


August 31, 2022
New C++ Acceleration Library Velox Juices Code Execution Up To 8x

Momentum is building around Velox, a new C++ acceleration library that can deliver a 2x to 8x speedup for computational engines like Presto, Spark, and PyTorch, and likely others in the future. The open source technology was originally developed by Meta, which today submitted a paper on Velox to the International Conference on Very Large Data Bases (VLDB) taking place in Australia.
Meta developed Velox to standardize the computational engines that underly some of its data management systems. Instead of developing new engines for each new transaction processing, OLAP, stream processing, or machine learning endeavor–which require extensive resources to maintain, evolve, and optimize–Velox can cut through that complexity by providing a single system, which simplifies maintenance and provides a more consistent experience to data uses, Meta says.
“Velox provides reusable, extensible, high-performance, and dialect-agnostic data processing components for building execution engines, and enhancing data management systems,” Facebook engineer Pedro Pedreira, the principal behind Velox, wrote in the introduction for the Velox paper submitted today at the VLDB conference. “The library heavily relies on vectorization and adaptivity, and is designed from the ground up to support efficient computation over complex data types due to their ubiquity in modern workloads.”
Based on its own success with Velox, Meta brought other companies, including Ahana, Voltron Data, and ByteDance, to assist with the software’s development. Intel is also involved, as Velox is designed to run on X86 systems.
The hope is that, as more data companies and professionals learn about Velox and join the community, that Velox will eventually become a regular component in the big data stack, says Ahana CEO Stephen Mih.
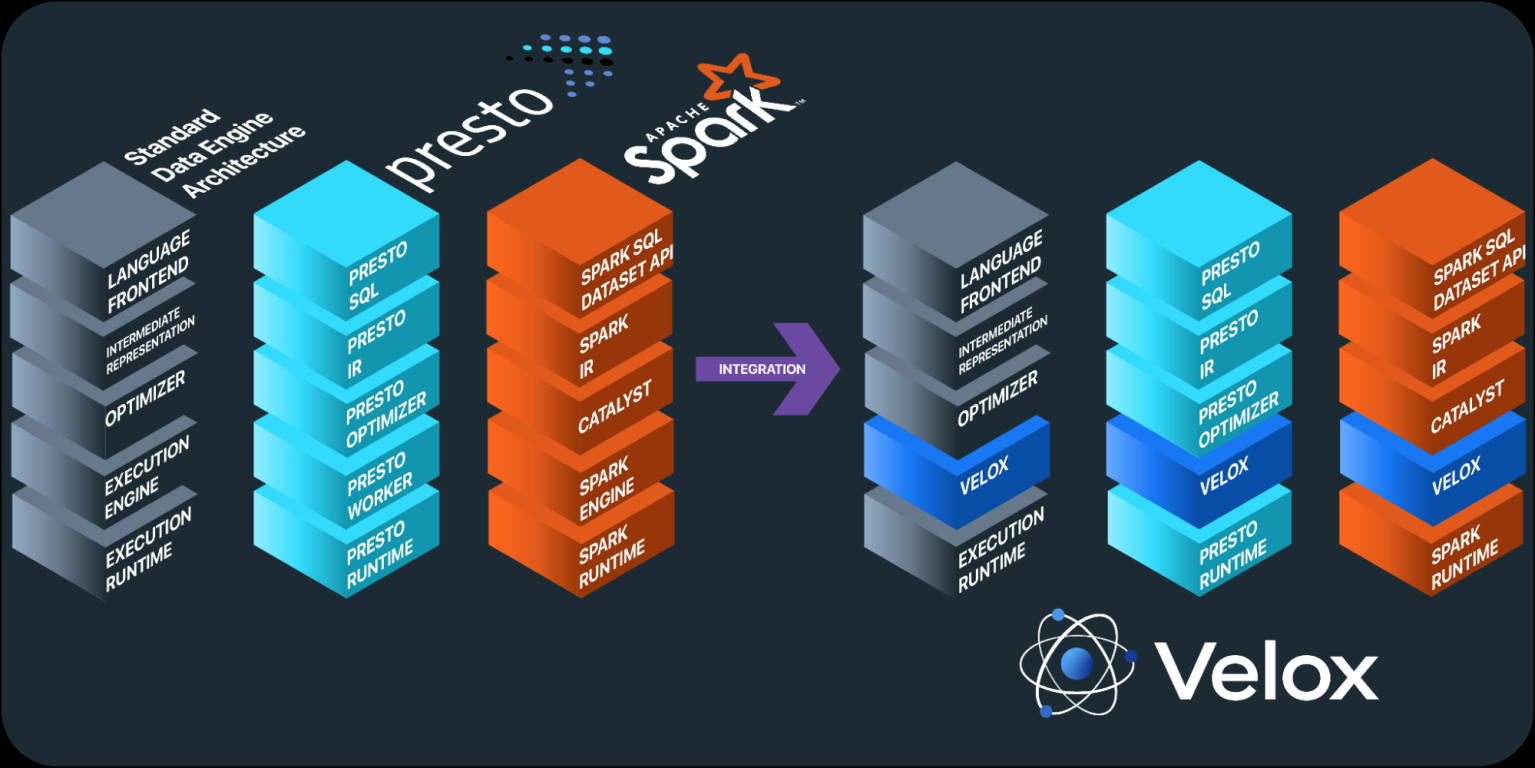
Velox can standardize an important part of the big data computational stack (Image courtesy Meta)
“Velox is a major way to improve your efficiency and your performance,” Mih says. “There will be more compute engines that start using it….We’re looking to draw more database developers to this product. The more we can improve this, the more it lifts the whole industry.”
Mih shared some TPC-H benchmark figures that show the type of performance boost users can expect from Velox. When Velox replaced a Java library for specific queries, the wall clock time was reduced anywhere from 2x to 8x, while the CPU time dropped between 2x and 6x.
They key advantage that Velox brings is vectorized code execution, which is the ability to process more pieces of code in parallel. Java does not support vectorization, whereas C++ does, which makes many Java-based products potential candidates for Velox.
Mih compared Velox to what Databricks has done with Photon, which is a C++ optimization layer developed to speed Spark SQL processing. However, unlike Photon, Velox is open source, which he says will boost adoption.
“Usually, you don’t get this type of technology in open source, and it’s never been reusable,” Mih tells Datanami. “So this can be composed behind database management systems that have to rebuild this all the time.”![]()
Over time, Velox could be adapted to run with more data computation engines, which will not only improve performance and usability, but lower maintenance costs, writes Pedreira and two other Facebook engineers, Masha Basmanova and Orri Erling, in a blog post today.
“Velox unifies the common data-intensive components of data computation engines while still being extensible and adaptable to different computation engines,” the authors write. “It democratizes optimizations that were previously implemented only in individual engines, providing a framework in which consistent semantics can be implemented. This reduces work duplication, promotes reusability, and improves overall efficiency and consistency.”
Velox uses Apache Arrow, the in-memory columnar data format designed to enhance and speed up the sharing of data among different execution engines. Wes McKinney, the CTO and co-founder of Voltron Data and the creator of Apache Arrow, is also committed to working with Meta and the Velox and Arrow communities.
“Velox is a C++ vectorized database acceleration library providing optimized columnar processing, decoupling SQL or data frame front end, query optimizer, or storage backend,” McKinney wrote in a blog post today. “Velox has been designed to integrate with Arrow-based systems. “Through our collaboration, we intend to improve interoperability while refining the overall developer experience and usability, particularly support for Python development.”
These are still early days for Velox, and it’s likely that more vendors and professionals will join the group. Governance and transparency are important aspects to any open source project, according to Mih. While Velox is licensed with an Apache 2.0 license, it has not yet selected an open source foundation to oversee its work, Mih says.
Related Items:
Ahana Launches ‘Forever Free’ Presto Service, Series A Top-Off
Databricks Scores ACM SIGMOD Awards for Spark and Photon
Voltron Data Takes Flight to Unify Arrow Community
Editor’s note: This article has been corrected. Wes McKinney is the CTO and co-founder of Voltron Data, not the CEO. Datanami regrets the error.
Technologies:
Frameworks
Leading Solution Providers

















