

October 3, 2022
Quine Streaming Graph Processes Over One Million Events Per Second

(3dkombinat/Shutterstock)
Quine, a real-time graph data processing engine for ETL pipelines, has reached a performance benchmark of processing one million events per second, according to its maker, thatDot.
Named after logician Willard Van Orman Quine, the Quine streaming graph engine is an Akka-based distributed framework that combines complex pattern matching with real-time stream processing for building scalable complex event processing workflows.
According to thatDot, the benchmark results show that Quine can process over one million simultaneous writes and also execute the equivalent of over one million four-node graph queries simultaneously. Quine says this is a significant milestone because most graphs top out around thousands of events per second or less. While other graphs have proven valuable for connecting and finding complex patterns in categorical data, or non-numerical data, they are often too slow for high-volume, real-time processing.
“The challenge has always been that graphs are slow,” thatDot Founder and CEO Ryan Wright previously told Datanami’s Alex Woodie. “If you have kind of the typical streaming problem of a high write and read workload–so you’re not just writing it to disk, you’ve got to write it and read it back so you can use stream processing on it–then [a graph database] just slows to a crawl and goes from several thousands of events per second that they can usually reach down to like 1,000 a second.”

Quine’s overall ingest rate. Source: thatDot
Wright developed Quine using Akka, a developer toolkit that employs the actor model of concurrent computation in which an actor is a lightweight computing engine with its own CPU thread. The actor encapsulates one state of data and can interact with multiple actors in an asynchronous and highly scalable manner. As events stream in, each gets fed to a user-written Cypher query that creates sub-graphs for each one, called a standing query. Standing queries live inside the graph and wait for matching events to occur. According to thatDot, they monitor streams for specified patterns while maintaining partial matches and executing user-specified actions as soon as a full match is made. These actions can include updating the graph itself by creating new nodes or edges or writing results out to Kafka or Kinesis.
The company stated the goal of its benchmark test was to demonstrate a high volume of sustained ingest that is resilient to cluster node failure in both Quine and an Apache Cassandra persistor using commodity infrastructure. “In this test, Quine standing queries monitored for specific 4-node patterns requiring a 4-node traversal every time an event was ingested. Traditional graph databases slow down ingest when performing multi-node traversal. Not Quine,” said Wright in a blog post discussing the benchmark results. “Quine’s ability to sustain high-speed data ingest together with simultaneous graph analysis is a revolutionary new capability. Not only did Quine ingest more than 1,000,000 events per second, it analyzed all that data in real-time to find more than 20,000 matches per second for complex graph patterns. This is a whole new world!”
![]() Launched earlier this year, Quine is available under both open source and enterprise licenses. ThatDot says Quine snaps into existing data pipelines, consuming from and publishing to Kafka and Kinesis instances. Use cases include financial and credential fraud prevention, insider trading prevention, XDR/EDR, real-time asset graphs, cloud infrastructure monitoring, and network observability.
Launched earlier this year, Quine is available under both open source and enterprise licenses. ThatDot says Quine snaps into existing data pipelines, consuming from and publishing to Kafka and Kinesis instances. Use cases include financial and credential fraud prevention, insider trading prevention, XDR/EDR, real-time asset graphs, cloud infrastructure monitoring, and network observability.
ThatDot has published the results and actual test code on GitHub to benefit the developer community by allowing for customizable reproduction of the benchmarks.
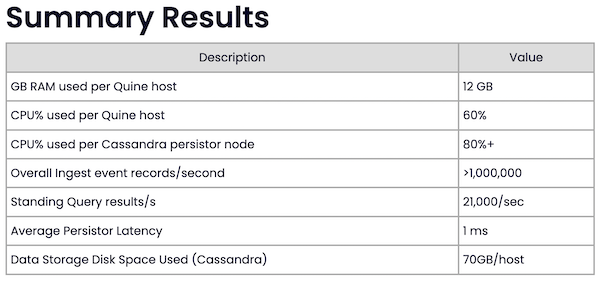
A summary of Quine’s benchmark results. Source: thatDot
“Quine is not just a game changer for graph data workloads, but for event stream processing as well, and the breakthrough of over 1 million events per second is significant for our users,” said Wright. “Quine’s ability to find deep insights in vast amounts of fast-moving data, and to do so on commodity hardware, without months or years of custom development, transforms the data processing landscape.”
“What thatDot has achieved with Quine is impressive, and it’s not surprising that they’ve achieved it using Apache Cassandra as the backend database,” said Vikram Bhambri, vice president of product management at DataStax. “The ability to process graph workloads at the scale and with the reliability Cassandra users expect can open up a new category of real-time use cases.”
To read the full details of Quine’s benchmark tests, visit Wright’s blog post.
Related Items:
Can Streaming Graphs Clean Up the Data Pipeline Mess?
Leading Solution Providers

















