendor Aerospike, has a different take on the modern data stack. He sees it as a sort of data fabric, with fast and flexible databases at the edge, ingesting, processing, and moving data on a continuous basis.
“You want to make use of the data in as near a real-time picture you can,” he says. “We see customers over and over again putting us as an augmentation and a real-time data system at the edge, and then filtering those transactions back to where maybe all the regulatory stuff happens, the uninteresting stuff.”
The real time data store must be flexible and fast, and support change data capture and streaming data requirements, Hensarling says.
“What we see is the need for Spark connectors, for Spark SQL, Spark Streaming, for Pulsar, for Kafka, for JMS,” he says. “That provides the fabric that people are building [with a]…new style of program that’s very disaggregated and deconstructed, but works together all the time…. We think that having that complete fabric is a big win.”
What are your thoughts on the modern data fabric? Does it actually exist, or is it a figment of our collective imaginations? Drop us a line if you have an opinion about it.
Related Items:
In Search of the Data Dream Team
In Search of the Modern Data Stack
Editor’s note: An image of a data stack was erroneously attributed to ThoughtSpot. It was created by Thoughtworks. Datanami regrets the error.
Applications:
Enterprise Analytics
Technologies:
Middleware
Sectors:
Other
Vendors:
Aerospike, Alation, AWS, Big Data Institute, Cloudera, dbt, Fivetran, Informatica, looker, Matillion, Soda, Tableau, ThoughtSpot
Leading Solution Providers

















