


December 21, 2022
Fivetran Benchmarks Five Cloud Data Warehouses

(Dilok Klaisataporn/Shutterstock)
ETL software maker Fivetran this week released results of a benchmark test it ran comparing the cost and performance of five cloud data warehouses, including BigQuery, Databricks, Redshift, Snowflake, and Synapse. The big takeaway is that all of the cloud warehouses perform well, but some are easier to use and tune than others.
As an ETL vendor, Fivetran often gets asked by customers which cloud data warehouse they should use, writes CEO George Fraser in a blog post Monday. To find out which warehouse was best, the company decided to do an apples-to-apples comparison (or at least as close to one as possible).
To conduct the test, Fivetran partnered with Brooklyn Data Co., a data and analytics consultancy. They used the TPC-DS data set, which is a decision support benchmark rolled out by the Transaction Processing Performance Council in 2015 that depicts data from an imaginary retailer. The database included 1TB of data, which is the smallest scale factor authorized by TPC-DS (it’s also available in 3TB, 10TB, 30TB, and 100TB scale factors).
Fivetran and Brooklyn Data Co. configured each data warehouse three different ways to account for differences in cost and performance. The lone exception was Google Cloud’s BigQuery, which can’t be configured because it’s only available as an on-demand service. While it ran AWS’s Amazon Redshift in three configurations, the partners only reported the results of one because they were not able to reproduce results across different configurations, they wrote.
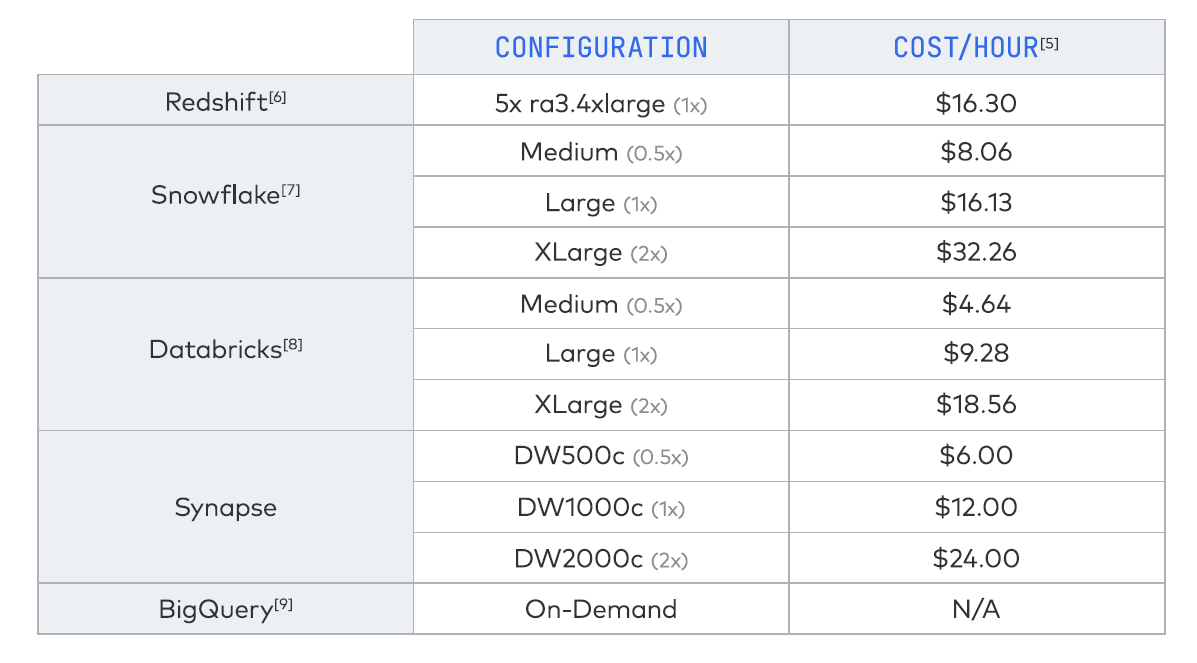
The configurations of the five warehouses (Source: Fivetran Cloud Data Warehouse Benchmark)
The partners then ran 99 TPC-DS queries against the retail database, and calculated how long it took each to run. These queries were “complex,” Fivetran said, with lots of joins, aggregations, and subqueries. Each query was run only once, to prevent the database from caching the results.
The results of the tests show that all five warehouses are fairly equal in terms of performance and cost, with a definite cluster of warehouse results appearing on the cost vs time graph. “All warehouses had excellent execution speed, suitable for ad hoc, interactive querying,” Fivetran wrote in its report.
Snowflake achieved the fastest average query execution time with the 2X configuration (an XLarge instance running on AWS), with a geomean time of about 5 seconds per query. However, at a cost of $32.26 per hour, Snowflake 2X was also the most expensive setup.
The single Amazon Redshift result, in a 1X configuration running on a 5x ra3.4xlarge AWS instance, sat right in the middle of the pack, with a $16.30 cost per hour. Redshift’s benchmark result was just a hair slower and a couple cents more expensive than Snowflake’s 1X instance.
Databricks achieved the lowest cost per hour, $4.64, with the 0.5x configuration, which ran on a Medium instance on AWS. With a geomean time of about 8 seconds per query, Databricks’ 2X configuration was a tad slower than Snowflake’s 2X configuration, at roughly the same cost per query. Its 1X configuration was a smidge slower than AWS’s, but significantly cheaper than either Snowflake’s or AWS’s 1X result.
However, these results may change. “We have been made aware of several issues with our Databricks results, and we are currently re-running that portion of the benchmark,” Fivetran CEO Fraser stated in the blog on Tuesday.
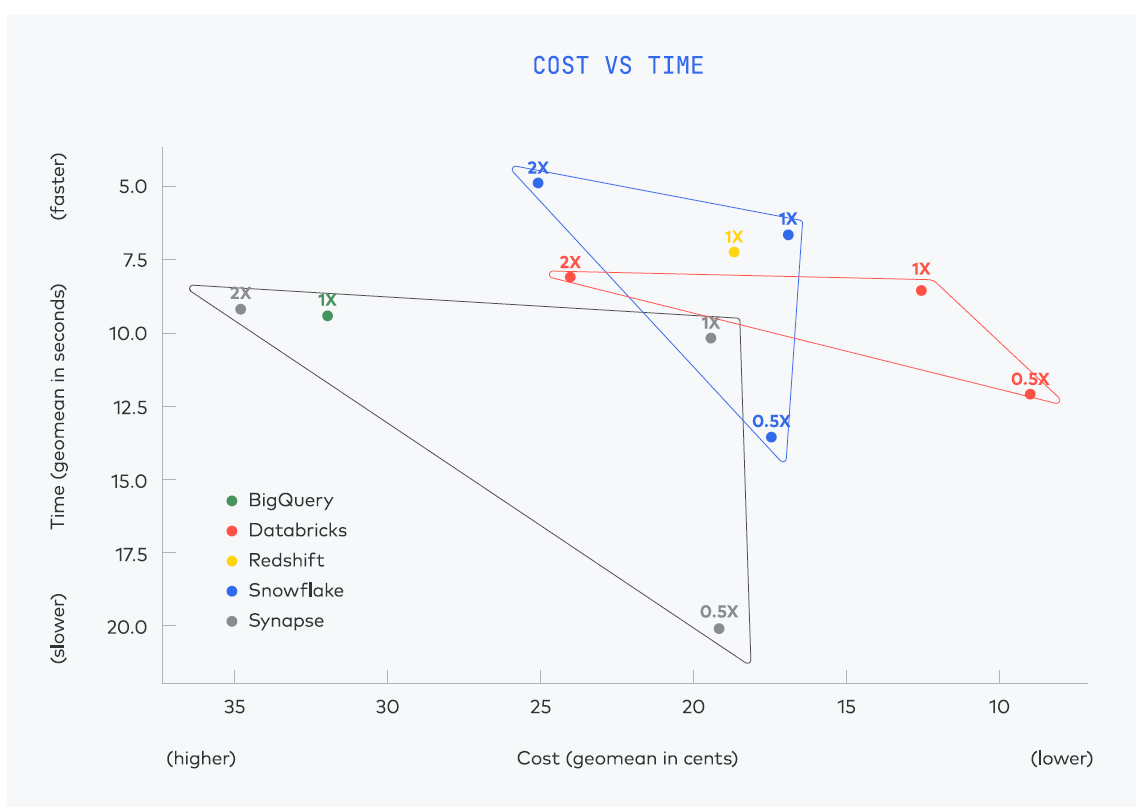
The results of the benchmark (Source: Fivetran Cloud Data Warehouse Benchmark)
The three results for Microsoft Azure Synapse showed the biggest variety when plotted on the cost vs. time graph. The Synapse 1X result was fairly close to the 1X results for Snowflake, Databricks, and AWS. But its 2X result (configured as DW2000c, or occupying 2000 data warehouse units in Azure) generated only marginal improvements in speed, while costing nearly twice as much (although it still was cheaper than Snowflake’s 2X result when computed using Fivetran’s “cost per hour” metric).
BigQuery was the odd man out, both in terms of the results and configuration (since it’s only available as an on-demand offering). The 1X configuration that Fivetran and Brooklyn Data Co. used for BigQuery generated suitable performance, coming in around 9 geomean seconds per query, which was right in the middle of the pack (Synapse 1X was slightly slower). But with a geomean cost of about $0.32 per query, BigQuery in the sole 1X configuration was more expensive than every other data warehouse, except for Synapse (with a geomean of about $0.35 per query).
Comparing BigQuery pricing to the others was the trickiest part of this entire benchmark, Fivetran told Datanami. “BigQuery has a unique pay-per-query pricing model. In order to compare BigQuery to other systems, we have to make assumptions about how well-matched a typical customer’s workload is to a typical customers data warehouse,” a company spokesperson wrote via email. “Under the assumptions that we made, BigQuery is somewhat more expensive. However, the BigQuery pay-per-query model means that BigQuery customers never have any wasted capacity, so under some circumstances BigQuery will be cheaper.”
Four of the data warehouses have made significant improvements since the last time Fivetran ran this benchmark, which was back in 2020 (Azure Synapse being the lone data warehouse that Fivetran did not test in 2020). But Databricks logged the biggest improvement, “which is not surprising since they completely rewrote their SQL execution engine,” Fivetran wrote in the report.
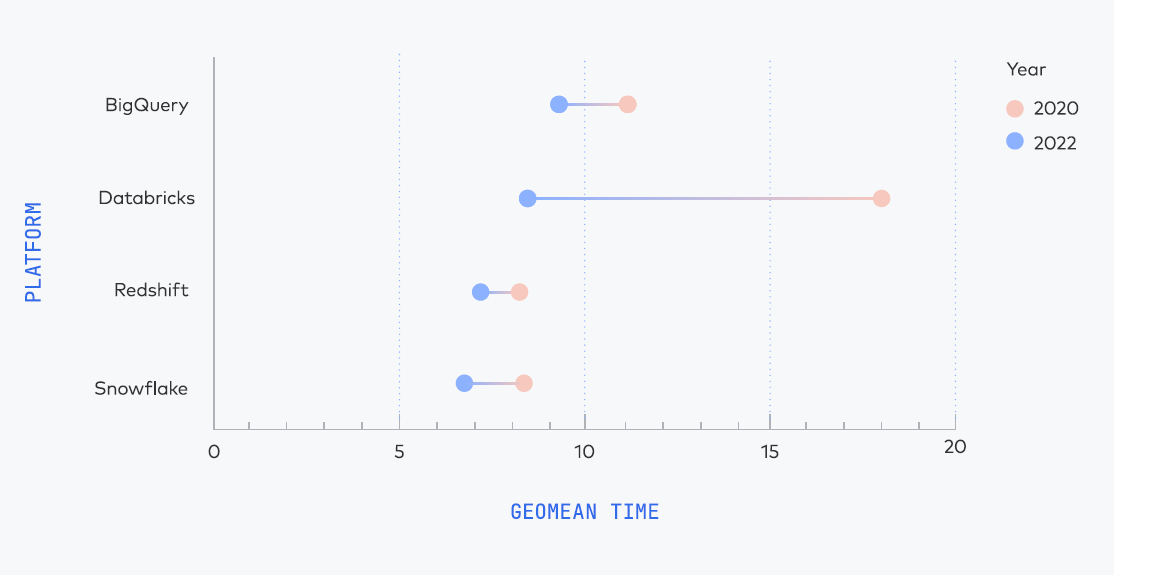
Four data warehouses showed big improvement compared to Fivetran’s previous benchmark (Source: Fivetran Cloud Data Warehouse Benchmark)
It’s worth noting that Fivetran did not do a lot of the things that users would normally do to squeeze the most performance from their cloud data warehouse. For instance, it didn’t use sort keys, clustering keys, or date partitioning.
“If you know what kind of queries are going to run in your warehouse, you can use these features to tune your tables and make specific queries much faster,” the company said in its report. “However, typical Fivetran users run all kinds of unpredictable queries on their warehouses, so there will always be a lot of queries that don’t benefit from tuning.”
However, it did use some performance-boosting features. It used column compression encodings in Redshift and column store indexing in Synapse. It did this to get a balanced look at performance for these data warehouses, since Snowflake, Databricks, and BigQuery apply compression automatically, the company says.
In its report, Fivetran provided an interesting history of other TPC-DS benchmarks, including some run by vendors.
It noted that a November 2021 Databricks TPC-DS run, which formed the basis for its claim that its warehouse was 2.7x faster and 12x cheaper than Snowflake’s. For instance, Databricks ran used the 100TB data set, rather than the 1TB set. It also used a 4XL endpoint, which Fivetran used the L configuration. Databricks also tuned some tables using timestamp-partitioning, customized the number of partitions, and ran the “analyze” command immediately after loading to update column statistics. It also reported its results in total runtime, which reflects the time of the longest-running queries, whereas Fivetran used a geomean, which gave equal weight to all queries.
“Databricks published the code to reproduce their benchmark on the TPC-DS website, which is very helpful for understanding the difference,” Fivetran noted. “It would be great if they would also publish the code they used for their Snowflake comparison, in particular it would be interesting to see if they used timestamp-partitioning in Snowflake.”

Performance among all cloud data warehouses are comparable (ramcreations/Shutterstock)
Gigaom, sponsored by Microsoft, ran a benchmark in 2019 that pitted BigQuery, Redshift, Snowflake, and Azure SQL Data Warehouse (as Synapse was called then). They used the 30TB data set and used much bigger systems than Fivetran did, but the results were slower than what Fivetran was able to accomplish.
“It’s strange that they observed such slow performance, given that their clusters were 5-10x larger but their data was only 3x larger than ours,” Fivetran wrote.
An October 2016 Amazon compared RedShift with BigQuery, and concluded (perhaps not surprisingly) that Redshift was 6x faster and that BigQuery execution times often exceeded one minute per query.
“Benchmarks from vendors that claim their own product is the best should be taken with a grain of salt,” Fivetran wrote. “There are many details not specified in Amazon’s blog post. For example, they used a huge Redshift cluster–did they allocate all memory to a single user to make this benchmark complete super-fast, even though that’s not a realistic configuration? We don’t know. It would be great if AWS would publish the code necessary to reproduce their benchmark, so we could evaluate how realistic it is.”
All cloud data warehouses can run the easy queries fast, but that’s not that helpful, since most real-world queries are complex. What matters most in the end, Fivetran says, is whether the warehouses can run the difficult, real-world queries in a reasonable amount of time.
Even with this goal, it’s tough to highlight any of the warehouses as much better than the others, or to find fault with any of them for being slow.
“These warehouses all have excellent price and performance,” Fivetran concludes. “We shouldn’t be surprised that they are similar: The basic techniques for making a fast columnar data warehouse have been well-known since the C-Store paper was published in 2005. These data warehouses undoubtedly use the standard performance tricks: columnar storage, cost-based query planning, pipelined execution and just-in-time compilation. We should be skeptical of any benchmark claiming one data warehouse is dramatically faster than another.”
The most important differences between cloud data warehouses, Fivetran says, are the “qualitative differences caused by their design choices: Some warehouses emphasize tunability, others ease of use. If you’re evaluating data warehouses, you should demo multiple systems, and choose the one that strikes the right balance for you.”
When it comes to ease of use, BigQuery and Snowflake excel over the others, Fivetran says. Databricks and Redshift, meanwhile, are more tuneable, the company says.
You can access Fivetran’s data warehouse benchmark here.
Related Items:
Databricks Claims 30x Advantage in the Lakehouse, But Does It Hold Water?
Oracle Announces New ML Capabilities for MySQL HeatWave
New TPC Benchmark Puts an End to Tall SQL-on-Hadoop Tales
Leading Solution Providers

















